综合练习:请给openlab搭建web网站
网站需求:
1.基于域名[www.openlab.com](http://www.openlab.com)可以访问网站内容为 welcome to openlab!!!
2.给该公司创建三个子界面分别显示学生信息,教学资料和缴费网站,基于[www.openlab.com/student](http://www.openlab.com/student) 网站访问学生信息,[www.openlab.com/data](http://www.openlab.com/data)网站访问教学资料
[www.openlab.com/money网站访问缴费网站](http://www.openlab.com/money网站访问缴费网站)。
3.要求
(1)学生信息网站只有song和tian两人可以访问,其他用户不能访问。
(2)访问缴费网站实现数据加密基于https访问。
题目解析步骤: 准备工作 [root@server ~]# systemctl stop firewalld
[root@server ~]# setenforce 0
[root@server ~]# yum install httpd -y (如果之前没有永久挂载需要挂载后安装软件包)
编辑访问文件(域名解析,客户端在那个上验证,就写在那个主机上) [root@server ~]# vim /etc/hosts
192.168.145.128 www.openlab.com
[root@server ~]# ping www.openlab.com
编辑配置文件 [root@server ~]# vim /etc/httpd/conf.d/li.conf
<VirtualHost 192.168.145.128:80>
DocumentRoot /www/openlab
ServerName www.openlab.com
</VirtualHost>
<Directory /www>
AllowOverride none
Require all granted
</Directory>
创建网站存储文件 [root@server ~]# mkdir /www/openlab -pv
文件中写上需要内容 [root@server ~]# echo 'welcome to openlab!!!' > /www/openlab/index.
5.0 中文翻译 I 官网文档:https://www.energystar.gov/products/spec/computer_specification_version_5_0_pd
1. 承诺 以下是与制造符合ENERGY STAR标准计算机有关的ENERGY STAR合作伙伴协议条款。ENERGY STAR合作伙伴必须遵守以下计划要求:
遵守当前的ENERGY STAR资格标准,定义了ENERGY STAR认证标记在计算机上使用的性能标准,并指定了计算机的测试标准。EPA(美国环境保护局Environmental Protection Agency)可自行决定对被称为ENERGY STAR合格的产品进行测试。这些产品可以在开放市场上获取,或在EPA的要求下由合作伙伴自愿提供。遵守当前的ENERGY STAR品牌指南,描述ENERGY STAR标记和名称的使用方式。合作伙伴负责遵守这些指南,并确保其授权代表(例如广告代理商、经销商和分销商)也遵守这些指南。与合作伙伴产品的转售商合作,以确保这些产品保持符合ENERGY STAR的要求。在ENERGY STAR合格的计算机产品的分销渠道中,任何一方在产品制造日期之后通过硬件或软件修改改变产品的功率配置的,必须确保产品在交付给最终客户之前仍然符合ENERGY STAR的要求。如果产品不再符合要求,它就不能带有ENERGY STAR标记。在激活计算机协议部分后的一年内,至少通过认证一个符合ENERGY STAR标准的计算机型号。当合作伙伴获得产品认证时,它必须符合当时有效的规范(例如一级或二级)。提供清晰且一致的ENERGY STAR合格计算机标签。ENERGY STAR标记必须清晰地显示在以下位置之一: 产品的顶部或正面。产品的顶部或正面标识可以是永久或临时的。所有临时标识必须通过黏合或吸附类型的应用程序粘贴到产品的顶部或正面。
电子标签选项:制造商可以选择使用替代的电子标签方法来代替该产品标签要求,只要它符合以下要求: ENERGY STAR标记以青色、黑色或白色(在“ENERGY STAR品牌指南”中描述,可在www.energystar.gov/logos上获得)出现在系统启动时。电子标记必须显示至少5秒钟;ENERGY STAR标记的面积必须至少占屏幕的10%,不得小于76像素 x 78像素,并且必须易读。
EPA将在个案基础上考虑有关电子标签的方法、持续时间或大小的替代提案。 在产品文献中(例如用户手册、规格说明等);在零售产品包装上;在制造商的互联网站上,展示符合ENERGY STAR资格的型号的信息: 如果在合作伙伴网站上提供有关ENERGY STAR的信息,应按照ENERGY STAR Web链接政策(该文件可在ENERGY STAR网站的合作伙伴资源部分找到www.energystar.gov),EPA可能会提供适当的链接到合作伙伴网站; 同意完成以下步骤,向其产品的用户介绍电源管理的优点,除了ENERGY STAR资格标准(第3.C节)中所述的用户信息要求之外,在每台计算机上(即在用户手册或盒装说明中)包括以下信息: 节能潜力;财务节省潜力;环境效益;有关ENERGY STAR的信息和www.energystar.gov的链接;ENERGY STAR标志(按照“ENERGY STAR品牌指南”(可在www.energystar.gov/logos上找到)的规定使用)。
此外,应在计算机产品页面、产品规格和相关内容页面提供www.energystar.gov/powermanagement的链接。
在制造商的请求下,EPA将提供与上述标准、模板元素或适用于用户指南或盒装说明的完整模板相关的建议事实和数据。 每年至少向EPA提供更新后的ENERGY STAR合格计算机型号清单。一旦合作伙伴提交其首个ENERGY STAR合格计算机型号清单,合作伙伴将被列为ENERGY STAR合作伙伴。为了保持参与产品制造商名单上的位置,合作伙伴必须每年至少提供一次更新。每年向EPA提供出货量数据或其他市场指标,以帮助确定ENERGY STAR在市场上的渗透率。具体而言,合作伙伴必须提交ENERGY STAR合格计算机的总出货量(按型号计算的单位)或EPA和合作伙伴事先商定的等效测量。合作伙伴还应该提供按有意义的产品特征(例如容量、大小、速度或其他相关特征)分段的ENERGY STAR合格出货量数据,其产品线中每个型号的总出货量以及符合ENERGY STAR的总出货量占总出货量的百分比。每个日历年的数据应该在次年3月之前提交给EPA,最好是以电子格式提交,并且可以直接从合作伙伴或通过第三方提供。这些数据仅用于计划评估目的,并将受到严格控制。EPA将对使用的任何信息进行掩盖,以保护合作伙伴的机密性。合作伙伴还需:在30天内向EPA通报计算机指定的责任方或联系人的变更;参加ENERGY STAR验证测试计划。EPA每年将选择计算机进行验证测试。每个所选产品的制造商将需要按照验证测试指南和程序手册中概述的规定,对指定的产品进行测试。这些要求将自版本5.0开始生效,并且可能会在官方规格修订过程之外进行修改和更新。该计划的手册可在ENERGY STAR网站上的ENERGY STAR办公设备合作伙伴资源页面上找到。如果样品未达到ENERGY STAR规格的性能要求,则将根据EPA的产品故障和争议协议进行处理,如适用,则会执行产品摘牌程序。 2. 为特殊荣誉的表现 为了获得来自EPA对其在合作伙伴关系中所做努力的额外认可和/或支持,ENERGY STAR合作伙伴可以考虑以下自愿措施,并应向EPA报告这些努力的进展:
• 考虑公司设施的能源效率改进,并追求建筑的ENERGY STAR标志;
• 购买ENERGY STAR合格产品。修改公司采购或采购规格以包括ENERGY STAR。向EPA提供采购官员的联系信息以进行定期更新和协调。将一般的ENERGY STAR合格产品信息传播给员工,以便在为家庭购买产品时使用;
windows11系统新手保姆级U盘安装教程 U盘--系统盘制作安装windows11 U盘–系统盘制作 打开官方网址:https://www.microsoft.com/zh-cn/software-download/windows11选择我们所需要的软件下载
3.下载完毕,直接双击打开运行
需要等待几秒之后,才会出现安装页面 4.在弹出的页面中选择接受
5. 取消选择“对这台电脑使用推荐的选项”,在版本的下列列表选择windows11 家庭中文版,点击下一页
6. 选择U盘,点击下一页,等待U盘格式化,并自动下载iso文件,下载完毕,系统盘就制作好了
安装windows11 可自行百度自己笔记本电脑进入bios页面的快捷键,以联想笔记本为例
将电脑关机之后,按住Fn键,启动电源,出现BIOS页面,选中 Boot Menu,回车
选择USB启动项
如果选择USB启动项无法进入,可能是在BIOS页面中没有,将USB Boot enable
重复步骤1,选择BIOS setup
选择Boot -> USB Boot
进入windows安装页面,选中下一页,以下都是傻瓜式操作
选中,下一页
选择自定义安装
选择你想要安装的驱动器分区
之后等待安装程序结束,重启,就安装成功了
在步骤7可能有的人会遇到无法在驱动器安装(含泪,本博主刚开始作为新手时也遇到过,不过不用怕,毕竟我还是有点知识在身上的)
可以通过命令方法,转换磁盘格式
1、在当前安装界面按住Shift+F10调出命令提示符窗口;
2、输入“diskpart”,按回车执行,进入DISKPART命令模式;
3、输入“list disk”回车,列出当前磁盘信息;
4、输入“select disk 0”回车,选中磁盘0;
5、输入“clean”,删除磁盘分区;
6、输入“convert mbr”,回车,将磁盘转换为MBR,或者,输入“convert gpt”将磁盘转换为GPT;
7、输入“exit”,回车,退出DISKPART命令模式,再次输入“exit”,回车,退出命令提示符,返回安装界面继续安装系统。
imarkdown imarkdown是一个轻量级markdown图片链接转换器,你可以轻松地对图片链接进行本地到图片服务器、图片服务器到本地、图片服务器到图片服务器的转换。 因为语雀转markdown的时候图片存在防外链行为,如果想要把转出的markdown发表在其他平台,就需要把markdown中所有的图片地址改成本地图片地址或者自定义的图片服务器地址,才可以让别人正常查看。该项目旨在解决这个问题,提供了一个可以批量转换markdown中的图片链接转换器,并支持一些复杂场景下的定制化转换功能。
功能 批量下载:对于markdown中的图片引用,imarkdown可以批量下载markdown中所有的图片到本地多种转换方式: 对于markdown中的图片链接,支持本地转图床、web url转本地、web url转图床等多种转换方式批量转换:支持单、多文件的批量转换,以及生成文件的格式化重命名等操作高度自定义: 只需要继承一个MdAdapter,就可以轻松实现自定义图床的url转换图床适配: 当前暂时只支持阿里云图床,欢迎pr提供更多类型图床 适用人群 有批量转换markdown图片链接url的需求的人对于语雀导出markdown的用户,需要对图片外链进行转换的人需要开发第三扩展应用的人 技术架构 imarkdown采用模块化设计,对于每一个组件,你都可以方便地进行扩展,下图简单展示了imarkdown的技术架构,imarkdown由以下几个部分组成:
MdImageConverter Image图片转换器,负责转换markdown的图片地址并生成新的markdown文件。MdAdapter Md适配器,Image需要转换成的类型,如LocalFileAdapter本地适配器、AliyunAdapter阿里云oss适配器,CustomAdapter自定义适配器,通过将适配器注入MdImageConverter,可以定义将Image转换成什么类型的地址。MdMedium 包括MdFile和MdFolder,封装了一些特性,用于传入MdImageConverter进行数据转换。 imarkdown执行过程大致如下所示,在MdImageConverter执行convert方法后,imarkdown会根据传入的MdMedium构建一个虚拟MdTree,根据此树将文件进行批量图片url转换生成。
快速上手 该项目基于Python进行开发,使用Pypi进行发包,用户可以直接通过pip的方式轻松使用imarkdown。下面将会讲解imarkdown的几种使用场景以及使用方式。
第三方包安装,打开终端命令行,运行如下命令。 pip install -U imarkdown 示例
web url转本地地址web-url转图床多文件转换 web-url转本地多文件转换 本地转图床多文件转换 本地转图床 web url转本地地址 如果你的markdown文件里面的图片是其他网站的web url链接,而你想要将其批量下载到本地,并将markdown中的图片地址转换为本地图片地址,下面的示例将会解决你的问题。
假设你需要转换的文件为test.md,内容如下:
下面的示例如果初始markdown文件为web url,则都将基于该文档进行转换,下面不重复给出。
## 6.3 md图片地址转换 以下只支持本地传到图床 - [https://github.com/JyHu/useful_script.git](https://github.com/JyHu/useful_script.git) - [https://github.com/JyHu/useful_script/blob/](https://github.com/JyHu/useful_script/blob/master/Scripts/md%E6%96%87%E4%BB%B6%E5%9B%BE%E7%89%87%E5%9B%BE%E5%BA%8A%E8%BD%AC%E6%8D%A2/%E8%87%AA%E5%8A%A8%E8%BD%AC%E6%8D%A2markdown%E6%96%87%E4%BB%B6%E4%B8%AD%E5%9B%BE%E7%89%87%E5%88%B0%E5%9B%BE%E5%BA%8A.md/) 罢了,折腾了这么久,又试了试这个,发现也不好用。  最后,还是PigGo最香,提供了快捷键上传,上传完之后直接xxxTODO ## 6.4 Pycasbin 在pycasbin看到一个经常参与pycasbin的同行,可以参考一些他的contribution: - [https://github.com/Nekotoxin/nekotoxin.github.io/blob/gsoc_2022_summary/GSoC2022-summary.md](https://github.com/Nekotoxin/nekotoxin.github.io/blob/gsoc_2022_summary/GSoC2022-summary.md) 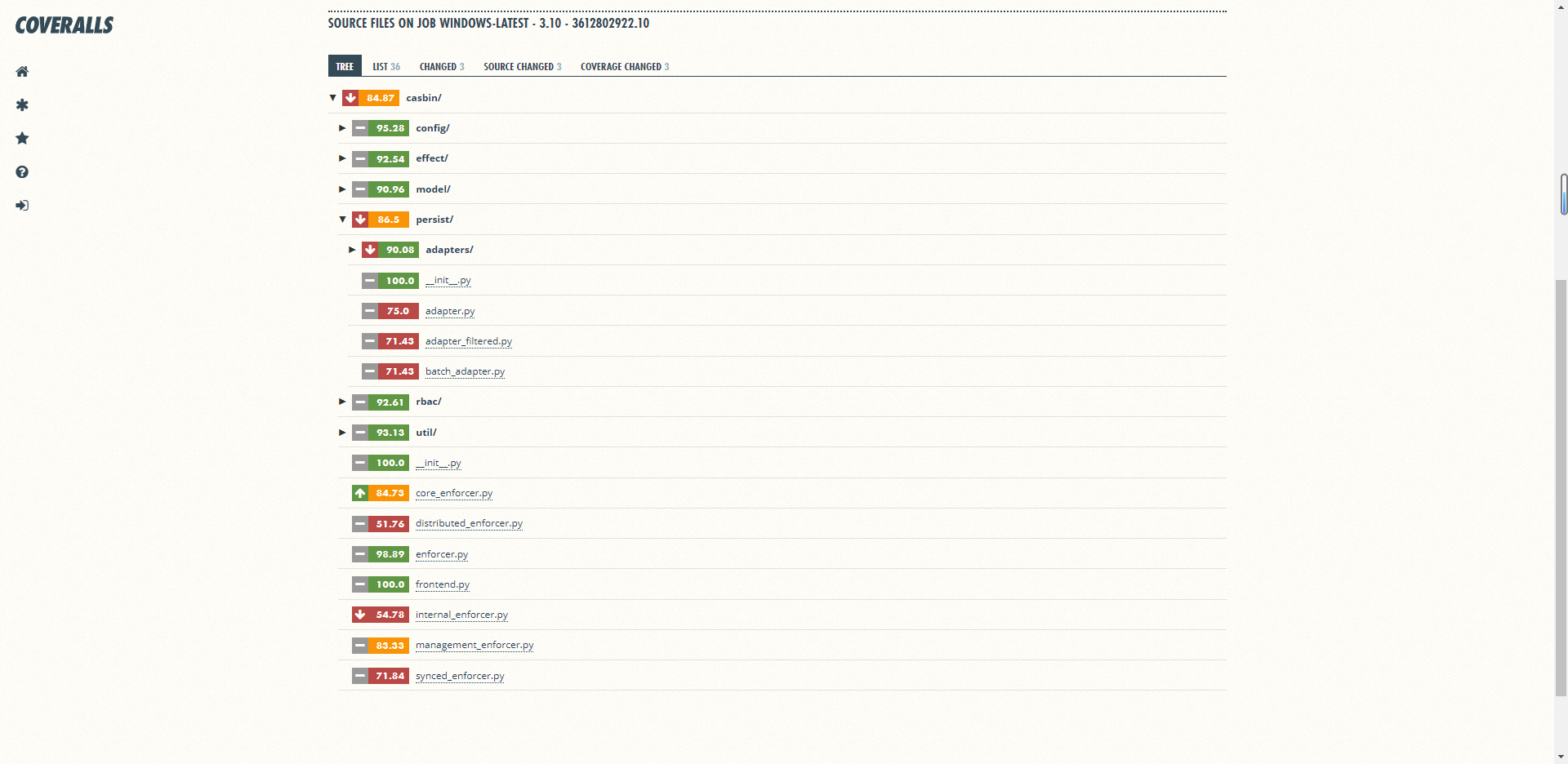 该内容为本文语雀导出markdown之后的文件,其图片链接为语雀的防外链链接,需要将其图片转换到本地,并替换markdown中的链接。
from imarkdown import MdFile, LocalFileAdapter, MdImageConverter def main(): adapter = LocalFileAdapter() converter = MdImageConverter(adapter=adapter) md_file = MdFile(name="
参数
{ "article_title":"", "page":1, "pageSize":10 } 请求
// - 设置数据源 xxx 为你设置的数据源 hint FRAGMENT_SQL_DATA_SOURCE = "xxx" // 自动转驼峰 hint FRAGMENT_SQL_COLUMN_CASE = "hump" // 开启分页 hint FRAGMENT_SQL_QUERY_BY_PAGE = true hint FRAGMENT_SQL_OPEN_PACKAGE = "off" var dataSetFun = @@mybatis(article_title) <% <select> SELECT CAST(@row_number := @row_number + 1 AS UNSIGNED) AS '序号', article_title AS '标题', DATE_FORMAT(created_at, '%Y-%m-%d') AS '发布时间', CASE WHEN article_status = 2 THEN '待发布' WHEN article_status = 3 THEN '已发布' END AS '状态' FROM `lc_knowledge_test`.
文章目录 kafka+ELK连接部署Kafkakafka操作命令kafka架构深入Filebeat+Kafka+ELK连接 kafka+ELK连接 部署Kafka ###关闭防火墙 systemctl stop firewalld systemctl disable firewalld setenforce 0 vim /etc/selinux/config SELINUX=disabled ###下载安装包 官方下载地址:http://kafka.apache.org/downloads.html cd /opt wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz ###安装 Kafka cd /opt/ tar xf kafka_2.13-2.7.1.tgz mv kafka_2.13-2.7.1 /usr/local/kafka ###修改配置文件 ##备份配置文件 cd /usr/local/kafka/config/ cp server.properties{,.bak} vim server.properties ---21行-- broker.id=0 ###21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2 ---31行--- listeners=PLAINTEXT://192.168.242.70:9092 ###31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改 ---42行--- num.network.threads=3 ###42行,broker 处理网络请求的线程数量,一般情况下不需要去修改 ---45行--- num.io.threads=8 #45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数 ---48行--- socket.send.buffer.bytes=102400 #48行,发送套接字的缓冲区大小 ---51行--- socket.receive.buffer.bytes=102400 #51行,接收套接字的缓冲区大小 ---54行--- socket.request.max.bytes=104857600 #54行,请求套接字的缓冲区大小 ---60行--- log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径 ---65行--- num.partitions=1 #65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖 ---69行--- num.
学习内容:从零开始定制一个SolidWorks插件 作为了一个职业的二次开发人员,我曾经创建插件"无数"。但从未像今天这篇文章这样,从空项目开始,之前的文章中我有介绍,要么使用SolidWorks API模板,要么使用了第三方框架。但是其实这两种办法其实都太臃肿了,里面包括了太多的一些东西,比如菜单呀,事件,毕竟有时候做个小插件可能都不涉及,不需要那么多功能。 为了更好的理解,我介绍一下从零开始定制一个插件的几个步骤,这里以VS2022来做演示,后面代码也会开源。 net farmework 版本的选择 正常来说,Solidworks对.net Framework没有严格的要求,最新的.net 6也是可以创建插件的,只是说sw每个版本自带的.net 版本是不一样的,大家可以查看安装包里面有个PreReqs文件夹,里面可以看到对应的版本。现在win11 和一些win10上面已经默认不带.net2.0 和.net3.5了,所以目前最好的就是.net 4.0,相对来说支持的广泛一些。 这里一定是去选择.net Framework的版本,其它的版本是不一样的。
这里指定框架版本,自己设置新的路径,点击 创建。
成功之后如下图:
dll的引用 要做SolidWorks的插件,肯定要引用官方提供的dll文件,文件在sw安装目录下面,如果不记得在哪,可以看下快捷方式的属性。
或者用电脑上的Everything软件搜索Sldworks.exe,看我这电脑上有2个版本,就能看出来两个路径。
至于引用哪一个版本的,好像不是太重要,因为高版本基本上向下兼容,在不调用高版本api的情况下,用低版本也可以。
我们就随便找个版本吧,进入到安装目录下\API\redist
这里面dll比较多,但常用的是:
当然还有个,上层目录下也有这几个dll
我们先打开项目的目录:
我在这里新建一个文件夹ReferenceDLL
然后把关键的dll复制进来
然后浏览到上面我们创建的文件夹,引用这4个dll
然后设置一下dll的互操作类型:
64位的设置 现在大部分电脑已经是64位了,如果需要生成的dll是64位的,可以这样修改:
在弹出的界面中选择:
COM的显示 此处要勾上。(当前也可以在类里面用属性显示定义COM可见。)
ISwAddin接口 首先重命名以前的Class1为你想要的名称,我这里改为AddinStudy.然后双击选中AddinStudy这个类,前方会出现重命名文件为xxxx.cs. 我们点一下,这样这个文件名也会变更了。 所以当前状态为:
然后,我们让这个类继承接口类ISwAddin ,前让VS自动引用对应的命名空间。
然后继续让VS自动实现接口:
此时代码就是:
public class AddinStudy:ISwAddin { public bool ConnectToSW(object ThisSW, int Cookie) { throw new NotImplementedException(); } public bool DisconnectFromSW() { throw new NotImplementedException(); } } 现在里面执行都是抛异常的,所以我们来改一下。
// 创建已经挖好洞的shape 完整形状的数组点位(一维数组) 洞的形状的数组点位(二维数组) createShape(pointsArray3D:{ x: number; y: number }[],holePoints:{ x: number; y: number }[][]) {
// 先创建一块大的形状 const shape = this.addShape(pointsArray3D);
// 再挖洞
for (let index = 0; index < holePoints.length; index++) {
const hole = this.addShape(holePoints[index]);
shape.holes.push(hole);
}
return shape;
}
// 创建shape(各类形状都可以)
addShape(shapeArr: { x: number; y: number }[]) {
let shape = new THREE.Shape();
let flag = true;
for (let index = 0; index < shapeArr.
问题:现在有很多学生出现这种情况,
Java的jdk配置成功,但是输入java -version等,命令行没有任何反应
Java下载后,手动配置环境变量,并且配置好,但是在命令行中无论输入java的什么都没有反应
问题:手动配置好JDK1.8版本的环境变量,但是在命令行窗口输入java、javac、java -version等命令,命令行都无反应
解决方法:
第一步:
打开cmd(命令行窗口),在命令行中输入where java,可以查看环境变量中的Java环境配置,如图1所示:
图1
前两行环境变量是我安装jdk15版本时,软件自动给我生成的环境变量,但是我输入java、javac、java -version这些命令行时,没有任何反应,如图2所示:
图2
后两行环境配置是我下载了一个JDK1.8版本,自己手动配置的环境变量。
通过各方面查找原因,最终原因锁定在配置环境变量的顺序上
第二步:
打开编辑系统环境变量,可以在搜索框搜索,如图3所示
图3
打开后,点击环境变量,然后会弹出环境变量的窗口,如图4所示
图4
找到系统变量的Path,点击编辑后,如图5所示:
图5
第三步
将自己两个手动配置的环境变量移动到软件自动配置的两个环境变量的前面,如图6所示:
图6
后面一直点击确定就可以了
重新打开命令行窗口,输入where Java,这时可以看到顺序已经改变了,如图7
图7
这时再输入java -version,就可以看到对应的jdk版本号,如图8所示:
图8
最后:问题得到解决
目录
1、Oracle数据库的安装(Windows版)
2、Oracle的体系结构
3、安装配置PLSQL Developer(可视化工具) 和远程连接Oracle
4、使用OraCle
常用数据类型:
在用户下创建表:
表的创建、修改、删除
数据增删改查
JDBC连接Oracle
修改的方法和添加相同,不同的地方在于sql语句。
删除数据,也是sql语句不同,其他都相同。
数据的导出与导入
(1)整库的导入导出
(二)按用户名称导出导入
(三)按表导出导入
Oracle和MySQL相比有什么异同,最直观的一点在于MySQL是开源的,Oracle是收费的。
Orale具有以下特点:
支持多用户、大事务量的事务处理数据安全性和完整性控制支持分布式数据处理可移植性 1、Oracle数据库的安装(Windows版) 安装在虚拟机中,首先要对虚拟机中的系统进行网络配置、一般有三种模式:
桥接模式:本地的计算机和虚拟机中的计算机处于同一个局域网,需要有外部网络环境(插网线)NAT模式:虚拟机中的计算机和本机共享一个IP地址(本机不能和虚拟机中的计算计通信)仅主机模式:本地的计算机和虚拟机中的计算机用一根网线连接 准备好Oracle数据库安装包:
点击下一步、然后安装即可,全自动安装。
安装完成连接Oracle数据库:
连接成功,执行select * from tabs; 可以查看所有的表。
退出:quit
2、Oracle的体系结构 1、数据库
Oracle中的数据库和其他数据库不同,其他的数据库可以创建多个数据库,而oracle一个操作系统中只有一个数据库,可以看做Oracle只有一个数据库。而且Oracle数据库是数据的物理存储(包括数据文件ORA或者DBF、控制文件、联机日志、参数文件等)。
2、实例
Oracle数据库实例是Oracle数据库运行时的实体,是操作系统进程和内存结构的集合。也就是说一个Oracle实例由一系列的后台进程和内存结构组成,一个数据库可以有n个实例。
3、数据文件
数据文件是数据库的物理存储单位。数据库的数据是存储在表空间中的,数据实体是在某一个或者多个数据文件中,而一个表空间可以有多个数据文件组成,一个数据文件只能属于一个表空间。一旦数据文件被加入到某个表空间后、就不能删除这个文件,而想要删除某个数据文件,要先删除这个数据文件所属于的表空间才行。
4、表空间
表空间是Oracle对物理数据上相关数据文件的逻辑映射。
5、段
段是一个逻辑数据存储单元,可以包含单个表、索引或其他对象。
6、区
区是分配给段的物理存储单元,通常包含多个数据块。
7、块
块是Oracle数据库中最小的物理存储单元,通常包含多条记录。
8、用户
Oracle中的用户和MySQL中的用户不同,MySQL中的用户登录之后可以看到所有的数据库。而Oracle中存在多个用户、每一个用户对应一个应用,用户是在表空间下建立的。用户登陆后只能看到和操作自己的表, ORACLE 的用户与 MYSQL 的数据库类似,每建立一个应用需要创建一个用户。在用户下面创建表。
3、安装配置PLSQL Developer(可视化工具) 和远程连接Oracle 远程连接Oracle数据库 需要使用工具:instantclient
在cmd中进入到改文件目录中,执行如下命令(注意是在本机中操作,从本机连接虚拟机中的Oracle数据库):
即可远程连接到Oracle数据库。
图形可视化界面工具 Oracle本身没有可视化界面,需要使用第三放工具:PLSQL Developer,下载该工具进行安装即可(注意安装目录不能带有空格或者中文)。
安装完成之后,打开软件如图,对该软件进行配置:
这样就可以使用这个图形化工具进行远程连接。
接下来继续配置
复制到本机的任一目录下即可,然后用记事本打开该文件,对该文件进行修改配置:
然后在本机配置环境变量:
1.出现XShell链接不上问题 2查看虚拟机ip ip addr 在cmd界面中查看ip 查看网段是否一致
如果不一致在网络适配中修改对应设置
3.即可链接 4.修改虚拟机ip地址 1.打开编辑器 vi /etc/sysconfig/network-scripts/ifcfg-eth0 //修改网卡配置文件 2进入编辑模式 按键盘i键进入编辑模式,上下左右方向键进行移动。
配置文件中如果没有的字段,则自行输入进去。
下面//后内容不需要输入,是注释内容。
2.1修改BOOTPROTO BOOTPROTO=static //地址分配为静态 2.2修改ONBOOT ONBOOT=yes /开启自启动 2.3修改ip和掩码等 若只需要配置IP和掩码则其他不填写。
IPADDR=192.168.1.1 //IP地址 NETMASK=255.255.255.0 //子网掩码 GATEWAY=192.168.1.254 //网关 DNS1=1.1.1.1 //DNS1 DNS2=8.8.8.8 //DNS2 3.保存 按下ESC后输入:wq保存
4.重启网络服务 因为修改完配置文件有缓存数据,需要重启一下网络服务才可以生效。
systemctl restart network \\重启网络服务
1、网站地址
Arm Keil | Deviceshttps://www.keil.arm.com/devices/
2、在搜索框中输入需要下载的芯片名,例:STM32H743XI,然后在搜索结果中选择需要的芯片,进入到芯片参数界面。
3、进入到芯片参数界面后,点击STM32H7xx_DFP蓝色字样。
4、进入STM32H7xx_DFP后,即可直接下载最新版本,也可以根据需要下载历史版本。
以上是官网下载方法,速度较慢,受不了慢速就科学上网。
目录
1.图像增强
1.1 灰度转换
1.2 直方图均衡化
1.3 空域滤波
2.特征提取
2.1 SIFT特征提取
2.2 SURF特征提取
2.3 HOG特征提取
3.图像分割
3.1 基于阈值的分割
3.2 基于区域的分割
3.3 水平分割
4.目标检测
4.1 基于HOG+SVM的人脸检测
4.2 基于YOLOv3的目标检测
5.图像重建
5.1 基于插值的图像重建
5.2 基于深度学习的图像重建
6.其他应用
6.1 图像拼接
6.2 图像融合
6.3 图像配准
Matlab是一种强大的数学计算软件,也是图像处理领域的常用工具。Matlab提供了许多图像处理相关的函数和工具箱,可以方便地实现各种图像处理算法。
1.图像增强 图像增强是一种常用的图像处理技术,可以改善图像的质量和可视性。Matlab提供了许多图像增强的函数和工具箱,如灰度转换、直方图均衡化、空域滤波等。以下是一些图像增强的应用示例:
1.1 灰度转换 灰度转换是将彩色图像转换为灰度图像的过程。Matlab中可以使用rgb2gray函数实现灰度转换。下面是一个简单的示例代码:
I = imread('image.jpg'); I_gray = rgb2gray(I); imshow(I_gray); 1.2 直方图均衡化 直方图均衡化是一种常用的图像增强技术,可以增强图像的对比度和亮度。Matlab中可以使用histeq函数实现直方图均衡化。下面是一个示例代码:
I = imread('image.jpg'); I_gray = rgb2gray(I); I_eq = histeq(I_gray); imshow(I_eq); 1.3 空域滤波 空域滤波是一种常用的图像增强技术,可以去除图像噪声、模糊和平滑化图像。Matlab中提供了许多空域滤波函数,如高斯滤波、中值滤波等。下面是一个示例代码:
I = imread('image.
起因:表格内td内容需要扩展展示
得到了这样的结果
确实满足了需求,但是,简单思考了一下可能存在的问题,于是去扒了一下DOM。enm……果然如此
有多少行就生成了多少个Popover
这哪行啊,表格每页数量还是能选的,哪天产品脑子一抽,来个1000,5000,岂不是玩蛋
所以,这是病,得治。因为我解决不了提出问题的人
于是,翻了一下api,挨!找到了
这玩意有用,琢磨一下试试
上代码,为了容易从DOM中观测,给他起个名字叫 MultipleIn1
<el-popover ref="popover" v-model:visible="state.popoverVisible" virtual-triggering :virtual-ref="virtualRef" placement="top" popper-class="MultipleIn1" > <div class="p8">popover content</div> </el-popover> 此时,Table Column部分则改为:
<el-table-column label="ID" prop="id" width="120"> <template #default="{ row }"> <span @mouseenter="(e) => showPopover(e, row)"> {{ row.id }} </span> </template> </el-table-column> @mouseenter显示Popover
因为el-popover组件默认了隐藏时间200ms,所以,有频率需求的,可以通过调节hide-after参数来调节
由于el-popover文档内没有virtual-ref的描述,尝试了几次之后,发现这玩意绑DOM即可 于是有了显隐的方法:
const showPopover = (e, row) => { virtualRef.value = e.target; state.popoverVisible = true; }; 然后,
好使!
扒一下DOM:
好使! [注:没写的参数自补全]
输入net start mysql时显示MySQL 服务无法启动。服务没有报告任何错误。如下图:
解决方案:
有可能是3306端口被占用了,可输入netstat -ano命令查看占用3306端口进程的PID,如下图:
可知PID为37544的进程占用了3306端口,接下来打开任务管理器,找到改进程,然后结束进程即可。
再次执行命令会发现可以成功启动了。
查阅了很多文档,最终梳理清楚了从零开始的创建过程,在此记录一下。
我用的是VS2022,正常创建新项目的时候,左侧是没有SwCSharpAddin这个模板的,那我们该如何添加模板呢?
首先下载工程模版,链接:https://pan.baidu.com/s/1dOG4mBE2X9AOMiwbsib73A?pwd=1314 提取码:1314
然后放到用户的VS模板目录,这里一定要记住,每个人的模板目录不同,我是通过文档中
此时,打开ProjectTemplates文件夹,将压缩包中解压到ProjectTemplates文件夹中
这个时候,我们就可以在VS创建项目里找到SW的模板了
点击下一步,后续操作可以看图,剩下的就是根据自身需求进行更改了。
以上就是从开始寻找模板到最后创建成功的全部过程。网上大多数的教程按着做了总会出现很多问题。
后续我也会陆续的更新关于SW二次开发的新手内容(我自己也在摸索学习),希望可以与大家互相交流
篇1:SVM原理及多分类python代码实例讲解(鸢尾花数据) SVM原理 支持向量机(Support Vector Machine,SVM),主要用于小样本下的二分类、多分类以及回归分析,是一种有监督学习的算法。基本思想是寻找一个超平面来对样本进行分割,把样本中的正例和反例用超平面分开,其原则是使正例和反例之间的间隔最大。
SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。如下图所示,wx+b=0即为分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。
SVM实现分类代码 1.数据集介绍——鸢尾花数据集 下载方式:通过UCI Machine Learning Repository下载或者直接使用代码
from sklearn.datasets import load_iris
数据展示与介绍(iris.data)
Iris.data中有5个属性,包括4个预测属性(萼片长度、萼片宽度、花瓣长度、花瓣宽度)和1个类别属性(Iris-setosa、Iris-versicolor、Iris-virginica三种类别)。首先,需要将第五列类别信息转换为数字,再选择输入数据和标签。
2.多分类python代码(二分类可看做只有两类的多分类) from sklearn import svm #引入svm包 import numpy as np import matplotlib.pyplot as plt import matplotlib from sklearn.model_selection import train_test_split #定义字典,将字符与数字对应起来 def Iris_label(s): it={b'Iris-setosa':0, b'Iris-versicolor':1, b'Iris-virginica':2} return it[s] #读取数据,利用np.loadtxt()读取text中的数据 path='iris.data' #将下载的原始数据放到项目文件夹,即可不用写路径 data= np.loadtxt(path, dtype=float, delimiter=',', converters={4:Iris_label}) #分隔符为‘,' #确定输入和输出 x,y=np.split(data,(4,),axis=1) #将data按前4列返回给x作为输入,最后1列给y作为标签值 x=x[:,0:2] #取x的前2列作为svm的输入,为了便于可视化展示 #划分数据集和标签:利用sklearn中的train_test_split对原始数据集进行划分,本实验中训练集和测试集的比例为7:3。 train_data,test_data,train_label,test_label=train_test_split(x,y,random_state=1,train_size=0.7,test_size=0.3) #创建svm分类器并进行训练:首先,利用sklearn中的SVC()创建分类器对象,其中常用的参数有C(惩罚力度)、kernel(核函数)、gamma(核函数的参数设置)、decision_function_shape(因变量的形式),再利用fit()用训练数据拟合分类器模型。 '''C越大代表惩罚程度越大,越不能容忍有点集交错的问题,但有可能会过拟合(defaul C=1); kernel常规的有‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ ,默认的是rbf; gamma是核函数为‘rbf’, ‘poly’ 和 ‘sigmoid’时的参数设置,其值越小,分类界面越连续,其值越大,分类界面越“散”,分类效果越好,但有可能会过拟合,默认的是特征个数的倒数; decision_function_shape='ovr'时,为one v rest(一对多),即一个类别与其他类别进行划分,等于'ovo'时,为one v one(一对一),即将类别两两之间进行划分,用二分类的方法模拟多分类的结果。 ''' model=svm.
后代选择器 选择器1 选择器2 选择器3{} 找到1里面的2里面的3,最终找到的是3
5.选择器权重:
id选择器>类选择器(class选择器)>类型选择器(div,span,img,a…)
an,img,a…)
100 10 1
html写法
<li v-for="item in Overview.config" :key="item.value" > <BarChart :ref="item.value+'ChartRef'" style="height: 120px" :ids="item.value" /> </li> 数据
Overview = { data: [], config: [{ value: 'cellNumber', title: '小区数', color: ['#7FB9ED', '#1E88E5'], unit: '个' }, { value: 'energySavingCell', title: '节能小区数', color: ['#7FB9ED', '#1E88E5'], unit: '个' }, { value: 'saveEnergy', title: '节省能耗', color: ['#E35500', '#FF8A00'], unit: 'kW·h' }] } 定义ref并赋值
const cellNumberChartRef = ref(null) const energySavingCellChartRef = ref(null) const saveEnergyChartRef = ref(null) 调用组件方法
Background 有的时候系统中的glibc版本较低,新装的软件依赖高版本的glibc,那这个时候需要升级下glibc。
1、常见异常 通常会遇到这样的异常:ImportError: /usr/lib64/libc.so.6: version GLIBC_2.28’ not found`
1、查看系统中可使用的glibc版本 strings /lib64/libc.so.6 |grep GLIBC_ 2、glibc库下载 glibc库各版本下载地址 3、编译安装 上传到服务器或者在线安装
# 在线安装 wget https://ftp.gnu.org/gnu/glibc/glibc-2.28.tar.gz # 解压 tar zxf glibc-2.28.tar.gz cd glibc-2.28 mkdir build cd build ../configure --prefix=/usr # 这步执行时间依赖你的配置,我的八核的几分钟就好了 make -j8 make install 可能遇到的问题
LD_LIBRARY_PATH shouldn't contain the current directory when building glibc. Please change the envir
【解决方法】 [root@localhost opt]# echo $LD_LIBRARY_PATH :/usr/local/lib [root@localhost opt]# export LD_LIBRARY_PATH= [root@localhost opt]# echo $LD_LIBRARY_PATH [root@localhost opt]# .
网站MD5.CC
关闭防火墙和SeLinux
创建配置文件,将原来 的配置重命名 [root@server ~]# mv /etc/httpd/conf.d/xiao.conf /etc/httpd/conf.d/xiao.conf.bak [root@server ~]# vim /etc/httpd/conf.d/xiao.conf <Virtualhost 192.168.145.128:80> DocumentRoot /luntan ServerName 192.168.145.128 </Virtualhost> <Directory /luntan> AllowOverride none Require all granted </Directory> [root@server ~]# mkdir /luntan [root@server ~]# cd /luntan [root@server luntan]# 用xftp传输文件包
查看压缩包,并解压
[root@server luntan]# ll total 11492 -rw-r--r-- 1 root root 11766137 Jul 11 18:00 Discuz_X3.5_SC_UTF8_20230316.zip [root@server luntan]# unzip Discuz_X3.5_SC_UTF8_20230316.zip #解压 [root@server luntan]# ll total 11616 -rw-r--r-- 1 root root 11766137 Jul 11 18:00 Discuz_X3.
推荐链接:
总结——》【Java】
总结——》【Mysql】
总结——》【Redis】
总结——》【Kafka】
总结——》【Spring】
总结——》【SpringBoot】
总结——》【MyBatis、MyBatis-Plus】
总结——》【Linux】
总结——》【MongoDB】
总结——》【Elasticsearch】
IDEA——》解决Command line is too long 1、操作2、现象(错误信息)3、原因4、解决方案1:修改文件.idea/workspace.[xml](https://so.csdn.net/so/search?q=xml&spm=1001.2101.3001.7020)方案2:修改参数Shorten command line 1、操作 Debug启动@Test方法
2、现象(错误信息) Error running EsfRegionTest.getEsfRegionByParam. Command line is too long. Shorten the command line via JAR manifest or via a classpath file and rerun. 3、原因 命令行太长
4、解决 方案1:修改文件.idea/workspace.xml 1)找到项目下的.idea/workspace.xml
2)打开文件,找到标签:PropertiesComponent
3)添加一行属性:
<component name="PropertiesComponent"> 其它属性代码不要修改,只添加下面一行属性代码 <property name="dynamic.classpath" value="true" /> </component> 方案2:修改参数Shorten command line 1)点击菜单栏Run——>Edit Configurations
2)点击Modify options——>Shorten command line,显示出Shortn command line参数(默认值为noe)
参考链接:Python学习笔记11:函数修饰符 - 魔芋红茶 - 博客园 (cnblogs.com) 目录
接收和返回函数
可变参数列表
内部函数
函数修饰符
Python有很多有趣的特性,其中函数修饰符就是一个。
我们在之前的那个web应用示例中用过如下写法:
@web.route('/log') @符号后边的,就是一个函数修饰符,它可以在不改变原有函数的情况下改变函数的行为(通常来说是增强函数的行为)。
我们下面就来说说怎样实现一个函数修饰符。
在这之前,我们要先介绍几个必须要先掌握的内容。
接收和返回函数 如我们在Python学习笔记0:变量中讨论的,在Python中,所有的一切都是对象,而函数也不例外。那理所应当的,函数也可以作为对象被另一个函数所接收和返回。
我们看下边的例子:
def receiveFunc(func): print(type(func)) return func def hellow(): print("hellow world") returned=receiveFunc(hellow) returned() 输出
<class 'function'>
hellow world
我们可以看到,receiveFunc接收了函数hellow并打印出其类型,然后返回,返回的函数依然可以正常执行并输出结果。
可变参数列表 我们都知道,在函数签名的定义中,参数数目可以是一个,也可以是多个,但都是定义的时候就指定的,但Python还有另一种定义方法,可以接收数目不定的参数。
def getMultipParam(*multipParams): for param in multipParams: print(param,' ',end='') print() getMultipParam(1,2,3) getMultipParam('a','b','c','d','e') 输出
1 2 3
a b c d e
通过类似*params这种方式,可以指定参数接收的是可变长度的参数列表,这种方式有点像C++中的指针,可以接收一个数组作为参数,而在Python这里,就是接收一个列表,本质上接收函数会把收到的参数列表转变为一个列表进行处理。
当然,你也可以直接传一个列表过去,但是需要用*来指定:
def getMultipParam(*multipParams): for param in multipParams: print(param,' ',end='') print() getMultipParam(*[1,2,3]) getMultipParam(*['a','b','c','d','e']) 输出
1.曲线图 MATLAB作图是通过描点、连线来实现的,故在画一个曲线图形之前,必须先取得该图形上的一系列的点的坐标(即横坐标和纵坐标),然后将该点集的坐标传给MATLAB函数画图.
命令为: plot(X,Y,S)
X,Y是向量,分别表示点集的横坐标和纵坐标
S(线型):y 黄色 . 点 - 连线 m 洋红 o 圈 : 短虚线 c 蓝绿色 x x-符号 -. 长短线 r 红色 + 加号 -- 长虚线
plot(X,Y) — 画实线
plot(X,Y1,S1,X,Y2,S2,……,X,Yn,Sn) — 将多条线画在一起
例 在[0,2]用红线画sin x,用绿圈画cos x.
x=linspace(0,2*pi,30); y=sin(x); z=cos(x); plot(x,y,'r',x,z, 'g0') 2.符号函数(显函数、隐函数和参数方程)画图 (1) ezplot
ezplot(‘f(x)’,[a,b]): 表示在a<x<b绘制显函数f=f(x)的函数图.
ezplot(‘f(x,y)’,[xmin,xmax,ymin,ymax]): 表示在区间xmin<x<xmax和 ymin<y<ymax绘制隐函数f(x,y)=0的函数图.
ezplot(‘x(t)’,’y(t)’,[tmin,tmax]): 表示在区间tmin<t<tmax绘制参数方程x=x(t),y=y(t)的函数图.
例 在[0, ]上画y=cos x 的图形.
ezplot(‘sin(x)’,[0,pi]) 例 在[-2,0.5],[0,2]上画隐函数的图.
ezplot('exp(x)+sin(x*y)',[-2,0.5,0,2]) (2) fplot
fplot(‘fun’,lims): 表示绘制字符串fun指定的函数在lims=[xmin,xmax]的图形.
注意: [1] fun必须是M文件的函数名或是独立变量为x的字符串.
(1)OSI七层模型分别是什么,各自的功能是什么?
自底向上来说,首先是物理层(比如集线器等,负责传输光电信号,在物理网络中传输数据),数据链路层(网桥或者交换机工作,负责数据的封帧和错误检测以及mac寻址,有ARQ自动重传请求协议,PPP点对点协议),网络层(路由器工作,有IP协议,ICMP Internet控制报文协议,ARP地址转换协议。负责数据的路由、转发、分片),传输层(TCP,UDP协议,提供端到端的数据传递),会话层(负责建立、管理、终止会话),表示层(对数据进行翻译、加密、压缩),应用层(有DNS,HTTP,WWW,HTTPS,SSH协议等,负责给应用程序提供统一的接口)
如果问的是五层模型:应用层(负责应用进程间通信和交互的规则)
(2)TCP三次握手,为什么不能两次?
客户端向服务器发起建立连接请求SYN,发一个序列号给服务器。服务器在收到这个报文之后,返回一个确认ACK,客户端收到之后,再次返回一个ACK确认报文。此时才算对话建立。假设只有两次握手,客户端可能没有服务器的确认报文,但是服务器以为已经和客户端建立了连接,可能会发送一些数据,但是客户端并不会接收,浪费了资源。而且服务器可能接收到一个早已失效的SYN,向客户端发送了确认报文并且建立连接,但是客户端并不需要向服务端发送数据。
(3)TCP四次挥手,为什么不能三次?
客户端向服务器发送完数据之后,发起释放连接报文FIN,服务器收到后向客户端发送确认报文ACK,服务器会有一个关闭等待时间来处理数据,然后服务器向客户端发出释放连接报文FIN,客户端收到后,向服务端发送ACK确认。发送之后,客服端会等待2MSL,如果服务器没有收到最后的ACK,还可以让客户端重发报文,并且确保了本次TCP连接中的所有报文都消失,不会出现在下一个TCP中。
(4)TCP如何保证有效(可靠传输)?
主要有校验和,序列号,超时重传,流量控制,以及拥塞避免。
校验和:在发送端和接收端分别计算数据的校验和,如果两者不一致,说明数据在传输过程中出现了差错,TCP将丢弃且不确认此报文。
序列号:TCP会对每一个发送的字节进行编号,接收方收到数据后,发送的ACK报文中带有相应的确认编号,告诉发送方,下一次发送数据编号从几开始。接收方可以通过序列号判断出是否是相同数据,丢包后从哪一个序列号开始重传包。
超时重传:如果发送方在重传计时器规定的时间内没有收到ACK,那发送方就会重新发送数据。(如果是发送方数据丢失,接收方收到重传数据后立刻发送ACK,如果是ACK丢失,接收方收到数据后直接丢弃再发ACK。)如果重发数据之后,还是没有收到ACK,确认应答时间将会以2倍、4倍指数函数延长,直到最后关闭连接。
流量控制:如果发送端发送数据太快,接受端来不及接受就会出现丢包,因此TCP用滑动窗口进行了流量控制。接收端收到数据包后发送ACK报文时会将自己的窗口大小填入ACK中,发送方会根据窗口大小控制发送速度,如果窗口大小为0 ,发送方停止发送。
拥塞控制:如果网络出现拥塞,会有丢包,发送方继续重传会加重网络拥塞。拥塞控制主要有四部分组成:慢开始、拥塞避免、快重传、快恢复。
为了避免一开始发送大量数据而产生网络阻塞,初始化拥塞窗口为1,收到ACK后设置拥塞窗口按指数形式增长。
如果到达慢开始的门限值后,进入到拥塞避免阶段,窗口每次增加1。如果网络出现超时,门限值将变为此时拥塞窗口的一半,然后将拥塞窗口重新置为1。
在网络中如果丢失了某个报文,就快速向发送端发送三次前一个包的ACK,无需等待重传计时器,就可直接进行该报文的重传。
快恢复是指将门限值设置为发生快重传的拥塞窗口的一半,将拥塞窗口设置为门限值,开始拥塞避免阶段。
(5)TCP的主要特点?TCP与UDP的区别,UDP的主要特点,应用场景?
TCP是面向连接的,而且是端到端连接。提供可靠传输,保证数据无差错,不丢失,不重复,而且按序列到达。TCP允许通信双方的应用进程在任何时候都能发送数据,TCP连接的两端都设有缓存,用来临时存放双方通信的数据。TCP是面向字节流的,TCP把应用程序的数据看成是一串无结构的字节流。
TCP适合对效率要求低,对准确性要求高或者要求有连接的场景,比如远程终端接入,浏览器,文件传输,电子邮件等。
UDP是面向报文的,是不具有可靠性的数据报协议,不提供复杂的控制机制,出现丢包也不会重发,也没有纠正包乱序的功能,但是它传输效率高,适合包总量较少的通信(DNS),视频、音频等多媒体通信(即时通信),限定与局域网等特定网络中的应用通信,广播通信等对效率要求高,对准确性要求低的通信场景。
(6)在交互过程中如果数据传送完了,不想断开连接,如何维持(THHP协议)?
在HTTP中响应体的connection字段指定为keep-alive。
(7)TCP和UDP分别对应的应用层协议有哪些?
TCP对应的文件传输协议有:FTP(文件传输协议)、telnet(远程登陆协议)、SMTP+POP3(邮件传输协议)、HTTP(超文本传输协议)
UDP对应的应用层协议有:DNS(域名解析服务)、SNMP(简单网络管理协议)、TFTP(简单文件传输协议)
(8)TCP最大连接数限制?
一个TCP连接的标识是{local IP,local port,remote IP,remote port},端口数据类型是unsigned short,理论上来说,客户端最大TCP连接数是65535(端口0不能用),服务器理论上说,最大的TCP连接是客户端ip数 *客户端 port数。实际环境中,受到机器资源、操作系统的限制,目前在server端的最大并发TCP连接数可以达到10万。一半服务器可以有几万级别,可以用分布式技术将并发负载分担到多台服务器上。
(9)TCP粘包如何产生,如何解决拆包和粘包?
因为TCP协议是基于字节流传输数据的,不包含数据包的概念,需要应用层协议自己设置消息的边界,如果应用层协议没有使用基于长度或者基于终结符等方式进行处理,就会导致多个消息粘包和拆包。
操作系统在发送TCP数据时,会通过缓冲区来优化,如果一次请求的数据量比较小,没有达到缓冲区,就会将多个请求合并为一个请求,形成粘包;如果一次请求的数据量比较大,超过了缓冲区,TCP就会将其拆分多次发送,形成拆包。
解决方案:发送端将每个包都封装成固定的长度,不足可以padding0;发送端在每个包末尾使用固定的分隔符;将消息分为头部和消息体,头部中保存整个消息的长度,只有读取足够长度的消息之后,才算是读到了完整信息(最常用)。
(10)有很多time——wait状态会导致什么问题,怎么解决?
在高并发短链接的业务场景中,服务器处理完请求后主动发送FIN,就会有大量的连接处于time——wait状态,服务器维护每一个连接需要一个socket,而文件描述符使用有上限,如果持续高并发,会导致一些正常的连接失败。
过多的time-wait主要有两种危害:内存资源占用,端口资源占用。
可以修改配置或者设置so_reuseaddr套接字,使服务器处于time——wait状态下的端口能够快速回收和重新使用。也可以使用长连接的方式减少TCP的连接与断开,在长连接的业务中往往不需要考虑time-wait状态,但实际上长连接的业务中并发量一般不会太高。
(11)TCP的四个计时器?
1、重传计时器:为了控制丢失的报文段,在TCP发送报文时,创建重传计时器,在截止时间之前,收到了报文的ACK,就撤销计时器,截止时间到了还未收到报文的ACK,就重传报文,并且复位计时器。
2、坚持计时器:避免零窗口大小通知可能导致的死锁问题。当发送端接到零窗口报文后,发送端就停止发送数据,等到接收端缓存区有空间后,会发送ACK更新窗口,但是接收端的这个报文可能会丢失,接收端处于等待数据的状态,但是发送端没有等来新窗口,也在等待,形成死锁。因此TCP为每个连接设置了坚持计时器,当发送端收到零窗口后,启动坚持计时器,计时器到期后,发送端主动发送探测报文,让接收端重新发送窗口。
3、保活计时器:为了防止两个TCP连接出现长时间的空闲,每当服务器接收到客户端的数据后,都重置保活计时器,到期后如果没有收到客户端的数据,就会发送探测报文,每隔75秒发送一次,连续发送十次之后,仍然没有收到客户端数据,则认为客户端出现故障,终止连接。
4、time-wait计时器:当TCP关闭连接时,在客户端发送最后一个ACK后开始计时,可以保证本次连接中的全部数据都不再传输。
(12)停止等待协议?
停止等待协议时TCP保证传输可靠的重要途经,就是指发送完一个分组就停止发送,等待对方确认,只有对方确认过,才发送下一个分组。
主要包括以下几种情况:
无差错情况:发送方发送分组,接收方在规定时间内收到,并且回复确认,发送方再次发送报文。
超时重传:1、分组丢失:接收端没有收到报文不会发送ACK,发送方在一段时间内没有收到ACK会重新发送报文。2、确认丢失:接收端收到了报文后,发送ACK,但是ACK丢失,发送方在没有收到ACK的情况下会重新发送报文,接受端丢弃该分组,重新发ACK。3、传送延迟:接收端收到了报文,并且发送了ACK,但是ACK传输太慢,发送方以及重发了报文,接收端收到报文后丢弃,再重发ACK。发送端如果收到多个确认,就停止发送,丢弃其他确认。
停止等待协议的优点是简单,缺点时信道的利用率太低,一次发送一条消息,使得信道的大部分时间都是空闲的,
(13)连续ARQ协议和滑动窗口协议?
连续ARQ协议和滑动窗口协议主要解决了信道效率低,增大了吞吐量,以及控制了流量。
连续ARQ协议:发送方维护的窗口中不止一个分组,窗口大小由接收方决定,因此大小会动态变化,只要在窗口中的分组都可以被发送,提高了信道的利用率,并且采用累积确认的方式,对按序到达的最后一个分组发送确认。(比如发送方发了1、2、4、5,接收方只会确认2,发送方会重发3、4、5)
滑动窗口协议:窗口不断向前走,该协议允许发送方在停止等待前发送多个数据组分,发送方不必每发一个分组就停下来确认,因此该协议可以加速数据的传输,还可以控制流量。
(14)SYN FLOOD时什么?
SYN洪水攻击,时拒绝服务攻击的一种。利用TCP协议的安全缺陷,不断发送一系列的SYN请求到目标系统,消耗服务器系统的资源,导致目标服务器不响应合法的流量请求。这种攻击发生在TCP握手阶段,攻击者向目标服务器发送大量的SYN数据包,服务器会相应每一个请求然后返回ACK,等待响应。服务器为了维护一个庞大的半连接列表而消耗很多资源,造成服务器崩溃。
(15)HTTP版本区别?
HTTP1.0时一种无状态,无连接的应用层协议,浏览器每次请求都需要与服务器建立一个TCP连接,服务器处理完成以后,立即断开连接,服务器不跟踪客户端也不记录过去的请求。这种无状态性可以借助cookie和session机制来做身份认证和状态记录。1.0版本无法复用连接,无连接的特性会使网络的利用率变低。如果前一个请求响应一直不到达,下一个请求就不发送,后门的请求就阻塞了。
HTTP1.1继承了HTTP1.0的简单,客服了1.0的性能问题。1.1增加了connection字段,通过keep-alive保持HTTP连接不断,避免每次客户端与服务器请求都要重复建立释放TCP,提高了网络的利用率。1.1支持请求管道化,增加缓存处理,增加host字段,支持断点传输。进一步改进了1.0的效率。
HTTP2.0在应用层和传输层之间增加了一个二进制分层帧,实现了真正的并行传输。在一个TCP连接上,每个数据流以消息的形式发送,消息由一个或者多个帧组成,这些帧可以乱序发送,然后再根据每个帧头部的stream-id重新封装。多路复用可能会导致关键字被阻塞,2.0中每个数据流都可以设置优先级和依赖,优先级高的数据流会被服务器优先处理和返回客户端,数据流还可以依赖其他的子数据流。1.x中,浏览器会在每次请求的时候把cookie附在header上发给服务器,2.0使用encoder来减少需要传输的header大小,通讯双方各自保存一份header表,不需要直接发送值,通过发送key缩减头部大小。服务器除了最初请求的响应外,还可以额外向客户端推送资源,无需客户端明确的需求。
(16)post和get区别?应用场景?
1. 使用cmd命令 dotnet --info 查看自己使用的SDK版本
3.直接找到项目中的 global.json 文件,右键打开,直接修改版本为本机的SDK版本,就可以用了
微软文档也有详细说明: NETSDK1141:无法解析 global.json 中指定的 .NET SDK 版本 - .NET CLI | Microsoft Learn
写在前面 很多软件工程师的职业规划是成为架构师,但是要成为架构师很多时候要求先有架构设计经验,而不做架构师又怎么会有架构设计经验呢?那么要如何获得架构设计经验呢?
1 高并发是什么 高并发是指系统在同一时间内处理的请求量非常大,通常是指每秒处理的请求量达到数千到数百万级别。
在互联网应用中,高并发是一个非常常见的问题,因为随着用户数量的增加,系统需要处理的请求量也会越来越大。
高并发的处理需要系统在短时间内处理大量的请求,因此对系统的稳定性和性能提出了很高
的要求。
1.1 常见的方法 为了解决高并发问题,需要在系统架构、设计和运维等方面进行优化,一些常见的方法包括:
分布式架构:采用分布式架构可以将系统拆分成多个子系统,每个子系统只处理一部分请求,这样可以减轻单个系统的负载。
缓存机制:通过缓存机制可以将一些常用的数据缓存起来,减少对数据库的访问,从而提高系统的性能。
负载均衡:采用负载均衡可以将请求均匀分配到多个服务器上,避免单个服务器过载,从而提高系统的可用性和性能。
数据库优化:对数据库进行优化可以提高系统的性能,包括合理使用索引、分库分表、读写分离等方面。
异步处理:采用异步处理可以将一些耗时的任务放到后台进行处理,从而避免对前端请求的阻塞,提高系统的并发处理能力。
总之,高并发是一个非常重要的问题,需要在系统架构、设计和运维等方面进行全面的优化,从而提高系统的性能和稳定性,保证系统能够正常处理大量的请求。
2 问题思考 如何获得架构设计经验呢?
一方面可以通过工作来学习,观察所在团队的架构师是如何工作的,协助他做一些架构设计和落地的工作。同时,思考如果你是架构师,你将如何完成工作,哪些地方可以做得更好。
另一方面,也可以通过阅读来学习,看看那些典型的、耳熟能详的应用系统是如何设计的。同样,你也可以在阅读的过程中思考:如果你是这个系统的架构师,将如何进行设计?如何输出你的设计结果?哪些关键设计需要进一步优化?
通过这样不断地学习和思考,你就会不断积累架构设计的经验,等你有机会成为架构师的时候,就可以从容不迫地利用你学习与思考获得的经验和方法,开始你的架构师职业生涯。
2.2 图书推荐 现在,知名技术畅销书作者李智慧老师的全新力作,基于真实经典案例改编的《高并发架构实战:从需求分析到系统设计》纸书终于出版!
2.3 详细介绍 从需求分析到系统设计,通过八大维度、18个案例,全面介绍高并发系统的设计方法、核心技术与架构实践 我们知道,“高并发”是现在系统架构设计的核心,也是很多大厂的关注焦点。一个架构师如果设计、开发的系统不支持高并发,那简直不好意思跟同行讨论。在应聘大厂架构师岗位的时候,如果你对高并发架构说不出什么,恐怕面试就凶多吉少了。 在架构设计领城,高并发的历史非常短暂,这一架构特性是随着移动互联网的发展才逐渐变得重要起来的。
2.4 现状分析 现在有很多大型互联网应用系统的用户是分布在全球的,用户体量动辄十几亿。这些用户即使只有千分之一同时访问系统,也会产生一百万的并发访问量。
因此,高并发是现在大型互联网系统必须面对的挑战,当同时访问系统的用户不断增加时,要消耗的系统计算资源也会不断增加。
所以系统需要更多的 CPU 和内存去处理用户的计算请求,需要更多的网络带宽去传输用户的数据,也需要更多的硬盘空间去存储用户的数据。而当消耗的资源超过了服务器资源极限的时候,服务器就会崩溃,整个系统将无法正常使用。
3 几大场景 3.1 足够真实的高并发系统设计场景 大家看过了不少高并发系统设计的技术资料之后,你可能还是会有这样的困惑:为什么我还是对设计一个完整的高并发系统没有概念?
这主要是因为你学习的是具体的高并发架构知识,而不是学习一个完整的高并发系统如何设计,所以也就无法形成一个整体的系统架构设计思路。
《高并发架构实战:从需求分析到系统设计》的所有案例都是基于真实场景的,甚至有些案例本身就是由真实设计文档改编的。案例都是针对我们日常接触的各种高并发应用,比如微博、短视频、网约车、网盘、搜索引擎等,具体又分为高并发系统的海量数据处理架构、高性能架构、高可用架构以及安全架构。
在学习这些系统架构设计案例的时候,一方面可以学习各种应用系统如何进行整体设计,另一方面也可以学习高并发系统架构设计的模式和技巧,两者结合起来,就是一个完整的高并发系统设计的知识体系。
3.2 贴合工作场景的设计文档形式 你可能会觉得设计文档和自己关系不大:
一是平时不怎么写,也不愿意写,觉得写文档价值不大;二是自己不擅长写文档,觉得写也写不好,甚至不太知道设计文档该怎么写。 但工作了这么多年,我发现写东西可以帮助人更好地思考。
技术人员如果不写设计文档,就会缺少对技术的深刻思考,缺乏对技术方案的优点和缺点的系统认识,也就不知道如何找到更好的技术和更合理的方案。很显然,这会阻碍技术人员的职业发展。
不仅如此,如果不写设计文档,缺乏对技术的深度思考,那么开发出来的软件就缺乏创新,产品在市场上就缺乏竞争力。
可以粗暴一点地说:没有设计文档就没有设计,没有设计就没有技术的进步。
所以,本书将以软件设计文档的形式去展现一系列软件的系统架构设计,这些设计文档的风格是相对统一的。
希望你可以在这些“重复”的设计文档所展现的组织方式、软件建模与架构方式中,掌握一般的软件设计方法和软件设计文档的写作方法。
3.3 求同存异的典型系统架构案例 本书精挑细选了18个系统架构案例,这些案例大多是目前大家比较关注的高并发、高性能、高可用系统。
它们是高并发架构设计的优秀“课代表”,它们的技术可以解决现有的80%以上的高并发共性问题。
所以在阅读文档的过程中,你可以进一步学习与借鉴这些典型的分布式互联网系统架构,构建起自己的系统架构设计方法论,以指导自己的工作实践。
为了避免每篇文档中都出现大量重复、雷同的设计,本书在内容方面进行了取舍,精简了一些常规的、技术含量较低的内容,而尽量介绍那些有独特设计思想的技术点,尽可能做到在遵循设计文档规范的同时,又突出每个系统自己的设计重点。
此外,本书中还有一部分设计是针对大型应用系统的,比如限流器、防火墙、加解密服务、大数据平台等。
但需要强调一点,本书会针对这些知名的大厂应用重新进行设计,而不是分析现有应用是如何设计的。
一方面,重新设计完全可以按自己的意愿来,不管是设计方案还是需求分析、性能指标估算,都是一件很有意思的事;另一方面,因为现有应用中的某些关键设计并没有公开,我们要想讨论清楚这些高并发应用的架构设计,没有现成的资料,还是需要自己进行分析并设计。 所以很多案例的设计文档都有需求分析,用于估算重新设计的系统需要承载的并发压力有多大、系统资源需要多少,这些估算大多数都略高于现有大厂的系统指标。
希望你在阅读这些内容的时候,能够更真切地体会到架构师的“现场感受”:我评审、设计的这个系统将服务全球数十亿用户;
这个系统每年需要的服务器和网络带宽需要几十亿元;
这个系统宕机十几分钟,公司就会损失数千万元。
问题起因:通过gorm连接mysql数据库时产生标题的报错。
打开mysql,输入如下命令查看mysql数据库,mysql数据库存储了mysql自带的一些信息,例如用户、配置等信息
use mysql select user, plugin, authentication_string from user; 可以看到结果,除了root的插件是auth_socket之外,其余均为mysql_native_password
auth_socket插件的验证方式是不需要输入密码的,输入了密码也不会做安全验证,因为这种方式下默认只支持本地登陆,相当于已经通过了操作系统的安全验证。mysql_native_password模式即为利用密码来登录,对应的string即为密码加密后的内容
所以问题产生的原因是:数据库的root默认本身使用的是auth_socket插件,无法让远程连接通过。应该将其更改为另一种模式
update mysql.user set authentication_string=PASSWORD('自己的密码'),plugin='mysql_native_password' where user='root'; 其中PASSWORD()为mysql内置的一个加密函数,需要把这个加上才行
之后直接远程连接成功
用c#实现学生管理系统,使用的是vs2019 windows10
数据库源码 和 源代码
制作不易请点赞收藏加关注
本人微-信-公-众-号
【云日记Journal】
学生管理系统 导入数据库和获取链接池 可以查看这一篇文章
sqlserver链接字符串
- 创建数据库 CREATE DATABASE DATA_STU ON PRIMARY (NAME = 'DATA_STU', FILENAME = 'Z:\DATA\DATA_STU.MDF' , SIZE = 5MB, MAXSIZE = 20MB, FILEGROWTH = 20%) LOG ON (NAME ='DATA_STU_LOG', FILENAME = 'Z:\DATA\DATA_STU_LOG. LDF', SIZE = 5MB, MAXSIZE = 10MB, FILEGROWTH = 2MB) --使用数据库 USE DATA_STU; -- 创建表 --课程表 IF OBJECT_ID('Course_Info') IS NOT NULL DROP TABLE Course_Info CREATE TABLE Course_Info ( Id INT IDENTITY(1,1) PRIMARY KEY, Course_Name VARCHAR(50) NOT NULL, Credit INT NOT NULL, Teacher VARCHAR(50) NOT NULL ); -- 学生信息表 IF OBJECT_ID('Student_Info') IS NOT NULL DROP TABLE Student_Info CREATE TABLE Student_Info ( StudentId VARCHAR(20) PRIMARY KEY, Name VARCHAR(50) NOT NULL, Gender VARCHAR(10) NOT NULL, School VARCHAR(50), ); -- 成绩表 IF OBJECT_ID('Score_Info') IS NOT NULL DROP TABLE Score_Info CREATE TABLE Score_Info ( Id INT IDENTITY(1,1) PRIMARY KEY, StudentId VARCHAR(20) NOT NULL, Course_Id INT NOT NULL, Score DECIMAL(5,2) NOT NULL, FOREIGN KEY (StudentId) REFERENCES Student_Info (StudentId) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY (Course_Id) REFERENCES Course_Info (Id) ON DELETE CASCADE ON UPDATE CASCADE ); -- 考勤表 IF OBJECT_ID('Attendance_Info') IS NOT NULL DROP TABLE Attendance_Info CREATE TABLE Attendance_Info ( Id INT IDENTITY(1,1) PRIMARY KEY, Course_Name VARCHAR(50) NOT NULL, Student_Id VARCHAR(20) NOT NULL, Attendance_Date DATE NOT NULL, Attendance_Status VARCHAR(50) NOT NULL, CONSTRAINT FK_AttendanceInfo_StudentInfo FOREIGN KEY (Student_Id) REFERENCES Student_Info (StudentId) ); -- 账号 -- 学生账号 IF OBJECT_ID('Student_Account') IS NOT NULL DROP TABLE Student_Account CREATE TABLE Student_Account ( StudentId VARCHAR(20) PRIMARY KEY, Password VARCHAR(50) NOT NULL, CONSTRAINT FK_StudentAccount_StudentInfo FOREIGN KEY (StudentId) REFERENCES Student_Info (StudentId) ); select *from Student_Info; -- 管理员账号 IF OBJECT_ID('Admin_Account') IS NOT NULL DROP TABLE Admin_Account CREATE TABLE Admin_Account ( Id INT IDENTITY(1,1) PRIMARY KEY, Username VARCHAR(50) NOT NULL, Password VARCHAR(50) NOT NULL ); -- 排名表 IF OBJECT_ID('Ranking') IS NOT NULL DROP TABLE Ranking CREATE TABLE Ranking ( Ranking_Id INT PRIMARY KEY, StudentId VARCHAR(20), TotalScore FLOAT, Ranking INT, FOREIGN KEY (StudentId) REFERENCES Student_Info(StudentId) ); -- 向课程表中添加4个课程 INSERT INTO Course_Info (Course_Name, Credit, Teacher) VALUES ('Java', 4, 'Mr.
通过Streamsets采集mysql binglog增量数据时候,出现数据库中datetime时区问题。
要注意一点是,streamsets的前端展示的时间也是有时区的,后端返回的数据是时间戳,等于做了两次时区的转换
后端binglog时区转换->时间戳->前端时区转换(默认是CST时区),这部门的时区问题涉及到前端的修改,暂时不做,仅修改后端返回的时间戳时区问题
通过返回的接口查看,差了12个小时
通过查看streamsets源码可知,binglog用的采集为:mysql-binlog-connector-java GitHub - osheroff/mysql-binlog-connector-java: MySQL Binary Log connector
当前用的streamsets为3.23.0,对于版本为mysql-binlog-connector-java 0.23.4
查找相关的github issue,发现有人遇到了相同的问题
https://github.com/osheroff/mysql-binlog-connector-java/issues/13
其相关修改的代码为:https://github.com/shyiko/mysql-binlog-connector-java/pull/292/commits/5b29c33e0c8643ff3a7b6d315689ccead28b3782
按照其相关commit修改源代码在
AbstractRowsEventDataDeserializer类下 添加方法
private long convertLocalTimestamp(long millis) { TimeZone tz = TimeZone.getDefault(); Calendar c = Calendar.getInstance(tz); long localMillis = millis; int offset, time; c.set(1970, Calendar.JANUARY, 1, 0, 0, 0); // Add milliseconds while (localMillis > Integer.MAX_VALUE) { c.add(Calendar.MILLISECOND, Integer.MAX_VALUE); localMillis -= Integer.MAX_VALUE; } c.add(Calendar.MILLISECOND, (int)localMillis); // Stupidly, the Calendar will give us the wrong result if we use getTime() directly.
从今天开始,整个暑假期间。我将不定期给大家带来有关各种算法的题目,帮助大家攻克面试过程中可能会遇到的算法这一道难关。
目录
(一) 基本概念
(二)题目讲解
1、难度:easy
1️⃣移动零
2️⃣复写零
2、难度:medium
1️⃣快乐数
2️⃣盛⽔最多的容器
3、难度:difficult
2️⃣最大得分
总结
(一) 基本概念 双指针算法是一种常用的算法技巧,它通常用于在数组或字符串中进行快速查找、匹配、排序或移动操作。双指针算法使用两个指针在数据结构上进行迭代,并根据问题的要求移动这些指针。
常⻅的双指针有两种形式:
⼀种是对撞指针;⼀种是左右指针。
对撞指针:⼀般⽤于顺序结构中,也称左右指针。
• 对撞指针从两端向中间移动。⼀个指针从最左端开始,另⼀个从最右端开始,然后逐渐往中间逼近。
• 对撞指针的终⽌条件⼀般是两个指针相遇或者错开(也可能在循环内部找到结果直接跳出循环),也就是:
◦ left == right (两个指针指向同⼀个位置)
◦ left > right (两个指针错开)
快慢指针:⼜称为⻳兔赛跑算法,其基本思想就是使⽤两个移动速度不同的指针在数组或链表等序列结构上移动。
这种⽅法对于处理环形链表或数组⾮常有⽤。
其实不单单是环形链表或者是数组,如果我们要研究的问题出现循环往复的情况时,均可考虑使⽤快慢指针的思想。
快慢指针的实现⽅式有很多种,最常⽤的⼀种就是:
• 在⼀次循环中,每次让慢的指针向后移动⼀位,⽽快的指针往后移动两位,实现⼀快⼀慢
【优势】 双指针算法的优势在于它们能够在一次迭代中完成操作,时间复杂度通常比较低,并且不需要额外的空间;通过合理地移动指针,可以有效地减少不必要的计算和比较,提高算法的效率。 在具体应用双指针算法时,需要根据问题的特点和要求选择合适的指针移动策略,确保算法的正确性和高效性。同时,注意处理边界条件和特殊情况,以避免错误和异常。
(二)题目讲解 接下来,我们通过几道题目让大家具体的感受一下。(题目由易到难)
1、难度:easy 1️⃣移动零 链接如下:283. 移动零
【题⽬描述】
【解法】(快排的思想:数组划分区间-数组分两块)
算法思路:
在本题中,我们可以⽤⼀个 cur 指针来扫描整个数组,另⼀个 dest 指针⽤来记录⾮零数序列的最后⼀个位置。根据 cur 在扫描的过程中,遇到的不同情况,分类处理,实现数组的划分。在 cur 遍历期间,使 [0, dest] 的元素全部都是⾮零元素, [dest + 1, cur - 1] 的元素全是零 【算法流程】
延时任务 1.实现技术栈 RedisMQ 我们选用Redis
2.创建表 表1 任务日志表表2 任务表 CREATE TABLE `taskinfo_logs` ( `task_id` bigint(20) NOT NULL COMMENT '任务id', `execute_time` datetime(3) NOT NULL COMMENT '执行时间', `parameters` longblob NULL COMMENT '参数', `priority` int(11) NOT NULL COMMENT '优先级', `task_type` int(11) NOT NULL COMMENT '任务类型', `version` int(11) NOT NULL COMMENT '版本号,用乐观锁', `status` int(11) NULL DEFAULT 0 COMMENT '状态 0=初始化状态 1=EXECUTED 2=CANCELLED', PRIMARY KEY (`task_id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; CREATE TABLE `taskinfo` ( `task_id` bigint(20) NOT NULL COMMENT '任务id', `execute_time` datetime(3) NOT NULL COMMENT '执行时间', `parameters` longblob NULL COMMENT '参数', `priority` int(11) NOT NULL COMMENT '优先级', `task_type` int(11) NOT NULL COMMENT '任务类型', PRIMARY KEY (`task_id`) USING BTREE, INDEX `index_taskinfo_time`(`task_type`, `priority`, `execute_time`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; 3.
概览 Flutter本质上是一个跨平台的UI工具集,允许在各自操作系统上复用同样的代码。
尽可能提供原生体验的高性能和复用代码。
开发中,Flutter应用在一个VM上运行,使得可在保留状态且无需重新编译情况下,进行热加载。
发行时,Flutter应用会直接通过AOT编译为机器码或者是JS。
分层模型 Flutter是一个可拓展的分层系统,可被视为各个独立组件的集合,上层组件依赖下层,上层无法越界访问更下层的组件,框架内各部分是可选可替代的。
分为框架、引擎、嵌入层
嵌入层 对于底层操作系统,Flutter应用程序的包装方式与其他原生应用相同,每个平台都会包含一个特定的嵌入层,提供一个程序入口,使得程序可以与底层操作系统进行协调、访问服务和管理事件循环队列。
对于不同平台,嵌入层使用的语言都不一样。Flutter代码可以作为模块集成到现有应用或作为应用主体。
引擎 主要使用C++编写,提供Flutter应用所需原语。
当需要绘制新一帧内容时,引擎将负责对需要合成的场景进行栅格化。
其提供Flutter核心API的底层实现:图形、文本布局等…
引擎将底层C++代码包装成Dart代码,通过dart:ui暴露给Flutter框架层。该库暴露了最底层的原语,包括用于驱动输入,图形等子系统的类
框架 开发者通过Flutter框架和Flutter交互,该框架提供了以Dart语言编写的现代响应式框架。
自下而上有:
Foundational and Annimation、Painting、Gestures Foundational:基础类
Annimation:动画
Painting:绘画
Gestures:手势
向上层提供常用的抽象
渲染层 提供操作布局的抽象,操作层使得可以构建一颗可渲染对象的树,可动态更新。
Widget 组合的抽象,每个渲染层中的渲染对象在widget层中有一个对应的类。
widget层可让你自由组合需要复用的各种类,引入了响应式编程模型。
Material和Cupertino 提供了全面的widget层的原语组合,分别实现了Material和IOS设计规范。
其他更高层级的功能被拆分到不同的软件包中。
应用剖析 Dart应用:将Widget合成预期的UI,实现业务。框架:提供API封装,将应用widget树构建在一个Scene中。引擎:将合成的Scene进行栅格化、封装Flutter进行封装,暴露功能给dart:ui API给框架、使用嵌入层API与平台进行整合。嵌入层:协调底层操作系统的服务、管理事件循环体系、暴露特定平台API给应用集成嵌入层。运行器:将嵌入层暴露的平台API合成为目标平台可运行的应用包。 响应式用户界面 Flutter是一个响应式的且伪声明式的UI框架,
随widget构造方法引入的新输入会随着其build方法传播给更低等级的widget;
而底层的widget中出现的修改也会沿着结构树通过event handler向上传播。
函数-响应式、指令-响应式都有出现,
前者是指widget的build方法中只包含其针对变化如何响应的表达式,
后者则包含一系列构造子元素的表达式,用于描述该widget如何响应变化。
Flutter,widget用来配置对象树的不可变类,这些widget管理单独的布局对象树,接着参与管理合成的布局对象树。
Flutter核心是一套高效的遍历树的变动的机制,将对象树转换为更底层的对象树,在树间传递更改。
build将状态转换为UI,在框架需要都可以被调用,可快速执行且没有额外影响,依赖DART的运行时特征:对象的快速实例化和清除。
Widgets Flutter强调以widgets为组成单位。widgets是构建flutter应用界面的基础块,每个widget都是一部分不可变的UI声明。
widget通过布局组合形成一种层次结构关系,每个widget都嵌套在其父级的内部,可以通过父级接收上下文。从根布局(MaterialApp或CupertinoApp)开始,自上而下。
应用根据事件交互,通知框架替换层级中的旧widget为新的widget,比较新旧widget,高效更新。
Flutter拥有自己的UI控制实现,不使用系统自带。
这样提供了无限拓展性,不受系统提供的拓展限制。
Flutter可直接合成所有的场景,避免与原生平台来回切换,避免了性能瓶颈。
将应用的行为与操作系统的依赖解耦,实现不同平台,体验一致。
组成 widget通常由更小的且用途单一的widget组合而成,提供更强大的功能。
Flutter 在widget层中使用了widget来表示屏幕上的绘制、布局等
Flutter 在动画层,Animation和Tween涵盖了大部分的设计空间
Flutter 在渲染层,RenderObject用来描述布局、绘制、触摸判断等
Widget思想是 浅而广,最大限度地增加可能的组合数量,每个widget完成一件事,将核心功能抽象,如边距等基础功能,被实现为单独的组件
构建widget build方法会返回一个新的元素树,这棵树更具体地表示了widget在ui中的部分。
1. 默认配置 可通过org.springframework.boot.autoconfigure.web.ServerProperties查看,其中包括属性tomcat、jetty、undertow三种服务器的设置,默认启用tomcat。
# tomcat 8 server: tomcat: max-connections: 10000 #最大连接数,默认为10000 accept-count: 100 # 最大连接等待数,默认100 max-threads: 200 #最大工作线程数,默认200 min-spare-threads: 10 #最小工作线程数,默认10 # tomcat 9 server: tomcat: max-connections: 8192 accept-count: 100 threads: max: 200 min-spare: 10 详解:maxConnections、maxThreads、acceptCount 每一次HTTP请求到达Web服务器,Web服务器都会创建一个线程来处理该请求
min-spare-threads: 最小备用线程数,tomcat启动时的初始化的线程数,默认10。(适当增大一些,以便应对突然增长的访问量) max-threads: Tomcat可创建的最大工作线程数,默认200, 每一个线程处理一个请求,超过这个请求数后,客户端请求只能排队,等有线程释放才能处理。(4核8g内存,线程数800,一般是 核数*200 。操作系统做线程之间的切换调度是有系统开销的,所以不是越多越好。) accept-count: 当调用Web服务的HTTP请求数达到tomcat的最大线程数时,还有新的HTTP请求到来,这时tomcat会将该请求放在等待队列中,这个acceptCount就是指能够接受的最大等待数,默认100。 如果等待队列也被放满了,这个时候再来新的请求就会被tomcat拒绝(connection refused),队列也做缓冲池用,但也不能无限长,不但消耗内存,而且出队入队也消耗CPU。 max-connections: 这个参数是指在同一时间,tomcat能够接受的最大连接数。一般这个值要大于(max-threads)+(accept-count)。 tomcat的最大线程数,最大排队数多少合适 1、Tomcat默认的HTTP实现是采用阻塞式的Socket通信,每个请求都需要创建一个线程处理,当一个进程有500个线程在跑的话,那性能已经是很低很低了。Tomcat 默认配置的最大请求数是150,也就是说同时支持150个并发。 2、SpringBoot内置Tomcat,在默认设置中,Tomcat的最大线程数是 200,最大连接数是 10000。支持的并发量是指连接数。Tomcat有两种处理连接的模式,一种是 BIO,一个线程只处理一个连接,另一种就是 NIO,一个线程处理多个连接。 3、启动tomcat。进入apache-tomcat-0.0.M3下的bin目录,双击startup.bat 在浏览器中的输入10.1:8080,回车。查看tomcat是否启动成功。看到熟悉的小猫,启动成功了!查看tomcat服务器的最大连接数。 4、在tomcat配置文件server.xml中的Connector /配置中,和连接数相关的参数有:maxThreads=150 表示最多同时处理150个连接,Tomcat使用线程来处理接收的每个请求。这个值表示Tomcat可创建的最大的线程数。默认值200。 5、maxSpareThreads:最大空闲线程数,如果超过这个值,会关闭无用的线程。acceptCount:当处理请求超过此值时,将后来请求放到队列中等待。 6、 最大线程数设置多少合适和tomcat的运行环境有关的,比如硬件,内存等等,适当可以给tomcat的运行最大分配的内存加大点。另外,用一些工具: 比较ab, loadrunner做做压力测试。 2. Tomcat经验值 max-threads线程数的经验值为:
1 我是直接使用
string sqlConToWindows = “server=服务名;database=数据库名;Trusted_Connection=SSPI”; 这里只需要把服务名和数据库名更换成你自己的就行。
这就是数据库名称了
2 Data Source=数据库地址;Initial Catalog=数据库名称;User Id=数据库登录名;Password=数据库密码;[Integrated Security=SSPI | true]; Integrated Security参数
表示采用数据库的windows身份验证模式,当Integrated Security=true是,设置签名的user id和password参数不起作用。
Integrated Security=SSPI相当于Integrated Security=true,该参数可省略。
3 Server=数据库地址;Database=数据库名称;User ID=数据库登录名;Password=数据库密码;[Trusted_Connection=False | true]; Trusted_Connection参数 当值为true时表示采用数据库的windows身份验证模式,值为false或省略时表示需要用户名密码登录。
这是一个试题管理的系统,功能不怎么多,但是够用,可以加入试题,还有用户的身份验证登录界面,第一步配置的话一定要链接上自己的数据库,我这里用的是sqlserver
链接数据库 -- 创建数据库 CREATE DATABASE EXAM_SYSTEM ON PRIMARY (NAME = 'EXAM_SYSTEM', FILENAME = 'Z:\DATA\EXAM_SYSTEM.MDF' , SIZE = 5MB, MAXSIZE = 20MB, FILEGROWTH = 20%) LOG ON (NAME ='EXAM_SYSTEM_LOG', FILENAME = 'Z:\DATA\EXAM_SYSTEM_LOG. LDF', SIZE = 5MB, MAXSIZE = 10MB, FILEGROWTH = 2MB) USE EXAM_SYSTEM; -- 试题表:question DROP table question CREATE TABLE question ( id INT NOT NULL PRIMARY KEY, content VARCHAR(500) NOT NULL, option_a VARCHAR(200) NOT NULL, option_b VARCHAR(200) NOT NULL, option_c VARCHAR(200) NOT NULL, option_d VARCHAR(200) NOT NULL, answer VARCHAR(200) NOT NULL, score INT NOT NULL ); INSERT INTO question(id,content,option_a,option_b,option_c,option_d,answer,score) VALUES('4','云边有个小卖部,作者是谁:','杜甫','李白','额嗡嗡','张嘉佳','张嘉佳','2'); --填充试题表 INSERT INTO question VALUES (1, '1+1=?', '2', '1', '0', '0', '2', 2); INSERT INTO question VALUES (2, '2+2=?', '3', '4', '5', '2', '4', 2); INSERT INTO question VALUES (3, '今天是星期几?', '星期一', '星期二', '星期三', '星期四', '星期一', 1); -- 试卷表:paper CREATE table paper ( id INT NOT NULL PRIMARY KEY, title VARCHAR(100) NOT NULL, subject VARCHAR(50) NOT NULL, author VARCHAR(20) NOT NULL, created_at DATETIME NOT NULL, status INT NOT NULL ); -- 填充试卷表 INSERT INTO paper VALUES (1, '数学期末考试', '数学', '张三', '2021-12-30 12:00:00', 1); INSERT INTO paper VALUES (2, '英语期末考试', '英语', '李四', '2021-12-31 13:00:00', 0); -- 试卷-试题关系表:paper_question CREATE TABLE paper_question ( id INT NOT NULL PRIMARY KEY, paper_id INT NOT NULL, question_id INT NOT NULL, FOREIGN KEY (paper_id) REFERENCES paper(id), FOREIGN KEY (question_id) REFERENCES question(id) ); --填充试卷关系表 INSERT INTO paper_question VALUES (1, 1, 1); INSERT INTO paper_question VALUES (2, 1, 2); INSERT INTO paper_question VALUES (3, 2, 3); -- 用户表:user CREATE TABLE user_info( id INT NOT NULL PRIMARY KEY, username VARCHAR(20) NOT NULL, password VARCHAR(20) NOT NULL, role INT NOT NULL ); -- 用户填充信息 INSERT INTO user_info VALUES (1, 'admin', 'admin123', 0); INSERT INTO user_info VALUES (2, 'teacher', 'teacher123', 1); INSERT INTO user_info VALUES (3, 'student1', 'student123', 2); INSERT INTO user_info VALUES (4, 'student2', 'student234', 2); INSERT INTO user_info VALUES (5, 'student3', 'student345', 2); 用sqlserver如何查看自己的链接字符串?我的方法是这样的:
卸载MySQL
右击【计算机/此电脑】——管理——双击【服务和应用程序】——选择【服务】
找到MySQL后右击停止
打开控制面板——卸载程序——卸载MySQL
下载MySQL
MySQL地址:MySQL :: Download MySQL Community Server
下载完成后,解压文件
我将文件放在C:\mysql-8.0.33-winx64\bin
打开文件,在该文件下新增一个配置文件:my.ini
在my配置文件中配置以下基本信息
键盘输入WIN+R,打开cmd,切换目录
cd C:\mysql-8.0.33-winx64\bin【ps:这是mysql的安装地址】
初始化数据库
mysqld --initialize --console
红框圈起来的就是初始密码,后续登陆需要用到,也可以在登录后修改密码。
启动MySQL
net start mysql
发现报错:服务没有报告任何错误
输入netstat -ano
发现3306的端口被占用了,PID为17004
使用TASKKILL /PID +PID来结束进程
ps:如果使用上面指令还无法结束进程,可以使用强行指令TASKKILL /F /PID +PID
再次输入net start mysql,服务启动成功
登录MySQL
输入mysql -u root -p,点击回车,出现Enter password字样后输入初始密码,看到welcome和mysql>闪着光标的样子即登录成功 重置密码
输入 ALTER USER root@localhost identified by '7476';
输入 exit 或 quit 退出登录。
配置MySQL的环境变量
【此电脑/计算机】——属性——高级系统设置——环境变量——新建系统变量
双击path,新增
<template> <div> <el-table :data="tableData"> <el-table-column prop="name" label="姓名"></el-table-column> <el-table-column prop="age" label="年龄"></el-table-column> <el-table-column label="操作"> <template slot-scope="scope"> <el-button size="mini" @click="editItem(scope.row)">编辑</el-button> <el-button size="mini" @click="removeItem(scope.row)">删除</el-button> </template> </el-table-column> </el-table> <el-dialog :visible="dialogVisible" title="编辑" @close="closeDialog"> <el-form ref="form" :model="editForm" label-width="80px"> <el-form-item label="姓名" prop="name"> <el-input v-model="editForm.name"></el-input> </el-form-item> <el-form-item label="年龄" prop="age"> <el-input v-model="editForm.age"></el-input> </el-form-item> </el-form> <div slot="footer" class="dialog-footer"> <el-button @click="closeDialog">取消</el-button> <el-button type="primary" @click="saveItem">保存</el-button> </div> </el-dialog> <el-button type="primary" @click="addItem">添加</el-button> </div> </template> <script> import axios from 'axios'; export default { data() { return { tableData: [], dialogVisible: false, editForm: {} }; }, created() { this.
文章目录 简介一、直接遍历数据设值导出所需依赖controller代码service代码调用接口测结果 二、通过注解的方式导出所需依赖controller代码service代码模板类AgentTplExcelExport.classExcelHead.classExcelImport.classExcelUtils 工具类: 三、基于模板的方式导出所需依赖TemplateExcelUtils 工具类:excel模板controller代码service代码测试结果 简介 平时我们业务开发经常少不了接触导出功能,可以说有列表查询的地方,基本都会用到导出。本章内容主要介绍平时开发中导出的基本逻辑和一些导出方式,用以记录和总结。
我们处理导出的逻辑一般都是需要先取出数据,得到一个数据集合,然后将数据遍历指明每个数据需要放到文件的哪个位置,最后再将文件流上传服务器或者返回客户端。一般导出方式的处理细节差异 ,主要就是处理数据映射文件位置这一步骤。这里总结了一些经常用到的导出方式,常见的有用
1、直接遍历数据设值导出
2、注解的方式导出,创建一个类,在定义的属性上加上对应的注解,即可完成映射导出
3、另外一种是预先创建好一个excel模板,在模板文件里面对应的位置加上对应的字符占位,即可完成映射导出。
一、直接遍历数据设值导出 所需依赖 <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>4.1.2</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>4.1.2</version> </dependency> controller代码 @RestController @RequestMapping("/statistics") public class TestExportExcel { @Resource private TestExportExcelService testExportExcelService; @PostMapping(value = "/export/excel", produces = MediaType.APPLICATION_JSON_VALUE) public Boolean exportExcel(HttpServletResponse response) { testExportExcelService.testExportExcel(response); return true; } } service代码 import com.cys.share.service.TestExportExcelService; import org.apache.commons.codec.Charsets; import org.apache.poi.ss.usermodel.*; import org.apache.poi.xssf.usermodel.XSSFWorkbook; import org.springframework.http.HttpHeaders; import org.springframework.stereotype.Service; import javax.servlet.http.HttpServletResponse; import java.io.IOException; import java.
PlayCover是一套完整的在 macOS 上运行 iOS 程序的辅助软件,PlayCover能够非常方便地在 M1 Mac 上面通过解密的 IPA 来安装 iOS 应用;有着完整的键盘快捷键映射和鼠标操作映射,且支持快捷键映射导出导入。
为什么要把iPhone软件装到Mac电脑中?
1、iOS独占软件
2、Mac版功能精简,iOS版功能更全
3、玩iOS游戏
4、iOS软件演示等
玩原神的朋友可能会更熟悉这款软件,叫做:playcover。
这个软件只有5M左右,只要把ipa安装包(iOS软件)拖进playcover,就可以直接运行了。对想用Mac电脑玩手游的朋友来说,它最大的作用是支持键盘映射;而在工作中,在电脑端查看或演示一些iOS独占的软件,也有不小的便利。
如果你和我一样最近才开始常用Mac电脑,不妨把playcover作为一款必装软件。
playcover for mac安装教程 playcover下载完成后打开,拖动左侧的PlayCover到右侧应用程序中即可。
let edges = new THREE.EdgesGeometry( tWall.mWallMesh.geometry );
tWall.m_Outline = new THREE.LineSegments( edges, new THREE.LineBasicMaterial( { color: 0x4b96ff,depthTest:false,transparent:true } ) );
GlobalApi.scene3D.add( tWall.m_Outline );
uniapp运行项目报错less未安装,到插件中心安装后,报错安装失败,npm install失败,此时找到hbuilder存放位置,并找到下面的plugons文件夹,查看less对应的文件夹里否有node module文件夹,若没有,则在less文件夹里执行npm i即可
一、快速安装Apache 1.1安装 [root@server ~]# yum install httpd 1.2预处理 [root@server ~]# setenforce 0 [root@server ~]# systemctl stop firewalld [root@server ~]# systemctl start httpd [root@server ~]# systemctl enable httpd 1.3 分析 内容位置服务目录/etc/httpd配置文件/etc/httpd/conf/httpd.conf网站数据目录/var/www/html访问日志/var/log/httpd/access_log错误日志/var/log/httpd/error_log 1.3.1 主配置文件 [root@server ~]# vim /etc/httpd/conf/httpd.conf 34 ServerRoot "/etc/httpd" ---服务目录 46 #Listen 12.34.56.78:80 ----设置监听的IP地址及端口 47 Listen 80 ----默认开启监听端口为80 61 Include conf.modules.d/*.conf ----加载额外配置文件 71 User apache ----运行服务的用户 72 Group apache ----运行服务的工作组 91 ServerAdmin root@localhost ----管理者的邮箱 100 #ServerName www.example.com:80 ----设置域名及端口号,必须要域名解析 107 <Directory /> #<>表示起始标志 </>表示结束标志 108 AllowOverride none #不允许覆盖 109 Require all denied #禁止所有来源访问文件或目录 110 </Directory> 124 DocumentRoot "
适用于Mac的Microsoft远程桌面测试版!Microsoft Remote Desktop Beta for Mac是一种远程工具,允许用户从Mac远程访问基于Windows的计算机。使用此工具,用户可以随时随地使用Mac连接到远程桌面、应用程序和资源。
Microsoft Remote Desktop Beta for Mac提供了一个现代直观的用户界面,该界面已针对macOS进行了充分优化。它支持多个同时连接,允许用户在不同的远程桌面和应用程序之间轻松切换。
Microsoft Remote Desktop Beta for Mac的主要功能之一是支持各种基于Windows的应用程序,包括Microsoft Office、Visual Studio和Adobe Creative Suite。用户可以远程访问这些应用程序,并像在Mac上本地运行一样使用它们。
总体而言,Microsoft Remote Desktop Beta for Mac是一款功能强大的工具,通过提供从Mac远程访问基于Windows的计算机和应用程序,帮助用户提高生产力和灵活性。
Microsoft Remote Desktop安装教程
安装包下载完成后,拖动左侧的`Microsoft Remote Desktop Beta`到右侧应用程序中即可
文件传送协议(FTP协议) 一、FTP协议的概述 文件传送协议(File Transfer Protocol)是互联网上使用的最广泛的文件传输协议,用于Internet上的控制文件的双向传输。TP提供交互式的访问,允许客户指明文件类型与格式,并允许文件具有存取权限。FTP屏蔽了各计算机系统的细节,因而适合于在异构网络中计算机之间传送文件 二、FTP协议的特点 文件传送协议FTP只提供文件传送的一些基本的服务,它使用TCP可靠的运输方式。FTP的主要功能是减少或消除在不同操作系统下处理文件的不兼容性。FTP使用客户服务器方式。一个FTP服务器进程可同时为多个客户进程提提供服务,FTP的服务器进程由二大部分组成:一个是主进程,负责接受新的请求;另外有诺干个从属进程,负责处理单个请求。实现FTP文件上传与下载的两种方式 三、 FTP的工作过程 1.FTP使用的两个TCP连接(如下图所示) FTP使用客户服务器方式。一个 FTP服务器进程可同时为多个客户进程提供服务。FTP的服务器进程由两大部分组成:一个主进程,负责接受新的请求;另外由若干个从属进程,负责处理单个请求。主进程工作步骤如下: ①打开熟知端口(端口号为21),使客户进程能够连接上。
②等待客户进程发出连接请求。
③启动从属进程来处理客户进程发来的请求。从属进程对客户进程的请求处理完毕后即 终止,但从属进程在运行期间根据需要还可能创建其他一些子进程。
④回到等待状态,继续接受其他客户进程发来的请求。主进程与从属进程的处理是并发 地进行。
四、实现FTP文件上传与下载的两种方式 通过JDK自带的API实现通过Apache提供的API实现 代码实现前的准备工作 首先打开Ftpconsole.exe文件,找到账号管理,并新建一个用户
在新建账号中输入自己的用户名以及密码,并选择你所需要的权限。打开Ftpconsole.exe后你能够看见主机名称和主机IP,以及FTP服务端口和Web服务端口
可以看到主机IP有三个,那是因为电脑中含有虚拟机,可以在控制面板中找到网络和 Internet选择网络连接,右键禁用虚拟机
准备好这些工作后,在文件夹下导入所需要用的jar包
代码实现过程 一、连接FTP服务器,显示文件列表 package com.apesource.demo; import java.io.IOException; import java.net.SocketException; import java.text.SimpleDateFormat; import java.util.Date; import org.apache.commons.net.ftp.FTPClient; import org.apache.commons.net.ftp.FTPFile; //连接FTP服务器,显示文件列表 public class Demo01 { public static void main(String[] args) { try { //第一步:连接FTP服务器并验证用户名密码 FTPClient ftpClient = new FTPClient(); ftpClient.connect("192.168.142.1",21); //ftpClient.connect("本机地址",21) ftpClient.login("xxx", "*****"); //ftpClient.login(userName,PassWord) //第二步 boolean isChange = ftpClient.
一、json字符串转换为json对象 1、使用eval
result = eval('(' + jsonstr + ')'); // jsonstr是json字符串 2、使用JSON.parse() result = JSON.parse(jsonstr); // jsonstr是json字符串 eval和JSON.parse()的区别 eval 是javascript支持的方式,不需要严格的json格式的数据也可以转化
JSON.parse 是浏览器支持的转换方式,必须要标准的json格式才可以转换
二、判断数组内是否存在某一项 findIndex()顾名思义,查找符合条件的值并返回其索引(返回值为-1表示不存在满足条件的值),通过判断返回值对其进行下一步操作
indexOf()从头开始寻找是否存在符合条件的字符串,返回值为-1表示不存在
//方法一:通用 xx(Arr,date){ // 返回值等于-1 说明数组Arr中不存在id为date的对象 if( Arr.findIndex(item => item.id=== date )!==-1){ ... } } //方法二:当数组里的对象为字符串时用这个方法更简单 xx(Arr,date){ // 返回值等于-1 说明数组Arr中不存在id为date的对象 if( Arr.indexOf(date)!==-1 ){ ... } }
一、框架推出的背景
1.springcloud组件停止维护,急需孵化新项目
spring cloud中的几乎所有的组件都使用Netflix公司的产品,然后在其基础上做了一层封装。然而Netflix的服务发现组件Eureka已经停止更新;而其他的众多组件Ribbon、Zuul、Hystrix会在2020年停止维护。
2.阿里为整合dubbo和springcloud申请进入孵化
在alibaba springcloud推出之前,若项目想由dubbo转成springcloud框架,工作量比较大,微服务调用方式不一样,注册中心也不一样。
阿里为了整合自家产品,也进一步提升开发和运维效率, 便推出alibaba springcloud。
强大的nacos,sentinel新组件,
基于http和rpc的微服务都是用同一个注册中心,框架更加灵活,
使用dubbo框架的旧项目可快速迁移,
等等优点,受到开发者的欢迎。
最后,alibaba springcloud孵化成功,成为springcloud的子项目
alibaba springcloud 组件:
Sentinel:把流量作为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Nacos:一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
RocketMQ:一款开源的分布式消息系统,基于高可用分布式集群技术,提供低延时的、高可靠的消息发布与订阅服务。
Dubbo:Apache Dubbo 是一款高性能 Java RPC 框架。
Seata:阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案。
Alibaba Cloud OSS: 阿里云对象存储服务(Object Storage Service,简称 OSS),是阿里云提供的海量、安全、低成本、高可靠的云存储服务。您可以在任何应用、任何时间、任何地点存储和访问任意类型的数据。
Alibaba Cloud SchedulerX: 阿里中间件团队开发的一款分布式任务调度产品,提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。
Alibaba Cloud SMS: 覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
二、alibaba springcloud和springcloud技术栈对比
三、相关组件介绍
Nacos :发现、配置和管理微服务(下线、负责均衡权重等)
服务发现和服务健康监测
动态配置服务
动态 DNS 服务
服务及其元数据管理
官网介绍 https://nacos.io/zh-cn/docs/what-is-nacos.html
以下暂不介绍:
路由: gateway
sentinel 流量控制,断路 文档
apache-skywalking-apm-bin 链路跟踪
Rocketmq 的使用
1安装cmake以及依赖库
$ sudo apt-get install cmake
$ sudo apt-get install build-essential libgtk2.0-dev libavcodec-dev libavformat-dev libjpeg.dev libtiff4.dev libswscale-dev libjasper-dev
2安装opencv(若下载的是OpenCV3.4.0版本)
$ tar -zxvf opencv-3.4.0.tar.gz
$ cd opencv-3.4.0
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local -D CUDA_GENERATION=Kepler …
$ sudo make -j4
$ sudo make install
3.把opencv的so库加入到环境变量
$ sudo gedit /etc/ld.so.conf.d/opencv.conf //没有则新建
末尾加入/usr/local/lib,保存退出
$ sudo ldconfig #使配置生效
打开/etc/bash.bashrc;
$ sudo gedit /etc/bash.bashrc
export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig
加到文件末尾,保存退出
$ source /etc/bash.
前言
在网络爬虫开发中,使用代理IP是非常常见的技巧。代理服务器可以让我们的爬虫请求伪装成其他的用户或者其他地点的请求,达到防止被反爬虫或者加速爬虫请求的效果。
Python作为一门强大的编程语言,也提供了很多方法来使用代理IP。下面,我将就如何在Python中使用代理IP进行详细的阐述,并举例说明。
1.方法一:使用urllib模块 Python中最基础的网络请求是使用urllib模块,我们可以利用它来使用代理IP。在使用urllib时,我们需要使用ProxyHandler类来处理代理信息,代码如下:
import urllib.request # 设置代理IP proxy_ip = "http://127.0.0.1:8888" # 构造代理处理器对象 proxy_handler = urllib.request.ProxyHandler({"http": proxy_ip}) # 构造一个自定义的opener对象 opener = urllib.request.build_opener(proxy_handler) # 使用自定义的opener对象发起访问请求 response = opener.open("http://www.baidu.com") # 打印请求结果 print(response.read().decode("utf-8")) 在以上代码中,我们使用了proxy_ip来设置代理IP,使用ProxyHandler来构造代理处理器对象,使用build_opener来构造一个自定义的opener对象,并使用opener对象来发起请求。如果需要设置HTTPS代理IP,只需要将"http"改为"https"即可。
2.方法二:使用requests模块 在Python中最常用的网络请求模块是requests,因为它非常易用和方便。我们也可以利用它来使用代理IP,代码如下:
import requests # 设置代理IP proxy_ip = "http://127.0.0.1:8888" # 设置代理信息 proxies = {"http": proxy_ip} # 发起请求 response = requests.get("http://www.baidu.com", proxies=proxies) # 打印请求结果 print(response.text) 在以上代码中,我们同样使用了proxy_ip来设置代理IP,使用proxies来设置代理信息,并使用requests.get方法来发起请求。如果需要设置HTTPS代理IP,只需要将"http"改为"https"即可。
3.方法三:使用selenium模块 在某些情况下,我们需要使用selenium来模拟浏览器操作。在这种情况下,我们同样可以使用代理IP。代码如下:
from selenium import webdriver # 设置代理IP proxy_ip = "127.0.0.1:8888" # webdriver设置代理信息 chrome_options = webdriver.