计算机等级考试一级WPS试题及答案
一、选择题
1、计算机中数据的表示形式是
A)八进制
B)十进制
C)二进制
D)十六进制
【参考答案】:C
2、硬盘工作时应特别注意避免
A)噪声
B)震动
C)潮湿
D)日光
【参考答案】:B
3、针式打印机术语中,24针是指
A)24x24点阵
B)信号线插头有24针
C)打印头内有24x24根针
D)打印头内有24根针
【参考答案】:D
4、下面列出的四种存储器中,易失性存储器是
A)RAM
B)ROM
C)PROM
D)CD-ROM
【参考答案】:A
5、办公自动化是计算机的一项应用,按计算机应用的分类,它属于
A)科学计算
B)实时控制 www.Examda.CoM
C)数据处理
D)辅助设计
【参考答案】:C
6、I/O接口位于
A)总线和设备之间
B)CPU和I/O设备之间
C)主机和总线之间
D)CPU和主存储器之间
【参考答案】:A
7、计算机硬件能直接识别和执行的只有
A)高级语言
B)符号语言
C)汇编语言
D)机器语言
【参考答案】:D
8、具有多媒体功能的微型计算机系统中,常用的CD-ROM是
A)只读型大容量软盘
B)只读型光盘
C)只读型硬盘
D)半导体只读存储器
【参考答案】:B
9、微机中1K字节表示的二进制位数是
A)1000
B)8x1000
C)1024
D)8x1024
【参考答案】:D
10、下列字符中,ASCII码值最小的是
A)a
B)A
C)x
D)Y
【参考答案】:B
11、Windows 95操作系统是一个
A)单用户多任务操作系统
B)单用户单任务操作系统
C)多用户单任务操作系统
D)多用户多任务操作系统
传统的网线主要用于台式机,笔记本电脑最大的特点就是可移动性强,可以通过无线网络连接,摆脱网线的束缚。笔记本电脑都内置无线网卡,打开无线开关之后,通常就可以搜索到wifi信号,不过有用户使用win7笔记本搜索无线网络信号,发现搜不到,出现这个问题可能是无线服务未开启所致,这边小编跟大家介绍win7笔记本系统搜索不到无线网络信号的解决方法。
笔记本无线网络连接条件:
1、有知道密码的wifi信号
2、开启无线网卡
3、开启无线开关,一般是Fn+F*,在F1-F12之间找,有个wifi图标的键就是
4、开启无线服务
解决步骤如下:
1、前面三个都好解决,开启无线服务可能会遗漏,按组合键(win+R)打开运行窗口,然后输入“service.msc”并回车确认;
2、打开服务窗口后,在服务列表中找到并双击“WLAN AutoConfig”;
3、在弹出的属性设置窗口中,点击切换到“常规”标签,在启动类型设置下拉框中选择“自动”,建议设置自动,防止忘记启动它,然后点击“应用--确定”按钮保存修改即可。
重启电脑,这时候应该就可以搜索到无线网络信号了,如果你也遇到搜不到无线网络信号的问题,排查一下是否是忘记开启无线服务。
C语言实现的通讯录管理系统。
设计一个学生通信录,学生通迅录数据信息构成内容可自行设计(如:学号、姓名、电话号码、所在班级、寝室地址等),通信录数据类型定义为结构体类型。
主要实现功能包括:
(1)创建学生通讯录
(2)修改学生通讯录
(3)增删学生通讯录
(4)能够按多种方式进行查询(如:①按学号查询;②按所在班级查询)
源代码:
#define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<string.h> #include<conio.h> #include<stdlib.h> #include<windows.h> #include<time.h> typedef struct people { char name[10]; //姓名 char IDnumber[20];//学号 char phone[15]; // 手机号 int classNum; //班级 char roomID[10]; //寝室 }people; //定义别名people //函数模块定义 void UI_show();//进入界面 UI 实现 void NEW_in(); //新学生信息添加 void OLD_adjust();//修改学生信息 void OLD_delete(); //删除学生信息 void OLD_find(); //学生信息查找 void OLD_findByNum();//通过学号查找 void OLD_findByName();//通过姓名查找 //各种UI界面显示 void UI_show1(); void UI_show2(); void UI_show3(); void UI_show4(); void UI_show5(); void UI_show6(); //======================================================================= //进入界面 UI 实现 void UI_show() { int i; //-------------------------------------------------------------------- printf("
最近接触了不少质量体系的话题,反复的听到SQE、DQE等,大概知道是跟质量管理相关的一些职位,但是具体也不是很清楚,于是干脆来理一下。
正式开始之前,先要介绍一下他们的老祖宗:QE,英文全称是Quality Egineering,中文意思是质量工程, 它主要着重于为品质管理活动提供技术支持,如可靠性试验,检验程式的设定,检验指导书(SIP)的制定,不良品或失效模式的分析等,QE是建立、分析、完善质量技术控制的程序。在实际执行的过程中,将QE细分为DQE、SQE、PQE、CQE等。
DQE: 全称:Design Quality Engineer,代表的是设计质量工程师。负责研发全过程环节的质量策划、实施、跟进,节点评审、产品验证、产品试验、检验,质量问题分析、改善措施制定及跟踪落实等等。
另外还包括,过程工艺,出货规格,质量标准制订,控制计划拟定(可靠性测试,物料认证,包括相关测试计划,标准,如果需要),buglist统计,项目进阶会议,推动各部门改善问题点,管理buglist,总结经验,承接试产,转交相关资料,直到量产。
SQE: 全称:Supplier Quality Engineer,即供应商质量工程师。主要负责从事技术质量和服务质量等的研究、管理、监督、检查、检验、分析、鉴定等。
工作职责:
对参与供应的供应商进行样品评估,并给出选定意见。
对供应商提供的原材料进行质量把控,对其中相关的质量问题需要汇报并协助厂商检查和修改。
为入货的验货部门制定检验计划,并进行一定的培训。
为供应商提供的产品进行质量方面上的打分,并参与下一个季度对新供应商的考核评分。
PQE: 全称:Product Quality Engineer,即产品质量工程师。主要负责熟悉产品的制程,分析和解决产品制造过程中出现的质量问题。
工作职责:
依据新产品和物料试产要求,审核新产品资料汇总表内容、试产结果、 PFMEA报告。审核产品质量计划(QC工程图),审批产品检验标准和作业指导书,评估检验工装治具的效用及对检验员进行培训的效果。生产、PQC、OQC发现的过程/产品缺陷,监督指导分析和处理过程,总结提炼并指导经验的运用。指导客诉、客退反映的过程/产品缺陷分析,审核客诉报告。制程、检验质量数据和报表的分析,总结提炼并指导闭环处理。依据产品制程可靠性/ORT要求,审批产品制程可靠性/ORT实验方案。依据客户对产品制程质量数据的需求,审核相关的质量数据报表。将内外部临时发生信息(检验要求、退料要求、出货要求)整理传递并监督执行情况。制定半成品、成品RoHS检测方案审核。依据3C、UL、RoHS等标准相关要求,审核对应的流程文件及实施记录。指导内外部审核及纠正、预防措施的实施。依据物料/产品试产要求,跟踪回复试产结果。跟进产品的品质状况,处理客户投诉并提供解决措施,并负责客户所需相关测试参数的收集及传递 CQE: 全称:Certified Quality Engineer,即注册质量工程师。
工作职责:
负责产品的售后,分析产品质量的原理、系统及团队的动态变化,对客户、供应商,乃至培训,都需要进行追踪和汇报。
跨领域获取和分析数据,制定可行的标准和定量的方法,给出预防和校正的措施。
进行计划制定、材料选取及取样测量等工作安排,对计划和结果进行审核和报告。
实例说明 在一个企业里,当有一个需要研发的新产品,首先需要SQE去和采购部门沟通配合,对前来参选的供应商进行样品评估,当材料送达企业,SQE和PQE需要对其进行质量把控、审核汇报,最后客户对产品进行反馈,CQE则扮演着售后的角色。
以下以图片资源为例,因为一般涉及到图片适配,所以出现图片显示异常,可以查看图片是加载的那个资源文件夹下的来判断是什么问题;前提是这张图片是放在项目中;
public void click(View view) { String name = (String) getText(R.drawable.ui1); String name2 = getResources().getString(R.drawable.ui1); Log.d(TAG, " name:" + name + " name2: " + name2); } 打印输出:name: res/drawable-xxhdpi-v4/ui1.png name2:res/drawable-xxhdpi-v4/ui1.png,所以从log可以看出加载的是xxhdpi下的图片资源,具体后面为什么多了一个-v4,目前还不太清楚,如果知道的朋友请帮忙留言指出!
1. SeaDAS介绍 https://seadas.gsfc.nasa.gov/about/
SeaDAS是一个全面的软件包,用于处理,显示,分析和质量控制遥感地球数据。
SeaDAS是NASA OBPG科学软件的官方发行点。SeaDAS的科学处理组件将OBPG算法应用于卫星数据,以表征和校准数据并生成科学质量的OBPG产品。
SeaDAS目前支持超过15个美国和国际卫星飞行任务的科学处理。为了确定地球/海洋表面水平信号,使用了其他一致的辅助数据来校正和校准信号的大气成分。
可以开发定制算法并将其应用在SeaDAS内,以评估海洋,陆地和大气数据,并生成真实彩色图像。
SeaDAS还可以将SeaBASS格式的原位数据集成在一起,以便与相关的卫星数据进行比较分析。
SeaDAS 8.x平台(ESA SNAP平台的扩展)充当NASA SeaDAS Toolbox和ESA Sentinel-3 Toolbox的应用程序平台。NASA SeaDAS科学处理的核心元素(基于命令行和基于GUI)都包含在SeaDAS ToolBox中。Sentinel-3工具箱中包含用于Sentinel-3任务的NASA卫星任务数据文件读取器和ESA处理器。在GUI的核心组件和内部框架方面,SeaDAS 8.x是对SeaDAS 7.5.3的重大修改。
SeaDAS的最新版本是8.0.0(测试版),其中包含SeaDAS Toolbox(版本1.0.0)和Sentinel-3 Toolbox(版本8.0.0)。
2. 软件下载地址 https://seadas.gsfc.nasa.gov/downloads/
3. 支持数据格式 MODIS
Landsat
SAR
……
4. 结果显示 软件界面
点击谱带,添加经纬网,修改色标,查看实时经纬度
可以旋转图像角度,调整色标范围
可以查看图像在地球上的位置
可以设置是否显示的图层:比如经纬网、海岸线等
如何导出图像
131. 分割回文串 思路:
因为题目要求不是分割的方法种数,而是具体的分割方法,所以用dfs比较合适,那如果直接用dfs暴力遍历各种可能显然是不高效的,因此我们可以用一个set记录所有出现的回文子串(记忆化递归),这就不用每遇到一个子串就判断一次是不是回文字串了:
class Solution { List<List<String>> res = new ArrayList<>(); Set<String> set = new HashSet<>(); public List<List<String>> partition(String s) { if(s.length() == 0) return res; dfs(s,0,new ArrayList<>()); return res; } public void dfs(String s,int start,List<String> list){ if(start == s.length()){ res.add(new ArrayList<>(list)); return; } for(int i=start;i<s.length();i++){ if(set.contains(s.substring(start,i+1)) || is(s.substring(start,i+1))){ list.add(s.substring(start,i+1)); dfs(s,i+1,list); list.remove(list.size()-1); } } } public boolean is(String sub){ if(sub.length() == 0) return false; int i = 0; int j = sub.
1.幺元(单位元)∶定义:
设*是集合Z中的二元运算,
(1)若有一元素el∈Z,对任一x∈Z有el*x=x;则称e1为Z中对于*的左幺元(左单位元素)
(2)若有一元素erEZ,对任一x∈Z有x*er=x;则称er为Z中对于*的右幺元(右单位元素)
定理:
若el和er分别是Z中对于*的左幺元和右幺元,则对于每一个x∈Z,可有el=er=e和e*x=x*e=x,则称e为Z中关于运算*的幺元,且e∈Z是唯一的。
2.零元定义:
设*是对集合Z中的二元运算,
(1)若有一元素0ez,且对每一个xeZ有0*x=e,则称e为Z中对于*的左零元;
(2)若有一元素0r ez,且对每一个xeZ有x*0r= 0r,则称0为Z中对于*的右零元。(零元不存在逆元)
定理:
若el和er分别是Z中对于*的左零元和右零元,于是对所有的xeZ,可有el=Or=0,能使0*x=x*O=0。在此情况下,0∈Z是唯一的,并称0是Z中对*的零元。
3.逆元定义:
设*是Z中的二元运算,且Z中含幺元e,令x∈z,
(1)若存在一xl∈Z,能使xl*x=e,则称xl是x的左逆元,并且称x是左可逆的;
(2)若存在一xr∈Z,能使x*xr=e,则称xr是x的右逆元,并且称x是右可逆的;
(3)若元素x既是左可逆的,又是右可逆的,则称x是可逆的,且x的逆元用x1表示。
定理:
设Z是集合,并含有k元e。*是定义在Z上的一个二元运算,并且是可结合的。若x∈Z是可逆的,则它的左逆元等于右逆元,且逆元是唯一的。
理解:逆元是针对某一个元素而言的,换句话说,代数系统a和b里面,a有逆元,不代表不有逆元。 并且和幺元相关,换句话说,代数系统里面必须有幺元,才能去谈逆元。 逆元*元素=幺元。(*为任意符号)
全国计算机一级《WPS》考试试题及答案
1.计算机之所以能按人们的意志自动进行工作,最直接的原因是因为采用了(C)
A 二进制数制
B 高速电子元件
C 存储程序控制
D 程序设计语言
解析:人将想要它做的事情用程序的方法写入到它的存储器中,然后它一条一条取出执行。
计算机最主要的特点是存储程序和自动控制
2.微型计算机主机的主要组成部分是(B)
A 运算器和控制器
B CPU 和内存储器
C CPU 和硬盘存储器
D CPU、内存储器和硬盘
注:微机的发展以(微处理器)的发展为特征
3.一个完整的计算机系统应该包括(B)
A 主机、键盘和显示器
B 硬件系统和软件系统
C 主机和它的外部设备
D 系统软件和应用软件
4. 计算机的软件系统包括(A)
A 系统软件和应用软件
C 数据库管理系统和数据库
B 编译系统和应用软件
D 程序、相应的数据和文档
5.微型计算机中,控制器的基本功能是(D)
A 进行算术和逻辑运算
C 保持各种控制状态
B 存储各种控制信息
D 控制计算机个部件协调一致地工作
6.计算机操作系统的作用是(A)
A 管理计算机系统的全部软、硬件资源,合理组织计算机的工作流程,以达到充分发挥计算机资源的 效率,为用户提供使用计算机的友好界面
B 对用户存储的文件进行管理,方便用户
C 执行用户键入的各类命令
D 为汉字操作系统提供运行的基础
7.计算机的硬件主要包括:中央处理器(CPU)、存储器、输出设备和(C)
A 键盘
B 鼠标
C 输入设备
yyfun001.com (Web前端开发学习平台)上PHP-MySQL的习题 (测验编号:91516)
(1)定义函数 getSum,函数接受一个二维数组参数,将二维数组遍历取得所有数字之和。该结果通过 return 方式返回
(2)在函数外部,调用该函数,参数是 $array , 将返回值赋值给变量$sum
(3)输出变量$sum
<?php header("content-type:text/html;charset=utf-8"); $array = array( array('1','2','6','5','4'), array('4','3','2') ); function getSum($array){ $he=0; //由于数组是多维数组所以需要用到两重foreach循环取值相加 foreach($array as $value){ foreach($value as $value1){ $he+=$value1; } } return $he; } $sum=getSum($array); echo $sum;
提到map用法,很多人想到forEach,那么这两种方法的区别是什么?会有人说,forEach会改变原数组;map不会改变原数组,返回一个新数组。事实是这样的吗?答案不是,这种说法不准确,是有条件的。
1、当数组的值为基本类型的时候,map遍历数组,当对数组中的值做处理的时候,的确不会改变原数组。
let a = [1,2,3]
b=a.map(item => { item = item+1 })
console.log(a) // [1,2,3]
console.log(b) // [2,3,4]
2、当数组是一个对象数组的时候,我们发现,map遍历数组,通过打印发现原数组发生改变了
有什么办法不让map改变对象数组这样的原数组?我们可以这样写。
经过打印,发现原数组没有被改变。为什么会这样呢?我们对对象数组中的item值,通过扩展运算符…深拷贝给obj,不在原数组中直接操作item的值,而是操作obj中值,这样原数组就不会改变了。注意:扩展运算符只对对象的第一层是深拷贝!!!所以当有人问你,扩展运算符是深拷贝还是浅拷贝的时候,应该分情况回答。这里不作详细解释。
链接
在工作中经常遇到构建docker服务时,显示磁盘空间不足,这是发现以前的docker镜像占用了大量的空间。
可以使用下列方法清理一部分磁盘:
1. docker system prune -a 清理无用的容器和镜像 2. 删除镜像后,空间还是不足,可能是docker容器中服务报错,产生大量的core文件 去docker目录下查看哪里占用空间大
cd /mnt/var/lib/docker/overlay2/
du -sh ./*
进入占用空间大的目录里
cd 容器目录
删除core 文件
rm -if core.*
在创建docker容器时,可以设置不生成core文件
问:Win7笔记本电脑连接不上WiFi怎么办?Win7无法连接WiFi上网怎么办?我的笔记本是Win7系统,但是无法连接我的WiFi上网了后,提示无法连接到此网络,请问应该如何设置?
答:Win7笔记本电脑无法连接到某个WiFi信号,有以下几个方面的原因:
1、WiFi密码错误
2、Win7中保存的WiFi记录与路由器中不符
3、路由器中限制
一、WiFi密码错误
当Win7笔记本电脑连接WiFi时,如果使用的WiFi密码不正确,那么肯定是无法连接WiFi上网的。所以,请先检查下你在Win7中填写的WiFi密码是否正确。
二、Win7中保存的WiFi记录与路由器中不符
如果Win7笔记本电脑之前已经连接了该WiFi信号,Win7笔记本电脑中就会保持这个WiFi的记录,后续连接时不用手动填写密码,自动就能连接上网。
不过,如果现在修改路由器中WiFi的密码、加密方式等参数,而没有修改WiFi名称。这时候就会出现Win7中保存的WiFi记录,与路由器中该WiFi的参数信息不符,这时候肯定连接不上WiFi了。
解决办法是删除Win7中保存的WiFi记录,重新搜索WiFi信号,输入新的WiFi密码,就可以连接上了。
1、打开网络和共享中心
点击屏幕中的“网络”图标,然后鼠标右键,选择“属性”,也是可以打开 网络和共享中心的
打开Win7的“网络”属性选项
2、打开“管理无线网络”选项
在网络和共享中心页面,点击左上方的“管理无线网络”选项,如下图所示
打开Win7的“管理无线网络”选项
3、删除wifi热点记录
在“管理无线网络”页面中,找到需要删除的wifi热点名称,然后鼠标右击,选择“删除网络”
删除Win7中保存的WiFi记录
在弹出的对话框中,点击“是”,如下图所示:
在弹出的对话框中,点击“是”
三、路由器中限制
无线路由器中是可以限制某台电脑上网的,当无线路由器中设置了“上网控制”、“家长控制”、“无线MAC地址过滤”等功能,就有可能造成Win7笔记本电脑连接不上WiFi的问题。
所以,请登录到路由器的设置页面,检查、关闭路由器中的“上网控制”、“家长控制”、“无线MAC地址过滤”等功能,如下图所示:
关闭路由器上的“家长控制”
关闭路由器上的“上网行为管理”
注意问题:
不同的无线路由器,设置界面不一样,请在你的无线路由器中注意查找相关功能。如果实在找不到,可以把你的无线路由器先恢复出厂设置,然后重新设置路由器上网,也是可以解决这个问题的。
相关文章:
软件项目管理第4版课后习题[附解析]系列文章目录第一章第二章第三章第四章第五章第六章第七章第八章第九章第十章第十一章第十二章第十三章第十四章第十五章第十六章期末复习题型分册版-练习版无答案(无大题版)期末复习题型分册版-有答案版(无大题版) 一、填空题 1、(完整性和可跟踪性)是软件配置管理的核心功能。
2、(基线)标志开发过程中一个阶段的结束和里程碑。
3、 基线变更控制包括(变更请求)、(变更控制)、(变更批准/拒绝)、(变更实现)等步骤。
4、(版本管理)、(变更管理)是配置管理的主要功能。
5、基线变更时,需要经过(SCCB)授权。
6、SCCB的全称是(软件配置控制委员会)。
二、 判断题 1、一个软件配置项可能有多个标识。(×)
每个软件只有唯一的配置项
2、基线提供了软件开发阶段的一个特定点。(对)
3、有效的项目管理能够控制变化,以最有效的手段应对变化,不断命中移动的目标。(√)
4、 一个(些)配置项形成并通过审核,即形成基线。(√)
5、软件配置项是项目需定义其受控于软件配置管理的款项,每个项目的配置项是相同的。(×)
6、基线的修改不需要每次都按照正式的程序执行。(×)
7、基线产品是不能修改的。(×)
8、基线修改应受到控制,但不一定要经SCCB授权。(×)
9、变更控制系统包括从项目变更申请、变更评估、变更审批到变更实施的文档化流程。(√)
10、持续支付领域强调对项目所有的相关产物及其之间的关系都要进行有效配置管理(对)
11、持续支付更倾向于使用基于分支的开发模式(错)
三、 选择题 1、 下列不属于SCCB的职责的是(D)
A 评估变更 B 与项目管理层沟通 C 对变更进行反馈 D 提出变更申请
请说明软件配置控制委员会(SCCB)的基本职责
答:
1.评估变更
2.批准变更申请
3.在生存期内规范变更申请流程
4.对变更进行反馈
5.与项目管理层沟通
2、为了更好地管理变更,需要定义项目基线,关于基线的描述,下列描述正确的是(B)
A 不可变化
B 可以变化,但是必须通过基线变更控制流程处理
C 所以的项目必须定义基线
D 基线发生变更时,必须修改需求
3、软件配置管理无法确保以下哪种软件产品属性(A)
A 正确性 B 完整性 C 一致性 D 可控性
4、变更控制需要关注的是(B)
A 阻止变更 B 标识变更,提出变更,管理变更
C 管理SCCB D 客户的想法
使用移远EC200模块发送AT+CCLK命令查询网络时间时,返回的时间并不是当前年月日时分秒,如果你返回的时间年月日,分秒相同,就是小时总是差一个固定的值,那说明得到的时间是对的。这和你所在的时区是由关系的。
我下面要说的是我得到了完全不同的时间。
我得到的是2014-1-1 0时0分0秒。
这个我百度了一大圈没找到原因,终于在外网得到了一点点解释,网站名称是devzone,标题是AT+CCLK reporting bogus time
根据答题大神的意思,首先,这是没有完美解决方案的,发生的原因可能是模块和基站未同步,所以返回了一个虚假的时间。而我得到这个错误时间也确实是开机的时候。
想要解决这个问题,也只能对得到的时间进行判断,如果远远小于现在的年份,那么肯定错了,重新读一次。
选择题是计算机一级考试的重要题型,为了帮助考生备考计算机一级考试的wps科目,下面学习啦小编为大家带来计算机一级考试wps选择题专项训练,欢迎考生备考练习。 计算机一级考试wps选择题专项训练1:
1、Office 应用程序一般都提供许多模板,以下关于模板叙述错误的是[ D ]。
A)模板可以被多次使用
B)模板中往往提供一些特定数据和格式
C)模板可以被修改
D)模板是 Office 提供的,用户不能创建新模板
2、在 Word 工作过程中,当光标位于文中某处,输入字符,通常都有哪两种工作状态[ A ]。
A)插入与改写
B)插入与移动
C)改写与复制
D)复制与移动
3、在 Excel 的单元格内输入日期时,年、月、日分隔符可以是[ A ]。
A) “/”或“—”
B) “.”或“|”
C) “/”或“\”
D) “\”或“—”
4、Excel 中默认的单元格引用是[ A ]。
A)相对引用
B)绝对引用
C)混合引用
D)三维引用
5、在 EXCEL 中,关于数据库的统计,正确的叙述是[ B ]。
A)通过记录单方式查询数据,构造条件时不同字段间可以有“或”的关系
B)在一张工作表中可以有多个数据库区
C)利用 DCOUNT 函数统计人数时,其第二参数可任意指定一列
D)在数据库中对记录进行排序,必须先选中数据区间 计算机一级考试wps选择题专项训练2:
1、将一个应用程序最小化,表示[ D ]。
A)终止该应用程序的运行
B)该应用程序窗口缩小到桌面上(不在任务栏)的一个图标按钮
C)该应用程序转入后台不再运行
D)该应用程序转入后台继续运行
2、在 Windows 中,将整个桌面画面复制到剪贴板的操作是[ C ]。
A)按 PrintScreen
B)按 CTRL+PrintScreen
报错信息:
java.util.concurrent.CompletionException: org.picocontainer.PicoRegistrationException: Key com.tang.intellij.lua.luacheck.LuaCheckSettings duplicated
图片信息因为修复完成找不到了!!!
原因lua插件重复导致的错误。
修改方式:找到目标文件夹将luanalysis删除,只留下Emmylua插件即可,直接删除喔
图示:错误前
修改后:
修改完成即可正常使用了
详细报错信息:
java.util.concurrent.CompletionException: org.picocontainer.PicoRegistrationException: Key com.tang.intellij.lua.luacheck.LuaCheckSettings duplicated
at java.base/java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:314)
at java.base/java.util.concurrent.CompletableFuture.uniApplyNow(CompletableFuture.java:683)
at java.base/java.util.concurrent.CompletableFuture.uniApplyStage(CompletableFuture.java:658)
at java.base/java.util.concurrent.CompletableFuture.thenApply(CompletableFuture.java:2094)
at com.intellij.idea.ApplicationLoader.registerAppComponents(ApplicationLoader.kt:104)
at com.intellij.idea.ApplicationLoader.executeInitAppInEdt(ApplicationLoader.kt:63)
at com.intellij.idea.ApplicationLoader.access$executeInitAppInEdt(ApplicationLoader.kt:1)
at com.intellij.idea.ApplicationLoader$initApplication$1$1.run(ApplicationLoader.kt:363)
at java.desktop/java.awt.event.InvocationEvent.dispatch(InvocationEvent.java:313)
at java.desktop/java.awt.EventQueue.dispatchEventImpl(EventQueue.java:776)
at java.desktop/java.awt.EventQueue$4.run(EventQueue.java:727)
at java.desktop/java.awt.EventQueue$4.run(EventQueue.java:721)
at java.base/java.security.AccessController.doPrivileged(Native Method)
at java.base/java.security.ProtectionDomain$JavaSecurityAccessImpl.doIntersectionPrivilege(ProtectionDomain.java:85)
at java.desktop/java.awt.EventQueue.dispatchEvent(EventQueue.java:746)
at java.desktop/java.awt.EventDispatchThread.pumpOneEventForFilters(EventDispatchThread.java:203)
at java.desktop/java.awt.EventDispatchThread.pumpEventsForFilter(EventDispatchThread.java:124)
at java.desktop/java.awt.EventDispatchThread.pumpEventsForHierarchy(EventDispatchThread.java:113)
at java.desktop/java.awt.EventDispatchThread.pumpEvents(EventDispatchThread.java:109)
at java.desktop/java.awt.EventDispatchThread.pumpEvents(EventDispatchThread.java:101)
at java.desktop/java.awt.EventDispatchThread.run(EventDispatchThread.java:90)
Caused by: org.picocontainer.PicoRegistrationException: Key com.tang.intellij.lua.luacheck.LuaCheckSettings duplicated
at com.intellij.util.pico.DefaultPicoContainer.registerComponent(DefaultPicoContainer.java:119)
使用正则表达式做数据清洗 正则表达式语法基本语法字符串函数REGEXP_REPLACEHive SQL 正则表达式语法 在操作大数据时,通常需要将某些数据进行清洗后再进行操作,某些不规则数据清洗需要用到正则表达式。正则表达式是一种匹配模式,可以进行字符匹配和位置匹配。
基本语法 语法解释英文A-Za-z数字0-9()标记一个子表达式的开始和结束的位置,括号内表示一个连续的表达式;如果要匹配小括号,需要用\转义,例如:()[]定义匹配的字符范围,例如:[a-zA-Z]表示匹配大小写英文字符{}定义匹配范围的长度,例如:{1}表示匹配一次,{1,}表示匹配大于等于1次,{2,3}表示匹配大于等于2小于等于3次*匹配子表达式零次或多次+匹配子表达式1次或多次?匹配子表达式0次或1次\转义字符^表示非的意思,例如:[^>]* 表示非>的字符可以有0次或多次\d匹配一个数字字符,等价于[0-9]\D匹配一个非数字字符,等价于[^0-9]\w匹配字母、数字、下划线,等价于[A-Za-z0-9_]\W匹配非字母、数字、下划线,等价于[^A-Za-z0-9_].匹配除换行符(\n、\r)之外的任何单个字符 字符串函数 MaxCompute SQL中使用字符串函数对指定字符串进行灵活处理,详情可以见:https://help.aliyun.com/document_detail/48973.html?utm_content=g_1000230851&spm=5176.20966629.toubu.3.f2991ddcpxxvD1#title-of8-230-1g4
REGEXP_REPLACE string regexp_replace(string <source>, string <pattern>, string <replace_string>[, bigint <occurrence>]) 命令说明 将source字符串中第occurrence次匹配pattern的子串替换成指定字符串replace_string后返回结果字符串。
参数说明
source:必填。STRING类型,待替换的字符串。
pattern:必填。STRING类型常量或正则表达式。待匹配的模型。更多正则表达式编写规范,请参见正则表达式规范。pattern为空串时返回报错。
replace_string:必填。STRING类型,将匹配pattern的字符串替换后的字符串。
occurrence:可选。BIGINT类型常量,必须大于等于0,表示将第occurrence次匹配的字符串替换为replace_string,为0时表示替换所有匹配的子串。为其他类型或小于0时,返回报错。默认值为0。
实例说明
在做埋点访客量统计时,url后面有单号的需要做清洗,将单号去除,只留下url,例如
www.baidu.com/query/OO99238842934/RR99382333,清洗后的数据为:www.baidu.com/query
url = ‘www.baidu.com/query/OO99238842934/RR99382333’
regexp_replace(url,'([\/]{1}[A-Z]{2,}[0-9]{5,})*', '') 正则表达式中的()很重要说明括号内的是一个完整需要匹配的子表达式,如果没有小括号会认为需要匹配url中所有的/、大写字母和数字
Hive SQL SELECT dt, url, (case when site_id in ('110077') then regexp_replace(url,'([\/]{1}[A-Z]{2,}[0-9]{5,})*', '') else url end) as url_cleaned FROM url_info;
无线AP是组建无线局域网的常用设备,承担连接有线网和无线网的作用,大型公司中常用AP实现局域网的大面积覆盖,可将所有接入终端连接至同一网络进行集中管理。在这种大面积覆盖的情况下,面积越大意味着所需AP数量越多,便会产生较高成本问题。
基于WiFi信号远距离传输技术的新型AP便可通过将WiFi基带与射频天线分离,以集成多片芯片的WiFi基带控制多个远端天线,实现低成本覆盖。
WiFi信号远距离传输可采用数字信号远距离传输和模拟信号远距离传输两种方式实现,其中,数字信号远距离传输的拉远部分,需要调制解调模块将射频线传输的数字信号转换为模拟信号,成本较高,而模拟信号远距离传输的拉远部分则只需射频器件搭建收发通道,成本较低。
着眼于WiFi模拟信号远距离传输,针对其射频单元提出实现方案。WiFi模拟信号远距离传输的基本原理,是将WiFi射频信号变频到网线能承载的低中频进行长距离传输,然后在远端天线处再将低中频信号上变频还原到2.4/5GHz WiFi所工作的高频段,从而使WiFi基带与射频天线的分离。
通过集成多个WiFi基带芯片,可以极低的成本实现集中基带池的C-RAN架构。WiFi模拟信号远距离传输所实现的架构具有类似分布式基站的特点。这里小编推荐一款远距离WiFi模块:云望物联cv5200是一款卓越的双向无线通信系统。
该产品基于802.11无线通信标准,采用自身开发的LR-WiFi(Long Rang WiFi远距离WiFi)私有协议,具备ML,MRC,LDPC,MIMO-OFDM等高级无线技术。具有传输距离远、可组网、抗干扰性强、超高灵敏度的特点。
特别适用于远距离,高速率的场合,比如无人机 ,安防监控,智慧建筑,智慧农业,机器人等。该产品采用SOC实现,性能与成本俱佳,并能即贴即用,减少开发量。
分布式基站通过RRU拉远,BBU集中管理,减少设备成本的投入,而基于WiFi模拟信号远距离传输所实现的分布式架构将独立WiFi AP分成BPU和FAU两部分,也通过FAU拉远,BPU集中管理,且可以一套BPU和多套FAU的连接实现D-MIMO。
BPU主要由WiFi基带与SoC集成芯片组成,将多片WiFi SoC集中贴装到一个设备中可提高设备集成度,同时也可实现多个远端天线共享基带资源。
BPU可以1U盒式设备的形式安装在楼道处,实现16~32个传统AP的功能,提供64~128通道资源,也可以5+U机架式设备的形式安装在企业机房,实现更大容量AP阵列(如256~512个AP,1K~2K通道)。
FAU主要由射频变频器件、模拟前端放大器、控制电路以及天线组成。FAU形态为小型化的吸顶天线,由于其有源部分仅包含模拟射频单元,功耗可以做到极低,通过PoE或更低成本的私有化方案即可实现供电。
CV5200具有超长的传输距离,实测视距情况下超过 6 公里(固定2Mbps,2dB天线);独有的LR-WiFi技术,保证在此距离下的实时传输;具有的窄带宽MIMO无线通信技术,拥有超强的抗干扰能力,并支持自动信道选择。
采用ML,MRC,MIMO-OFDM等高级无线技术,提供可靠、清晰的无线信号,能够实现长距离的非视距(N-LOS) 移动无线通信。在多径、 移动多普勒效应环境下保持可靠传输。
基带处理板的WiFi芯片输出5G/2.4G复数I-Q信号,复数信号经I-Q混频器一次混频至低中频,低中频信号通过网线传输至远端变频板。
在远端模拟域上变频至5G/2.4G后,经天线发射出去;接收方向则相反,远端变频板将天线接收RF信号模拟域降频至低中频,网线传输至基带处理板,低中频信号经I-Q混频器一次混频为复数I-Q信号后,由WiFi芯片接收。
复数I-Q变频方案的优点有:
(1)远端变频板为超外差模拟域变频,仍具备超外差变频方案选择性好的优点。
(2)该方案近端采用I-Q变频,且为零中频复数信号变频至低中频,I-Q混频器自身抑制度足够满足要求,所需滤波器较少,方案整体体积较小。
基带处理板的WiFi芯片通过数字域信号处理,直接产生实数的低中频信号,通过网线传输至远端变频板,在远端模拟域上变频至5G/2.4G后,经天线发射出去;接收方向则相反,远端变频板将天线接收RF信号模拟域降频至低中频,网线传输至基带处理板,WiFi芯片直接对低中频信号进行处理。
基带直接产生低中频方案的优点有:该方案只需要一块变频板,体积小且附加成本低,只有远端变频板有滤波器,BPU可以集成为WiFi芯片。
为什么无线远距离传输能传这么远呢?原来是CV5200通过对物理底层和MAC层基于802.11标准进行了优化,形成私有LR-WiFi协议,具有更好的物理层和MAC机制,支持更远距离的传输,并且支持一对多组网和mesh网状网组网哦。
342.4的幂 题目描述 给定一个整数,写一个函数来判断它是否是4的幂次方。如果是,返回true;否则,返回false。
整数n是4的幂次方需满足:存在整数x使得n == 4x
示例1
输入:n = 16
输出:true
示例2
输入:n = 5
输出:false
示例3
输入:n = 1
输出:true
提示
-231 <= n <= 231 - 1你能够不使用循环/递归解决此问题吗? 代码演示
Java 数学方法/位运算
public class OneQuestionPerDay342 { public static void main(String[] args) { Solution s = new Solution(); System.out.println(s.isPowerOfFour(5)); System.out.println(s.isPowerOfFour(16)); System.out.println(s.isPowerOfFour(1)); } } class Solution342_2 { public boolean isPowerOfFour(int n) { return (n > 0) && ((n & (n-1)) == 0) && (n % 3 == 1); } } class Solution { public boolean isPowerOfFour(int n) { for (int count = 0; count < 32; count += 2) { if ((1 << count) == n) return true; } return false; } } 数学方法 提交结果
参考连接:https://itectec.com/ubuntu/ubuntu-gdm3-display-manager-hangs-after-booting-with-ubuntu-18-10/
直接搬运过来:
Not sure if this is going to fix your problem, but it’s quick, so it’s worth a try…
You may have a problem with an older computer, with an older GPU. Try this…
boot to recovery modechoose root access type:
sudo mount -o remount,rw / # to remount the disk r/w sudo pico /etc/gdm3/custom.conf # edit this file change:
#WaylandEnable=false to:
WaylandEnable=false Then reboot.
我是重启一次后,卡在了logo界面,再重启一次就好了!
运行jupter notebook 时,卡在cmd界面,无法自动打开浏览器,但是手动复制地址可以打开。
步骤1.打开Anaconda Prompt或Anaconda Powershell Prompt,执行jupyter notebook --generate-config,有时系统会提示,选择Y;若无提示,运行结果提示路径,复制路径,根据路径找到 Jupyter_notebook_config.py文件,打开文件搜索#c.NotebookApp.notebook_dir = '‘在此语句下添加代码:import webbrowserwebbrowser.register(‘chrome’,None,webbrowser.GenericBrowser(u’C:\Users\xgr\AppData\Local\Google\Chrome\Application\chrome.exe’))c.NotebookApp.browser = ‘chrome’
注意:C:\Users\xgr\AppData\Local\Google\Chrome\Application\chrome.exe是Google浏览器在自己电脑的地址,查找方式:桌面的Google图标,右键-属性
然后把单斜杠换成双斜杠。保存后退出。重新执行,应该就能自动打开了
转载自知乎
Anaconda安装好之后jupyter notebook打不开
path标签概述 他是由命令及其参数组组成的字符串,如:
<path d="M0,0L10,20C30-10,40,20,100,100" stroke="red"> 命名规范 区分大小写:大写表示坐标参数为绝对位置,小写则为相对位置最后的参数表示最终要到达的位置上一个命令结束的位置就是下一个命令开始的位置命令可以重复参数表示重复执行同一条命令 命令简介 M (x, y)+ 移动画笔,后面如果有重复参数,会当做是 L 命令处理L (x, y)+ 绘制直线到指定位置H (x)+ 绘制水平线到指定的 x 位置V (y)+ 绘制竖直线到指定的 y 位置m、l、h、v 使用相对位置绘制 命令含义M/m (x,y)+移动当前位置L/l (x,y)+从当前位置绘制线段到指定位置H/h (x)+从当前位置绘制⽔平线到达指定的 x 坐标V/v (y)+从当前位置绘制竖直线到达指定的 y 坐标Z/z闭合当前路径C/c (x1,y1,x2,y2,x,y)+从当前位置绘制三次⻉塞尔曲线到指定位置S/s (x2,y2,x,y)+从当前位置光滑绘制三次⻉塞尔曲线到指定位置Q/q (x1,y1,x,y)+从当前位置绘制⼆次⻉塞尔曲线到指定位置T/t (x,y)+从当前位置光滑绘制⼆次⻉塞尔曲线到指定位置A/a (rx,ry,xr,laf,sf,x,y)从当前位置绘制弧线到指定位置 移动与直线类 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title></title> <style type="text/css"> svg { width: 300px; height: 300px; border: 1px solid green; } </style> </head> <body> <svg> <!-- d 定义路径,是一些列的命令集合 M/m(x,y) 定义起始点,没有什么效果 --> <path d='M20,20' stroke='red'></path> <!
#include <iostream> #include <boost/json.hpp> using namespace boost::json; int main(int argc, const char * argv[]) { array arr( { "Hello", 42, true }); string str = "World"; value var = false; object subobj{ {"subkey1",3.14},{"subkey2","π"} }; object obj; obj.emplace("key1", arr); obj.emplace("key2", str); obj.emplace("key3", var); obj.emplace("key4", 42); obj.emplace("key5", subobj); std::cout << obj; return 0; } 本节将object。可以把object理解成pair<string, value>的集合,类似map。
可以把任意东西放入object。
key1对应的是array
key2对应的是string
key3对应的是bool。value把它当成scalar标量存储。
key4对应的int64,这个库把整数按照int64或者unsigned int64存储。
key5对应的object,一个object有个子object。
转std::string, 用如下方法:
std::string aa = serialize(obj);
友情提示:本篇文章可能读起来有点晦涩难懂,但读完一定会让你明白NLP是做什么的以及它的使用场景,甚至还能让你走上NLP的道路,且听我来聊聊。
NLP,是英文Natural Language Processing的缩写,翻译过来叫自然语言处理,是人工智能和语言学领域的分支学科。
人们自古以来都在和文字打交道,无论是外国的英文还是我们的中文。我们使用文字挺简单的,那么到了计算机时代能不能让计算机也能够理解人所用的文字呢?这便是NLP的由来。
只说概念可能比较模糊,最好理解NLP的方式就是看它使用的场景,由于NLP覆盖的场景太多了,我这里挑十大任务模式来说下。
1、分词 凡做NLP的必然会用到分词,将一句话进行一个完美的分词是之后任务的基础,而中文分词比英文分词要困难,英文词汇有空格符分割词的边界,但中文中,却没有类似的方式来区分。目前中文分词做的比较好的比如Jieba、HanLp等。
2、摘要生成 这个任务主要就是通过建立一个模型来生成关于一段话的摘要。过去常用的是抽取式摘要。把一篇文档看作是许多句子的组成的序列,模型需要从中找出最能熔炼文章大意的句子提取出来作为输出。它相当于是对每个句子做一个二分类,来决定它要不要放入摘要中。但仅仅把每个句子分开来考虑是不够的。我们需要模型输入整篇文章后,再决定哪个句子更重要。这个序列的基本单位是一个句子的表征。而最近更流行的是生成式摘要,模型的输入是一段长文本,输出是短文本。输出的短文本往往会与输入的长文本有很多共用的词汇。这就需要模型在生成的过程中把文章中重要词汇拷贝出来,放到输出中的复制的能力,比如 Pointer Network。
3、翻译 这个应该很好理解吧,就是把一种语言自动翻译为另一种语言。比如把中文翻译成英文,再把英文翻译成中文。
4、语法改错 这个任务就是通过搭建一个模型,根据上下文的情境来检测这篇文章中是否有错别字或者语法错误。比如我们在有些平台编辑文章完成后就会出现提示有哪些错别字,就是利用的这种模型。
5、文本分类 文本分类可以说是NLP非常典型的任务了,文本分类下面又可以衍生出很多任务场景。比如情感分类,就是判断一篇文章是积极向上的还是恶意低俗的,一篇文章会包括正面的词汇和负面的词汇,模型需要根据上下文学到语境中更侧重正面还是负面。再比如事实验证分类,模型需要看一篇新闻文章,判断该文章内容是真的还是假的。
6、自然语言推断 输入给模型的是一个陈述前提,和一个假设,输出是能否通过前提推出假设,它包含三个类别,分别是矛盾,蕴含和中性。比如前提是,一个人骑在马上跳过一架破旧的飞机,假设是这个人正在吃午餐。这显然是矛盾的。因为前提推不出假设。如果假设是,这个人在户外,在一匹马上。则可以推理出蕴含。再如果假设是这个人正在一个比赛中训练他的马。则推理不能确定,所以是中性的。
7、搜索引擎 模型的输入是一个关键词或一个问句和一堆文章,输出是每篇文章与该问句的相关性。谷歌有把 BERT 用在搜素引擎上在语义理解上得到了提升。比如搜帮你做美容的人是否经常站着工作。没有 BERT 之前,模型会利用关键词 estheticians 和 stand-alone 做合并结果输出。但有了 BERT 之后,搜出的结果会更倾向于文章语义的理解而非单纯的关键字匹配。
8、对话机器人 对话机器人可以分成两种,闲聊和任务导向型。闲聊机器人基本上都是在尬聊,有一堆问题待解决,比如角色一致性,多轮会话,对上下文保有记忆等。任务导向的对话机器人能够协助人完成某件事,比如订机票,调闹钟,问天气等。我们需要一个模型把过去已经有的历史对话,统统都输入到一个模型中,这个模型可以输出一个序列当作现在机器的回复。
9、知识图谱 知识图谱的构建简化地去理解可以看作是实体提取和关系抽取。实体可以是人可以是物,也可以是组织机构,非常灵活。关系可以是人与人的关系,可以是谓语动作,也可以是企业之间的资本流动。信息抽取任务希望从海量文本中自动挖掘出实体关系三元组。这个问题其实非常地复杂。这里只是简单地讲。
10、实体命名识别 这类任务的主要目的就是从一段文本中提取实体。那什么是实体呢?可以是人名、地名、产品名、公司名等等很多很多。具体提取什么实体需要根据我们的实际业务场景来进行。
听完上面关于NLP的十大任务场景是不是对NLP就有了一个大概的了解了呢。如果只是了解那就足够,但是如果你想从事NLP工作的话,那只了解是不够的。首先你在学NLP之前还得先学会机器学习和深度学习,而想要学会必须得有线性代数和概率论的基础,所以说大学学好高数很重要啊!
另外我之前写了个关于NLP入门任务的教程放在github上了,该项目主要是为了完成复旦大学邱锡鹏老师的NLP入门练习以及给想要入门NLP的同学一个教程,看目前获得的star数量还是不旺我的一番心血呀!该项目地址为:https://github.com/Alic-yuan/nlp-beginner-finish
码字不易,点个赞再走吧!
/** * 解析地址 * @param address * @return */ public static List<Map<String,String>> addressResolution(String address){ /* * java.util.regex是一个用正则表达式所订制的模式来对字符串进行匹配工作的类库包。它包括两个类:Pattern和Matcher Pattern * 一个Pattern是一个正则表达式经编译后的表现模式。 Matcher * 一个Matcher对象是一个状态机器,它依据Pattern对象做为匹配模式对字符串展开匹配检查。 * 首先一个Pattern实例订制了一个所用语法与PERL的类似的正则表达式经编译后的模式,然后一个Matcher实例在这个给定的Pattern实例的模式控制下进行 * 字符串的匹配工作。 */ String regex="(?<province>[^省]+自治区|.*?省|.*?行政区|.*?市)?(?<city>[^市]+自治州|.*?地区|.*?行政单位|.+盟|市辖区|.*?市|.*?县)?(?<county>[^县]+县|.+区|.+市|.+旗|.+海域|.+岛)?(?<town>[^区]+区|.+镇)?(?<village>.*)"; //(?<province>[^省]+自治区|.*?省|.*?行政区|.*?市)?表示一个模块 最后的问号表示可以为空 Matcher m=Pattern.compile(regex).matcher(address); String province=null,city=null,county=null,town=null,village=null; List<Map<String,String>> table=new ArrayList<Map<String,String>>(); Map<String,String> row=null; while(m.find()){ row=new LinkedHashMap<String,String>(); province=m.group("province"); row.put("province", province==null?"":province.trim()); city=m.group("city"); row.put("city", city==null?"":city.trim()); county=m.group("county"); row.put("county", county==null?"":county.trim()); town=m.group("town"); row.put("town", town==null?"":town.trim()); village=m.group("village"); row.put("village", village==null?"":village.trim()); table.add(row); } return table; } public static void main(String[] args) { List<Map<String,String>> table = addressResolution("
dlss是nvidia在19年初的时候推出的一项技术,其中文名“深度学习超级采样”,今天电脑配置网就来和大家聊聊关于显卡dlss的相关知识。
DLSS技术是什么意思?DLSS有什么作用?
dlss是深度学习超采样技术,它依赖的就是Tensor
Core具备的深度学习能力,使用低分辨率图像(比如1080p)生成高分辨率图像(8K),再把8K图像缩回4K,得到超级采样抗锯齿(SSAA)图像,以代替传统的时间抗锯齿等技术。
从dlss的中文名称“深度学习超级采样”顾名思义,简单来说DLSS类似于训练AI,它依赖于Tensor
Core单元,使其对各种东西的认知得到提高,该技术允许 GPU 利用着色器生成一些像素并借助
AI“脑补”出其他像素,在保持平滑、清晰画质的同时提高提升渲染分辨率,同时还不会牺牲游戏性能。
DLSS占用资源小,当使用显卡的DLSS功能后,占用的资源大概是正常渲染1080P的资源。比如你用4K屏幕玩4K画质的游戏,但是显卡的负担并不会很大,因为对显卡来说,它的工作量其实只有1080P那么多。
什么显卡可以使用dlss技术?目前支持dlss的游戏有哪些?
dlss是nvida显卡的专有技术,而且目前只能是RTX系列的显卡才支持DLSS,这是因为DLSS技术受限于其中的Tensor
Core单元,GTX系列的显卡并没有集成这个模块,只有RTX系列显卡才有。所以GTX系列显卡也和DLSS技术无缘了,除非nvida在GTX系列的显卡里也加入Tensor
Core单元。
游戏方面,目前为止支持dlss技术的游戏大概有10来款,比如:《战地5》《怪物猎人:世界》《德军总部:新血脉》《古墓丽影:暗影》《飞向月球》《光明记忆》《控制》《最终幻想15》《圣歌》《地铁离去》《逆水寒》……不过随着时间的推移,相信能够支持dlss技术的游戏会越来越多
更新后的DLSS 2.0版本性能提升空前!
前边已经说过,dlss是nvidia在19年初的时候退出的一项技术,而就在上个月底(2020年2月底),DLSS技术赢了更新后的2.0版本。
其实初代DLSS的表现并不是很理想,虽然开启DLSS后游戏帧数的大幅提升效果虽然被认可,但伴随着帧数提高的却是因为技术不完善而带来的画质缩水现象,跟打了码差不多。
而这次更新后的DLSS
2.0版本在效果、集成便利度和效率上面都有较大的提升,可以说这是AI渲染技术的一次巨大飞跃。以RTX2060显卡为例,在某些游戏开启DLSS后,RTX2060显卡甚至能追上未开启DLSS的RTX2080Ti(见上图)。
总结:
dlss是N卡专有的一项技术,尤其是最新的2.0版本DLSS,开启后,可以使你的RTX显卡性能成吨的提升,以前只能2080ti才能流畅运行的游戏,现在用RTX2060就能跑起来,当然前提是你所玩的游戏要支持DLSS才行。
原创文章:dlss技术是什么意思有什么用?目前支持dlss的游戏有哪些?, 如若转载,请注明出处:https://www.safeb.cn/3359.html
文章均为网络自动采集,如有不适,请联系296649600@qq.com删除
预测模型的样本量计算一直都是困扰笔者很久的问题
一般临床预测模型常见的有两类:非时间因素/包含时间因素
举例来说,非时间因素建模常见于logistic/lasso等回归模型之后,时间因素相关的结局变量常见于cox等模型建模后。
如果选用logistic模型,可使用的思路为:
1、根据自变量数目进行预测,根据自变量(即构建模型的自变量)数量,10-20倍区间的样本量均可。具体理论后续补充或完善。
2、将预测模型视为临床研究的思路,即A模型比B模型能提高结局的预测能力,即在某一类人群中(高危?or 低危?)模型的预测准确度提高了多少。即ROC提高了多少,通过软件ROC可以计算。计算方法 PASS软件可以实现,需强调的是,需要输入阳性与阴性事件发生的概率比值。
包含时间因素:例如cox等,本身似乎并不存在相应的计算方式,所以不要有太高的指望。有的话请统计大佬不吝赐教。
考虑到实际应用的问题,将时间因素降维到时间节点后有退化的方式
包括
1、特殊事件点的事件预测能力,将时间退化到时间节点后预测ROC的提高程度。
eg 患者活到3年的概率为(3年OS率),如果从10%提高到20%,需要的样本量是多少,将预测模型作为一个干预变量进行设计。
<template> <div> <el-upload action="#" list-type="picture-card" :auto-upload="false"> <i slot="default" class="el-icon-plus"></i> <div slot="file" slot-scope="{file}"> <el-image id="122" ref="previewImg" :src="file.url" :preview-src-list='imgs'></el-image> <span class="el-upload-list__item-actions"> <span class="el-upload-list__item-preview" @click="handlePictureCardPreview(file)"> <i class="el-icon-zoom-in"></i> </span> <span class="el-upload-list__item-delete" @click="handleRemove(file)"> <i class="el-icon-delete"></i> </span> </span> </div> </el-upload> </div> </template> <script> export default { name: "uploadImgComponent", components: {}, data() { return { imgs: ['http://**********/img/1.jpeg'] } }, created() { }, methods: { handlePictureCardPreview(file) { // 重点 this.$refs.previewImg.showViewer = true }, handleRemove(file) { } } } </script>
阿里的人才画像 其实最近两年自己一直在做面试官,也面试过很多优秀的人,心里大概有一个标准,知道什么样的人才是我们想要的人。
但是这个标准我一直都没有仔细的去思考过,刚好最近有时间,我好好的思考了一下,根据我的理解,谈一谈我认为的阿里的人才画像是怎样的。
我觉得阿里需要的人才大概需要具备这几方面的能力:
1、软件开发能力
2、架构设计能力
3、项目管理能力
4、线上运维能力
5、业务理解能力
6、学习能力
7、影响力
8、目标导向
以上,是我认为是一个P6需要具备的能力的几个方面,但是每个方面的能力并不一定要求非常出众,但是有些又很重要。
到阿里巴巴的招聘网站上,随便找几个P6的岗位,看一下岗位要求:


这些岗位描述和要求里面的内容,基本都能和以上几个能力对应的上:
负责平台核心功能、公共模块的规划及架构设计,包括系统架构设计、接口规范制定、技术文档、单元测试的编写等; -----> 架构设计能力
业务模型理解和抽象能力突出,参与科学决策、数字兴业、数字治理等相关系统的架构设计,承担核心模块的代码编写 。 -----> 架构设计能力
业务理解和建模能力突出,能独立完成系统(或核心模块)的设计、开发和系统维护;-----> 业务理解能力
扎实的Java/JEE知识基础和功底(重点包括包括JVM、类装载机制、多线程并发、IO、网络等),有比较优秀的动手能力;-----> 软件开发能力
扎实的Java编程基础,理解io、反射、多线程、集合等,清楚JVM的原理;-----> 软件开发能力
熟练掌握主流JAVA框架,并且能了解到它的原理和机制;熟悉MySQL/Oracle数据库中的一种或多种,有一定的SQL性能优化经验;-----> 软件开发能力
良好的面向对象设计能力,对互联网高并发、高可用和高复用有一定的理解和实践,熟悉分布式技术(包括缓存、消息系统、热部署、JMX等)优先; -----> 软件开发能力
具有比较强的问题分析和处理能力,有比较优秀的动手能力,热衷技术,精益求精; -----> 线上运维能力
有强烈的责任心,抗压能力强; -----> 目标导向
保障数字乡村业务系统的稳定性和项目质量,参与平台核心系统的架构设计。-----> 项目管理能力
业务理解和学习能力强,善于与商业/合作伙伴交流,有很好的适应和沟通能力,具备责任心、耐心、细心的品质;----->业务理解能力 、学习能力
以上的岗位描述中,对于一些能力的描述都是使用了一些形容词或者程度副词,如突出的、扎实的、比较优秀的、熟悉、熟练掌握、比较强的、有强烈的、强、善于、很好的等。
那么,到底什么样算是优秀?做到什么程度又酸是扎实、熟练能?又要怎么做才能达到突出呢?
接下来我分别说说对于阿里的P6这个层级,以上这些能力大概需要达到什么样的标准。
软件开发能力 对于一个程序员来说,软件开发能力当然是一个最最基础的能力了,很多面试主要考察的也都是软件开发能力。
那么,到底需要掌握哪些知识,才能达到阿里的P6的标准呢?
在回答这个问题之前,我看了很多大厂的招聘要求,并且回顾了一下以往面试时自己对于候选人的要求,大概总结出一些我认为比较重要的知识点。
可以说,如果以下这些知识点,候选人不能完全掌握的话,面试挂掉的概率很大。
1、Java基础。这个是最最基本的,像集合类、IO、反射这些常见的内容一定要做到如数家珍。
2、并发编程。这个也是面试很看重的知识点,对于线程安全问题、相关关键字的用法及原理、并发包等知识也要掌握。
3、JVM相关。这部分几乎是面试必考!JVM内存结构、GC相关的、调优、类加载等等这些的原理都要有了解的。
4、框架相关。目前主流的一些框架一定要了解的,如Spring等开源框架, 要知道用法及重要特性的原理、
4、分布式相关。这是大厂比较看重的一点了,对于分布式理论知识、缓存、消息、RPC等工具的用法和原理有了解的话,面试会轻松很多。
5、高并发、高性能方面只是。这部分也是挺重要的。
6、数据库相关知识。如Mysql的一些知识、锁、隔离级别、事务、索引等等。
7、数据结构与算法。这部分很多公司喜欢问一些算法题。
基础篇。掌握70% 底层篇。掌握60% 进阶篇。掌握50% 高级篇。掌握30%
那么,你的知识面的广度以及深度的话,我认为算是达到了一个相对符合标准的程度。
架构设计能力 很多人会认为,我只是一个做开发的,又不是架构师,为什么要求我有架构能力呢?
Content-Type(内容类型),一般是指网页中存在的 Content-Type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件,这就是经常看到一些 PHP 网页点击的结果却是下载一个文件或一张图片的原因。
Content-Type 标头告诉客户端实际返回的内容的内容类型。
语法格式:
Content-Type: text/html; charset=utf-8 常见的媒体格式类型如下:
text/html : HTML格式text/plain :纯文本格式text/xml : XML格式image/gif :gif图片格式image/jpeg :jpg图片格式image/png:png图片格式 以application开头的媒体格式类型:
application/xhtml+xml :XHTML格式application/xml: XML数据格式application/atom+xml :Atom XML聚合格式application/json: JSON数据格式application/pdf:pdf格式application/msword : Word文档格式application/octet-stream : 二进制流数据(如常见的文件下载)application/x-www-form-urlencoded : <form encType=””>中默认的encType,form表单数据被编码为key/value格式发送到服务器(表单默认的提交数据的格式) 另外一种常见的媒体格式是上传文件之时使用的:
multipart/form-data : 需要在表单中进行文件上传时,就需要使用该格式
mybatis mybatis简介 MyBatis 是一款优秀的持久层框架①它支持自定义 SQL、存储过程以及高级映射。②MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。③MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
mybatis核心配置文件 核心配置文件可以通过不同的标签配置mybayis中的许多内容,如外部引入文件,别名机制,设置,配置数据库环境配置mapper等。分别有如下标签:
引入文件 properties
设置 setting
别名机制 typealiases
数据库环境 enviroments
配置mapper mappers
properties标签详解 properties标签主要用于引入外部peoperties文件,使用resource属性引入。
eg:
其主要的应用就是从外部引入搭建数据库所需要的环境在下面使用${}符号直接获取,也可在标签中写
来手动定义属性,但是其优先级不如配置文件高
setting详解 setting标签主要应用于设置mybatis框架的各种配置例如是否开启缓存,是否使用数据库命名方式和驼峰的转化,是否使用日志文件等
typealiases详解 typealiases标签是mybatis中的一个别名机制,主要用于给pojo类写别名。由于没有别名的开发中所有pojo都需要写出其完全限定名,不利于开发现在使用这个机制优化。
其中总共有两个标签package是对一个包中所有类都别名化可以大写也可以小写而typeAlias只对一个类设置别名
enviroments详解 enviroments是对所使用的数据库驱动用户数据库等数据库环境参数的配置。
①其中可以使用多套配置环境使用default来指定enviroment的id确定使用哪一套环境
②transactionManager用于确定使用的是哪个数据库的事务管理器
③dataSource和property就用于设置参数
mappers详解 mappers主要用于配置每个mapper.xml的环境路径
其中mapper标签可以使用class来绑定类(前提是类与xml在同一文件下且同名使用点分割)
也可以使用resource来配置xml路径使用划线搞
接口类和mapper.xml mybatis的使用主要猪调用接口和mapper.xml来创建mapper使用mapper来做一个数据库操作。需要注意的是每个mapper.xml都需要一个接口类。而且需要将其配置在核心配置文件中
mapper.xml和接口的关系 mapper和接口的关系:
①mapper标签中的namespace属性用于绑定相对应的接口的完全限定名,绑定后相当于该mapper用于实现接口。
②xml中每个标签的id用于绑定接口中方法名,相当于该标签是该接口方法的实现。
增删改查实现 增删改查的实现为:
①在接口中定义增伤改查的方法头
void addBlog(Blog blog);
②xml中根据方法头中的信息使用标签实现方法
insert into blog(id,title,author,create_time,views) values(#{id},#{title},#{author},#{createTime},#{views})
万能的map 向标签中传递参数的方式有三种:
慕雪6442864
对于其他对此感兴趣的人,我最终根据Siddhart Rout的早期答案使用了下面的代码XMLHttp 比自动化快得多 IE代码为每个要下载的系列生成一个CSV文件(保存在X变量中)代码将每个匹配转储到常规的29行范围(无论有多少玩家参与),以便稍后进行简单的分析 Public Sub PopulateDataSheets_XML()
Dim URL As String
Dim ws As Worksheet
Dim lngRow As Long
Dim lngRecords As Long
Dim lngWrite As Long
Dim lngSpare As Long
Dim lngInnings As Long
Dim lngRow1 As Long
Dim X(1 To 15, 1 To 4) As String
Dim objFSO As Object
Dim objTF As Object
Dim xmlHttp As Object
Dim htmldoc As HTMLDocument
Dim htmlbody As htmlbody Dim tbl As HTMLTable
Ggplot :论文级别的柱状图应该如何绘制(设置参数)?
library(ggplot2) data(mpg) #导入展示数据 #原始图片 ggplot(mpg,aes(x = class))+ geom_bar() #加工后图片 ggplot(mpg,aes(x = class))+ geom_bar(width = 0.7, color = "black",fill = "#565656",size = 0.8)+ scale_y_continuous(limits = c(0,70),expand = c(0,0))+ coord_fixed(ratio = 7/70)+ theme_bw()+ theme(axis.text.x = element_text(angle = 30,hjust = 1), panel.border = element_blank(), axis.line.x = element_line(), axis.line.y = element_line(), panel.grid.major.x = element_blank(), panel.grid.minor.y = element_blank()) # geom_bar() : # width 设置柱子的宽度 # color 设置柱子边框的颜色 # size 设置柱子边框的粗细 # fill 设置柱子填充的颜色 # # scale_y_continuous() : # limits 设置y轴的范围 # expand 设置柱子底部能够紧贴x轴 # # coord_fixed() : # x/y x为x轴长度,y为y轴长度,此举可设置图片为正方形(无论如何拉扯图片) # # theme() : # axis.
iPhone 上下载了很多 App,无法找到对应的 App 图标了怎么办?
确认应用是否已经下载
如果是找不到 App,不记得之前是否有卸载,无论是不是 iPhone 自带的 App,都可以在 App Store 输入应用的准确名称来重新下载。
iOS 12 中可删除的系统自带应用名称如下:
若您无法重新下载,只有“打开”的选项,则此 App 是已经安装到您设备中了,请回忆下是否之前有进行过隐藏。
恢复隐藏图标
在 iOS 11 中,可以通过 Siri 来隐藏图标:
一只手长按图标,进入【抖动模式】同时另一只手指长按 home 键召唤出 Siri。然后快速将图标拖动到 Siri 界面当中。
如果想要在手机桌面上恢复这些被隐藏的 App 图标,只需要再次长按图标进入【抖动模式】然后按一下 home 键,这些 App 就被恢复到手机桌面上了。没有 Home 键的 iPhone,在【抖动模式】下按一下手机电源键,关闭屏幕后重新打开,图标就又会重新出现。
在 iOS 12 中,您可以尝试重启设备来找回被隐藏的图标(iOS 12 隐藏桌面图标教程)。
如果您之前在【屏幕使用时间】或【访问限制】中,关掉了访问系统应用的权限,那么它也不会显示在桌面上,您可以按如下方法操作:
iOS 12 或更新系统:在 iPhone 设置中找到【屏幕使用时间】并打开,选择“内容和隐私访问限制”,轻点“允许的应用”,开启您要允许访问的应用即可。
iOS 11 或更早的系统:打开手机【设置】-【通用】-【访问限制】,输入密码之后,在里面开启您想要显示的应用,或者直接停用“访问限制”功能,在桌面上显示所有的应用图标。
删除应用重新下载
此外,若您无法通过以上方式来找回应用图标,可以先在 iPhone 【设置】-【通用】-【iPhone 存储空间】中进行查看,是否有对应的应用,可以先【卸载应用】再重新前往 App Store 进行下载看看。
需要注意的是,【卸载应用】将会保留应用的文稿和数据,【删除应用】则会清除应用所有的相关数据,且此操作不可撤销。
还原主屏幕布局
如果您设备上的应用图标很乱,经常无法找到相关应用,可以打开 iPhone 【设置】-【通用】-【还原】,点击【还原主屏幕布局】。
连上usb
setprop service.adb.tcp.port 5555
stop adbd
start adbd
拔掉usb,取消调试授权
adb kill-server
adb start-server
选中调试授权
adb connect 192.168.XX.XX:5555
如果显示如下错误:
D:\Users\xxxxx>adb devices
List of devices attached
192.168.XX.X:5555 unauthorized
则执行如下操作:
(1)
adb_usb.ini文件位置:Win(Users\Administrator.android\)、linux(/root/.android/)
Win获取VID(USB连接设备以后查看控制面板->系统->设备管理器->Android Phone->设备名称->详细信息->硬件ID->VID)
添加VID至adb_usb.ini文件末尾
重启adb,重新连接后弹出授权提示(如果无效,可以采用重新插拔USB、重启手机或者重启电脑)
(2) 进入调试模式-》开发者选项,进入开发者模式,然后再取消开发者模式,同时删除.android目录下 adbkey、 adbkey.pub
$request_uri既可以拦截匹配url,也可以匹配参数args。
$args只可以匹配请求参数。
因此如果想要区别是参数发生了拦截,还是url发生了拦截,就需要先设置$args,再设置$request_uri。
location /aa/ { #虚拟主机真正映射路径 default_type text/html; if ($args ~* "%3Cscript%3E") { return 200 'Bad Args'; } if ($request_uri ~* "%3Cscript%3E") { return 200 'Bad Url'; } proxy_pass http://8.131.93.189:8080/; } %3Cscript%3E即为<script>,发起url请求时‘<’,’{‘等特殊字符会被转义,因此nginx直接匹配转义后的字符即可。
在搭建kafka集群时,需要提前安装zookeeper集群,当然kafka已经自带zookeeper程序只需要解压并且安装配置就行了
官网: http://kafka.apache.org
yum install -y java-1.8.0
wget http://mirror.rise.ph/apache/kafka/0.8.2.1/kafka_2.11-0.8.2.1.tgz
tar -xf kafka_2.11-0.8.2.1.tgz -C /usr/local/
cd /usr/local/
mv kafka_2.11-0.8.2.1 kafka
2.配置zookeeper集群
vim /usr/local/kafka/config/zookeeper.properties
dataDir=/data/zookeeper
clientPort=2181
tickTime=2000
tickTime : 这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
initLimit=20
initLimit:LF初始通信时限
syncLimit=10
syncLimit:LF同步通信时限
server.2=192.168.184.177:2888:3888
2888 端口:表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;
3888 端口:表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader ,而这个端口就是用来执行选举时服务器相互通信的端口。
server.3=192.168.184.178:2888:3888
server.4=192.168.184.179:2888:3888
maxClientCnxns=0
maxClientCnxns选项,如果不设置或者设置为0,则每个ip连接zookeeper时的连接数没有限制
mkdir -p /data/zookeeper
echo 2 > /data/zookeeper/myid vim /usr/local/kafka/config/server.properties
broker.id=2
唯一,填数字
prot=9092
这个 broker 监听的端口
host.name=192.168.184.177
唯一,填服务器 IP
相关题目与解析
处理秘密级信息的计算机系统口令长度不得少于(),口令长度更换周期不得长于();处理机密级信息的
按规定,秘密级计算机身份鉴别口令长度不少于()位,应采取组成复杂、不易猜测的口令,并定期更换
处理秘密级信息的涉密计算机,设臵的口令长度应大于6位,更换周期为3个月。()
处理秘密级信息的涉密计算机系统口令字长度不得少于()个字符。
涉密计算机的登陆口令不能单由数字组成,且存储秘密级信息的登陆要求(),存储机密级信息的登陆要求
处理秘密级信息的计算机,口令更换周期不超过()个月。A、1B、2C、3D、4
秘密级计算机口令长度应不少于()位,更换周期不超过一个月。A.4B.6C.8D.10
处理秘密级信息的涉密计算机系统口令长度不得少于______个字符。
只要是涉密计算机,就可以存储和处理任何密级的国家秘密信息。()
处理秘密级、机密级信息的涉密计算机系统的身份鉴别尝试次数连续达()次后,系统应锁定该用户账
涉密计算机要按照国家保密局发布的BMZ1-2000《涉及国家秘密的计算机信息系统保密技术要求》规定
秘密级计算机的身份鉴别如采用用户名加口令的方式,则口令应当每月更换一次。
秘密级计算机,身份鉴别口令的更新周期为()。
处理国家秘密信息的单台计算机,应当根据所处理信息的最高密级,按照()级别涉密信息系统的有关
秘密级计算机使用口令方式进行身份鉴别时,下列所述正确的是()。A.口令长度为8位,数字和字符混排
下列符合秘密级、机密级计算机口令设置要求的是()。
涉密移动存储介质应当根据有关规定确定密级和保密期限,并视同秘密文件资料进行管理。()
存储国家秘密信息的计算机媒体,应按______标明密级,并按相应密级的文件进行管理。A.所存储信
台式机共享打印机的方法
打印机(Printer) 是计算机的输出设备之一,用于将计算机处理结果打印在相关介质上。衡量打印机好坏的指标有三项:打印分辨率,打印速度和噪声。 打印机的种类很多,按打印元件对纸是否有击打动作,分击打式打印机与非击打式打印机。下面是jy135小编收集整理的台式机共享打印机的方法,欢迎阅读。
台式机共享打印机方法一:
1、将一台电脑和打印机用数据线连接好,打印机处于开机状态,然后把打印机驱动CD插入CD-ROM驱动器。
2、光盘插入后,电脑会弹出安装界面,根据安装向导,按照提示一步一步进行选择即可。
3、最后安装完成后,可以打印测试页验证机器打印是否成功。
4、点击“开始”--“设置”--"打印机和传真"--在三星打印机的图标上右键共享即可。
台式机共享打印机方法二:
1、知道别的计算机共享了打印机和打印机的共享名,并查看其IP地址。
2、找到这台共享的打印机
a: 方法一,打开开始菜单,单击“运行”按钮,在输入框内输入图中IP地址。
b: 方法二,打开网络,在网络的计算机列表中找到共享这台打印机的计算机名,双击打开。
3、打开这台计算机的共享,我们可以找到这台打印机,右键单击打印机,点击“连接”。
4、会自动提示从共享打印机的这台电脑获取并安装驱动程序,点击“安装驱动程序”按钮。
5、安装完成后,打开控制面板,找到“硬件和声音”下的“查看设备和打印机”、或者在控制面板以“大/小图标”显示的状态下,点击“设备和打印机”。
6、在打开的“设备和打印机”界面,在这台打印机上单击右键,点击“设置为默认打印机”,设置为默认后即可正常使用。
台式机共享打印机方法三:
1、打开桌面上的网上邻居,然后点击设置家庭或小型办公网络
然后点击下一步、再点击下步,
选择是然后下一步,到文件和打印机共享选择启用
到快完成的那一步选择完成该向导就可以了,然后将台式机的设置里面将需要共享的打印机设置为共享,
设置完毕后重启电脑,在笔记本上上添加打印机,选择网络打印机,找到相应的打印机进行添加,添加完毕后在打印时选择相应的打印机就可以了。
【台式机共享打印机的方法】相关文章:
【导语】一个完整的职业规划由职业定位、目标设定和通道设计三个要素构成。以下是无忧考网整理的IT行业个人职业生涯规划,欢迎阅读!
IT行业个人职业生涯规划篇一
距雅典不远有一座古希腊的圣城叫德尔斐,这里是传说中的太阳神阿波罗的驻地,但现在这座古城最有名的却是哲人塔列斯刻在太阳神圣殿外的一句传世名言:“人啊,认识你自己!”。
很多人非常优秀,但终没有达成的原因在于无法真正认识和掌控自我,不清楚自己真正想要的是什么,所以真正能得到的也当然是个未知数。特别是在it这样一个充满活力又极端残酷的特殊行业中,每天都在创造着新的传奇,创造与*,裂变与整合,竞争与合作,it人很难过着平淡而惬意的生活,更多非常优秀的it人士并没有真正了解和正视过自己究竟需要怎样的生活,也没有考虑过什么样的职业发展才真正适合自己。
相对优秀的会一步一步由基层的专业研发人员,成为项目经理、技术总监、研发执行总裁,也有很多人会选择自主创业,但更多的是平淡无奇的继续履行着普通研发者的生涯,等着比普通行业的人员更早的更无情的被淘汰。认识自我是人生在职业生存的环境中,我往往会把职场中打工的人分为两部分,一是优势群体,这种人完全可以自主选择掌控职业生涯,自由广泛的挑选工作,并充分应对工作;另一种人是弱势群体,不得不为在继续职场生存而担惊受怕,被动的经历着职位的挑选和筛掏。成为第一种的人,往往会达到双赢,他离职的单位对他的评价会很高,失去他会觉得是一种巨大的损失;同时他出于职业道德,对曾经服务过的单位也会给予很高的评价,不会随意评论原单位的某些不当之处。
一个人为人处世的方法和能力往往是他过往经验和知识的累积,特别是it这个瞬息万变的行业,更容易感觉到多年的经验可能会因为新技术出现而在一夜之间变得一文不值,更会认为自己在工作中的优势逐渐衰弱,自身价值得到充分体现的可能性越发趋小。工作持续才能成为职业,职业经过积累才能成为经验,经验加上学习与应用才能获得职业重心的提升。所以,对以下三个问题要反复斟酌,充分论证,综合分析,以确定自己的职业生涯路线。
(1)我希望往哪一方向发展?
(2)我正在往哪一路线发展?
(3)规划和目标者的适合我吗?
要以自己的才能、性格、兴趣、最有利的环境等综合因素配置。通常分短期、中期、长期和人生目标。短期目标一般为一至二年,可以拆分成日目标、周目标、月目标、年目标。中期目标一般为三至五年。
长期目标一般为五至十年。需要考量的、与职业选择相关因素有:
(1)性格与职业的合适度:团队性、责任感、进取心、自律性、灵活性、自主性、支配性等。
(2)兴趣因素:偏好、现实性艺术性、社会性、事业性和传统性。
(3)能力条件:语言与表达能力、数字运算、逻辑判断、整合与分析、机械推理、空间想象、沟通技巧、创新、解决、处理。
(4)外部因素和附加条件:所在国家、城市的客观因素、家庭条件等。
在确定了职业生涯目标后,行动便成了关键的环节。没有达成目标的行动,目标就难以实现,也就谈不上事业的成功。永远不变的是变化,影响职业生涯规划的因素诸多。有的变化因素是可以预测的,而有的变化因素难以预测,就须不断地对职业生涯规划进行评估与修订。it行业里的每个人都应该好好考虑一下自己的未来,给自己未来的职业道路做一个明确的规划。
学习是一种终身的责任,每一阶段都有不同的学习重点,学习更是职业整体发展的一部分,是实现职业发展目标终身伴侣。根据it产业的特性,可以把it人的职业生涯规划分为三个大的阶段:即25-32岁,33-40岁,40-65岁。第一阶段—积累和发展期在25、26岁时,有两三年基本的经验和能力,为自己准确定位就开始成为首要的事情。如果选择终身打工,就要很清楚自己每一阶段要获得的收入,要做到的职位,下一步需要的工作背景。如果一个进阶序列的职位都不适合自己,就要考虑可能转换工作性质。
同样一般企业用人时,会把25、26岁的人群看得比较重,会尊重和重视他们,让他们有发挥展示的机会。25-32岁之间是不断积累的阶段,这一期间可以迎来it人打工的最辉煌时期,包括地位和收入。第二阶段-成熟和挑战期基本小成以后要开始抉择是否创业。尽管it企业对流动资金的要求比一般企业来说并不算多,同时对于其他综合管理的能力来讲,也并不是,但it人士的专业性,往往束缚他们成为优秀的商人。通常有两类人创业是值得鼓励的,一种是有全面掌控能力的人,一种是有绝对专业技术的人。
全面掌控意味着对全面预算、全面营销、全面掌控人力、物力资本的流转、全面管理;绝对专业意味着掌握和预计研发的项目或产品在未来有持续先进性甚至是引导性,并具有商业化应用的可操作性。即使是创业也要考量自己手头积累的综合资源和技能,尽量在交互产业、交互技术、交互领域去发展,不要盲目多元化构思创业,一定要进行充分详尽和深入地进行可行性分析和预测。如果不选择创业这时期,it人士的人生目标和组织的目标得了最后实现的机会,是他职业生命的延续,在企业里承担重大职责,或者是权威专家的角色,他们追求在这个岗位上稳稳当当地尽职尽责直到光荣退出这个圈子。
IT行业个人职业生涯规划篇二
摘要:职业生涯规划设计对高职学生的职业发展具有重要的指导意义。目前大学生就业形势严峻,高职大学生对职业生涯缺乏认识,通过分析职业生涯规划现状,提出IT类大学生职业生涯设计实施方案,期望能够帮助大学生顺利择业,成功就业。
关键词:高职;职业生涯规划设计;IT;职业定位
“大学生职业生涯规划设计,是指大学生客观认知自己的能力、兴趣、个性和价值观,发展完整而适当的职业自我观念个人发展与组织发展相结合,在对个人和内部环境因素进行分析的基础上,深入了解各种职业的需求趋势以及关键成功因素,确定自己的事业发展目标,并选择实现这一目标的职业和岗位,编址相应的工作、教育和培训行动计划,制定出基本措施,高校行动,灵活调整,有效提升职业发展所需的执行、决策、和应变技能,使自己的事业得到顺利发展,并获得程度的事业成功。”这个过程正是高等职业学生最需要自觉实现的过程。目前,面临巨大的就业压力,IT类大学生开展职业生涯规划设计意义重大。
一、职业生涯规划现状
1.职业生涯规划意识淡薄
通过企业招聘的笔试和面试,我们发现,应届高职学生普遍缺乏职业生涯规划意识,他们对制作简历、写自荐信、搜集就业信息、准备面试、就业基本礼仪等常识性问题了解甚少,应聘时,只知道投简历,没有明确的职业岗位要求,没有个人的发展目标和思路。在与用人单位沟通时,过分关注经济利益,过分关注专业对口,而不考虑职业前景与长远发展,更不考虑个人的能力和自身的优劣势,择业盲目,职业生涯规划意识淡薄。部分学生还认为在职业生涯规划是工作以后考虑的事情,在大学阶段为时过早,但当他们毕业面临就业时却毫无准备、束手无策。
2.自我分析不足,职业定位不准确
由于缺乏对自身兴趣爱好、专业特长、家庭背景、行业形势等的全面分析,尤其是对社会发展、市场前景的判断及适应能力较弱。这使他们在职业生涯规划过程中易走入误区,暴露出职业定位模糊等问题。在调查中发现,大部分IT类学生对于本专业的行业状况没有进行过调研,也不了解相关行业的发展前景、用人制度、企业文化、人际关系等等,对自己将要从事的职业一知半解,很少考虑自己的职业定位,走一步算一步。
3.职业价值观偏颇
通过与学生私下的交流,发现许多学生把薪水和待遇作为职业选择的首要因素,过于注重个人的自我感觉,很少考虑社会的实际需求和人生发展的规律,没有把自己可持续的职业发展放在重要位置,没有对自己进行正确的认识、评估和对职业环境进行全面了解。在择业中明显存在着追求实惠和功利化的倾向,看重大城市、大企业、大单位,只顾暂时的利益取舍,不考虑长远的发展前景。
4.缺乏职业生涯规划的指导
目前,我国绝大多数高职院校只在学生毕业的时候开设就业指导课,而对于刚刚进入大学的学生却缺乏职业引导,缺乏对该专业当前的就业形势与就业政策的分析,从而没有及时为学生提供面试技巧、择业心理、简历书写等深层次的服务。这在一定程度上也造就了毕业生就业难、职业发展错位的问题。职业生涯规划不是一蹴而就的事情,而是高校的就业环节中一项长期的任务。
二、IT职业生涯规划设计
1.树立正确的职业理想,确立明确的职业目标
职业思想是指人们对未来职业表现出来的一种强烈的追求和向往,是人们对未来职业生活的构想和规划。任何人的职业理想必然要受到社会环境、社会现实的制约。社会发展的需要是职业理想的客观依据,凡是符合社会发展需要和人民利益的职业理想都是正确的,并具有现实的可行性。大学生的职业理想更应把个人志向与国家利益和社会需要有机地结合起来。职业理想形成后,每个人都会确立明确的职业目标。在职业生涯中,人生的职业目标有短期目标和长期目标以及近期目标和长远目标之分,而且在一定时期还有可能对职业目标提出一定的调整。所以,高职学生应当尽快确定自己的职业目标,打算成为哪方面的人才,打算在哪个领域成才等等。对这些问题的不同答案不仅会影响个人职业生涯的设计,也会影响个人成功的机会。
2.评估环境、认识自我,进行准确的职业定位
高职学生在制定IT职业发展规划时首先要进行的是职业环境评估以及职业自我评估,一方面,要了解IT行业前景,IT业所需知识,成功的必要条件,各种利弊、报酬以及晋升机会等职业环境要素,才能把握职业机会。另一方面,要客观全面地认清自我,充分了解自己的职业兴趣、能力结构、职业价值观、行为风格、优势与劣势等是否适合IT行业。
了解IT业是否是自己的兴趣所在,思考自己在该行业中到底适合做一名技术人才、销售人才抑或是管理型人才。
IT产业是知识密集、技术密集的产业,IT人才市场往往集中在经济发达的地区,因此,在进行职业生涯设计时,要考虑到经济发达地区的职业需求特点,如该地区的特殊政策、环境特征等。在进行职业生涯设计时,不能仅要看单位的大小、名气、工资待遇,而要看该职业在IT行业的现状和发展前景,如人才供给情况、平均工资状况、未来发展趋势等。
3.构建合理的知识结构
知识的积累是成才的基础和必要条件。人们常常把一个人掌握知识的多少作为衡量水平高低的标准,但这不是衡量人才的绝对标准。大学生既要具有相当数量的知识,又要形成合理的知识结构;既要能很好地适应社会需要,又要能充分体现个人特色;既要满足专业要求,又要有良好的人文修养;既要能发挥群体优势,又要能展现个人专长。在进行职业生涯设计时,大学生要能够根据职业和社会不断发展的具体要求,将已有知识科学地重组,建构合理的知识结构,限度地发挥知识的整体效能。IT类大学生除了具备IT专业知识外,还应该积极学习社交礼仪、市场营销、艺术设计等专业课程,帮助自己提升未来的就业砝码。
4.培养职业需要的实践能力
高职IT类大学生的综合能力和知识面是IT从业人员的重要考核依据。IT业不仅考核学生计算机方面的专业知识和技能,而且还考核其综合运用知识的能力、对环境的适应能力、对文化的整合能力和实际操作能力等。因此,大学生进行职业生涯设计,除了构建自己合理的知识结构外,还应具备从事IT行业岗位工作的基本能力和某些专业能力,只有将合理的知识结构和适用社会需要的各种能力统一起来,才能立于不败之地。一般来说,应重点培养满足社会需要的决策能力、创造能力、社交能力、实际操作能力、组织管理能力和自我发展的终身学习能力、心理调适能力、随机应变能力等。
三、职业生涯设计应注意的问题
1.结合社会人才需求设计职业生涯
大学生对职业的选择是不能脱离社会需要,要注意社会与个人利益的统一,社会需要与个人愿望的有机结合。在进行职业生涯设计时,应积极把握社会人才需求的动向,把社会需要作为出发点和归宿点,以社会对个人的要求为准绳,既要看到眼前的利益,又要考虑长远的发展,既要考虑个人的因素,也要自觉服从社会需要。
2.结合所学专业设计职业生涯
IT类大学生经过短期的专业学习,具有一定的IT专业知识和技能,就可以确定自己的培养目标和就业方向,可以进行专业方面的职业生涯设计。用人单位对毕业生的需求,一般首先选择的是大学生的专业特长,大学生迈入社会后的贡献,主要靠运用所学的专业知识来实现。需要强调的是,大学生所学的专业知识要精深、广博,除了要掌握宽厚的基础知识和精深的专业知识外,还要拓宽专业知识面,掌握或了解与本专业相关的若干专业知识和技术。
3.根据个人兴趣与能力特长设计职业生涯
职业生涯设计要与自己的个人性格、气质、兴趣、能力特长等方面相结合,充分发挥自己的优势,扬长避短,体现人尽其才、才尽其用的要求。大学生在职业生涯设计时,要对自己的兴趣有一个客观的分析,对自己的兴趣爱好进行重新培养和调整。能力特长对职业的选择起着筛选作用,是求职、择业以及事业成功的重要保证。知识多、学历高不一定能力强,大学生切不可以学习成绩作为评价能力高低的惟一尺度。大学生应在对自己的能力特长有一个正确的自我认知和评价的基础上,根据自己的真才实学和能力特长进行职业生涯设计。
由于IT技术的发展日新月异,IT类学生的职业生涯规划也是动态的、可持续的。从学生职业规划的时序上看,学生个人发展的每个阶段都是协调的,每一阶段又是上一阶段的升华、调整的结果,体现了一种发展上的连续性。即一个人为实现他的职业生涯目标必须进行的实践活动只是一个连续不断的从一个阶段向另一阶段进步的过程。这个发展不仅是量变的过程,更是质的飞跃。这一阶段的发展能为下一阶段或整个人生经历打下基础,具有解决实践中不断出现问题的能力。
职业生涯规划的本质特征在于追求人的发展的化。这就决定了职业生涯的规划不局限于在学校受教育阶段,而是整个人生历程中都要坚持学会学习、学会做事、学会合作、学会反思、学会发展,进而使人生的潜力得到化的展示,最终实现预期的人生价值。
参考文献:
[1]孙福权,秦燕,IT职业生涯规划.东北大学出版社,2007.
[2]赵伟乾,周爱兰,论高职艺术类大学生职业生涯规划教育.就业与创业,2009.
IT行业个人职业生涯规划.doc
下载Word文档到电脑,方便收藏和打印[全文共6093字]
编辑推荐:
下载Word文档
业界常用的服务注册与发现组件对比 了解服务注册与发现的基本原理后,如果你要在项目中使用服务注册与发现组件,当面对众多的开源组件该如何进行技术选型?
在互联网公司里,有研发实力的大公司一般会选择自研或者基于开源组件进行二次开发,但是对于中小型公司来说直接选用一款开源软件会是一个不错的选择。
常用的注册与发现组件有eureka,zookeeper,consul,etcd等,由于eureka在2018年已经宣布放弃维护,这里就不再推荐使用了。
业界开源组件
下面结合各个维度对比一下各组件。
组件优点缺点接口类型一致性算法zookeeper1.功能强大,不仅仅只是服务发现;
2.提供watcher机制可以实时获取服务提供者的状态;
3.广泛使用,dubbo等微服务框架已支持;1.没有健康检查;
2.需要在服务中引入sdk,集成复杂度高;
3.不支持多数据中心;sdkPaxosconsul1.开箱即用,方便集成;
2.带健康检查;
3.支持多数据中心;
4.提供web管理界面;不能实时获取服务变换通知restful/dnsRaftetcd1.开箱即用,方便集成;
2.可配置性强1.没有健康检查;
2.需配合三方工具完成服务发现功能;
3.不支持多数据中心;restfulRaft
从整体上看consul的功能更加完备和均衡。接下来以consul为例详细介绍一下。
Consul——值得推荐的服务注册与发现开源组件 简单认识一下Consul Consul是HashiCorp公司推出的开源工,使用Go语言开发,具有开箱即可部署方便的特点。Consul是分布式的、高可用的、 可横向扩展的用于实现分布式系统的服务发现与配置。
Consul有哪些优势? 服务注册发现:Consul提供了通过DNS或者restful接口的方式来注册服务和发现服务。服务可根据实际情况自行选择。健康检查:Consul的Client可以提供任意数量的健康检查,既可以与给定的服务相关联,也可以与本地节点相关联。多数据中心:Consul支持多数据中心,这意味着用户不需要担心Consul自身的高可用性问题以及多数据中心带来的扩展接入等问题。 Consul的架构图 Consul架构
Consul 实现多数据中心依赖于gossip protocol协议。这样做的目的:
不需要使用服务器的地址来配置客户端;服务发现是自动完成的。健康检查故障的工作不是放在服务器上,而是分布式的。 Consul的使用场景 Consul的应用场景包括服务注册发现、服务隔离、服务配置等。
服务注册发现场景中consul作为注册中心,服务地址被注册到consul中以后,可以使用consul提供的dns、http接口查询,consul支持health check。
服务隔离场景中consul支持以服务为单位设置访问策略,能同时支持经典的平台和新兴的平台,支持tls证书分发,service-to-service加密。
服务配置场景中consul提供key-value数据存储功能,并且能将变动迅速地通知出去,借助Consul可以实现配置共享,需要读取配置的服务可以从Consul中读取到准确的配置信息。
总结 这份面试题几乎包含了他在一年内遇到的所有面试题以及答案,甚至包括面试中的细节对话以及语录,可谓是细节到极致,甚至简历优化和怎么投简历更容易得到面试机会也包括在内!也包括教你怎么去获得一些大厂,比如阿里,腾讯的内推名额!
某位名人说过成功是靠99%的汗水和1%的机遇得到的,而你想获得那1%的机遇你首先就得付出99%的汗水!你只有朝着你的目标一步一步坚持不懈的走下去你才能有机会获得成功!
成功只会留给那些有准备的人!资料免费领取方式:戳这里
那些有准备的人!资料免费领取方式:戳这里
https://cloud.tencent.com/developer/article/1582979 step1 新建一个表testgraph,用来存放查询的数据。
DROP TABLE IF EXISTS `testgraph`; CREATE TABLE `testgraph` ( `id` int(10) NOT NULL AUTO_INCREMENT, `create_time` datetime(0) NULL DEFAULT NULL, `value` int(20) NULL DEFAULT NULL, `metric` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1; 在表中添加如下数据,用来测试,注意create_time特意填入的日期每个都不一样,不是同一天。
step2 打开grafana,选择折线图表并选择mysql数据源。
选择SQL Edit模式,在编辑框中输入以下sql语句:
SELECT create_time AS "time", value,metric FROM testgraph WHERE $__timeFilter(create_time) ORDER BY create_time desc 我们来回顾一下sql语句的格式:
原标题:高考成绩差:这9所“二本大学”的计算机专业不错!值得报考!
“都说考不上985、211大学,即便是考上一般的大学,出来都一样不好就业。我孩子成绩不算太好,我估计也就考个二本,现在主要是担心,毕业了更不好就业。”
“孩子想学计算机专业,但是国内一些实力比较不错的大学都很难考。孩子的成绩不是很好,最多考个二本,有没有哪些二本大学的结算及专业不错的?”
计算机专业一向都是很多高考生填报关注最多的一个专业,事实上这个专业确实很好就业,不管是男生报考还是女生报考,本科生还是专科生,都很适合。而且计算机类专业包含不少的专业,大家报考的时候,选择面也比较广。
所以最好是提前了解一下想要报考什么样的计算机专业,一定要了解各专业的课程,以及录取限制等条件。不同的专业要求也会不一样,所以最好是对了解一下具体的信息比较好。
对于成绩好的学生来说,考入国内计算机专业实力强的大学,毕业了肯定发展的更好。但是并不代表一些普通的二本大学就不知的报考了。我今天要专门分享9所计算机专业很不错的二本大学。对于想要报考计算机专业的二本考生来说,可以参考一下:
1、广西师范大学——位于: 广西,师范类大学;广西师范大学的化学专业是ESI全球前1%的学科,但是实际上计算机专业同样实力也不错,很值得报考的;
2、桂林理工大学——位于: 广西桂林市,理工类大学;虽然桂林理工大学的资源勘查工程、 勘查技术与工程等专业实力不错,但是学校的信息科学与工程学院设置的专业却很不错的;
3、厦门理工学院——位于: 厦门市,理工类大学;厦门理工大学的车辆工程实力算是很强的了, 不过如果对计算机类专业感兴趣的话,可以了解一下该校的计算机与信息工程学院,实力不错;
4、江西师范大学——位于:江西省,师范类大学;学校的计算机科学与技术专业、网络工程专业实力都算是非常不错的专业了,很值得报考,毕业生认可度挺高的;
5、长春工业大学——位于:长春市,理工类大学;长春工业大学的计算机科学与技术专业本身就是国家级特色专业,所以实力算是很厉害的了,报考的话还是很靠谱的;
6、浙江工商大学——位于:杭州市,财经类大学;浙江工商大学的计算机科学与工程学院开设的专业实力都算是不错的,感兴趣的可以了解一下,学校的位置还是挺有优势的;
7、大连大学——位于: 辽宁省大连市,综合类大学;这所学校一些特色类的专业还是挺多的,比较适合当地的学生报考。当然学校的信息工程学院设置的几个计算机类专业倒是挺不错的;
8、温州大学——位于: 浙江省温州市,综合类大学;温州大学的名气虽然不大,但是学校却又一流专业:化学、中国语言文学;当然综合类大学的学科都比较的完善,计算机类专业同样也算是很受认可的;
9、常州大学——位于:常州市,理工类大学;学校的计算机科学与技术本身也算是常州大学的重点专业了,所以实力肯定是很不错的,报考的话还是能够学到真东西的;
最后,今天就暂时分享到这里了、想要了解更多有关填报志愿、高考、大学、专业、家庭教育等相关的信息,可以关注我!返回搜狐,查看更多
责任编辑:
在HTML中,可以使用type属性设置语言为中文,只需要给html元素设置“lang="zh"”代码即可。属性lang是英语“language”的缩写,意思是语言,声明当前页面的语言类型;当值为“zh”时,表示当前页面的语言类型是中文。
本教程操作环境:windows7系统、CSS3&&HTML5版、Dell G3电脑。
如果中文网站建议设置这个,不然浏览器以为你是英文的看到有个单词就提示翻译就很烦,开发开发着发现才有好多细节需要记录
新建模板都是这样的
...
我们需要改成
...
扩展资料:
通常,"en" 表示英语(English)、"ja" 表示(Japanese)、"zh-cn" 表示简体中文等等。
zh 是中文,代表的是宏语言(Macrolanguage),zh 单独用表示中文整体,可以是方言、文言文、简繁体等混合内容,毕竟大陆地区大部分人都能认识不少繁体字,台湾地区大部分人也能认识很多简体字。理论上 zh-CN 表示的是中国大陆中文,包含方言和简繁体,但默认指简体普通话,局限性就体现出来了,没法表达繁体普通话,这时为了精准性,应该用独立语种替换,包括但不仅限于普通话和七大方言:
cmn 普通话(官话、国语)
wuu 吴语(江浙话、上海话)、czh 徽语(徽州话、严州话、吴语-徽严片)
hak 客家语
yue 粤语(广东话)
nan 闽南语(福建话、台语)、cpx 莆仙话(莆田话、兴化语)、cdo 闽东语、mnp 闽北语、zco 闽中语
gan 赣语(江西话)
hsn 湘语(湖南话)
cjy 晋语(山西话、陕北话)
推荐学习:html视频教程
目录
案例简介
第一步:确认数据真实性
第二步:明确定义,并拆解指标,进一步定位原异常部分
第三步:根据几个常见维度初步拆分数据
第四步:进一步做假设并细分深入,得出结论
案例分析
例题
GMV下降了20%怎么分析?(GMV=访客数(uv)*订单转化率(cr)*单均价)
总结
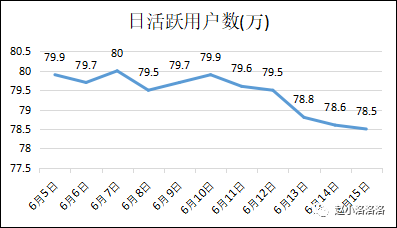
例题部分转载自公众号《阿狸与小兔》。 案例简介 一款信息流APP平时日活稳定在79w-80w之间,但是在6月13日起突然掉到了78.8w,到6月15日已经掉到78.5w,这时产品负责人着急了,让你尽快排查一下数据下跌的原因。这样的问题对大多数人来说还是比较头疼的,因为对于80w量级的产品,一两万并不是一个非常大的波动,但原因还是要排查。
核心点:先做数据异常原因的假设,后用数据验证假设。
不建议大家第一步先自己对着数据去拆,影响日活数据的因素很多,不可能把所有维度逐一拆解对比,容易浪费时间却没有任何有价值的发现。做数据异常原因分析的核心就是结合以往经验及各种信息,找出最有可能的原因假设,通过数据的拆分进行多维度分析来验证假设,定位问题所在。过程中可能会在原假设基础上建立新的假设或者是调整原来假设,直到定位原因。
第一步:确认数据真实性 在开始着手分析前,建议先确认数据的真实性。我们经常会遇到数据服务、数据上报、数据统计上的BUG,在数据报表上就会出现异常值。所以,找数据流相关的产品和研发确认下数据的真实性吧。
第二步:明确定义,并拆解指标,进一步定位原异常部分 逻辑树模型的思维,由大到小,一步一步深入。(指出拆解方法的局限性:假设缺陷、分布缺陷、估算保守/激进)
第三步:根据几个常见维度初步拆分数据 可以利用人货场模型来思考,如下图

计算影响系数:每一项数据都要和以往正常值做对比,算出影响系数。
影响系数 =(今日量-昨日量)/(今日总量-昨日总量)
影响系数越大,说明此处就是主要的下降点
以上是几种常见的初步拆分维度,通过初步拆分,定位原因大致范围。
第四步:进一步做假设并细分深入,得出结论 针对初步定位的影响范围,进行进一步的排查。分三个维度来做假设,建议针对数据异常问题专门建一个群,拉上相应的产品、技术、运营人员一起,了解数据异常时间点附近做了什么产品、运营、技术侧调整。
定位了异常部分后,可根据分指标灵活思考出影响因素。
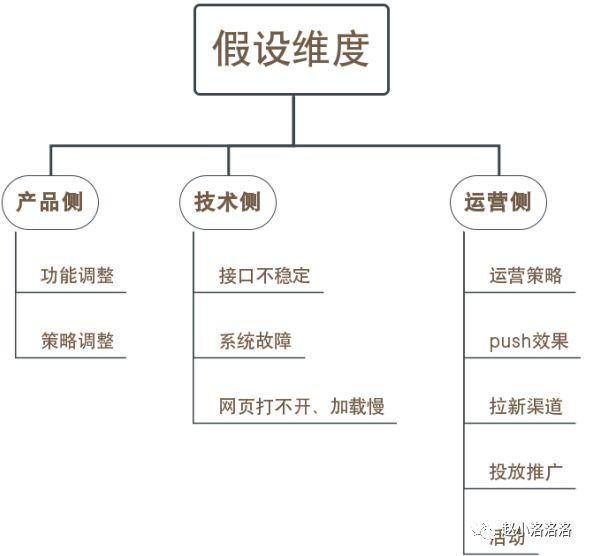
综合考虑以往数据异常原因、产品运营技术侧调整、初步定位的影响范围最可能由什么原因造成,再结合自身业务经验确定几个最可能的原因假设,给这些假设排数据验证的优先级,逐一排查。
除了上述,可以细分分析的维度实在太多,逻辑上说核心点在于一个假设得到验证后,在这个假设为真的基础上,进行更细维度的数据拆分。
我们需要记住这种分析方式,当猜测是某种原因造成数据异常时,只要找到该原因所代表的细分对立面做对比,就可以证明或证伪我们的猜测,直到最后找到真正原因。
案例分析 以上就是核心数据异常的分析套路,是不是刚才拿到问题还不知道从哪开始分析,现在觉得其实有很多点可以去着手?让我们回到刚才的案例吧。根据上述套路,首先我们拆分新老用户活跃量,如下图(老用户左轴、新用户右轴):
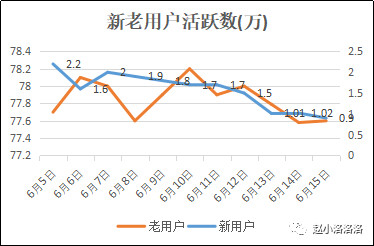
发现老用户日活较平稳,但是新用户自6月13日下降严重,于是计算新老用户影响系数:
老用户影响系数 =(77.89-78)/(78.8-79.5)=0.16
新用户影响系数= (0.98-1.5)/(78.8-79.5)=0.84
新用户影响系数0.84,说明DAU下降是出在新用户身上,明确范围后进一部细分,新用户由什么构成?
新用户=渠道1+渠道2+渠道3+其他渠道 ,于是我们把新用户日活按渠道进行拆分:
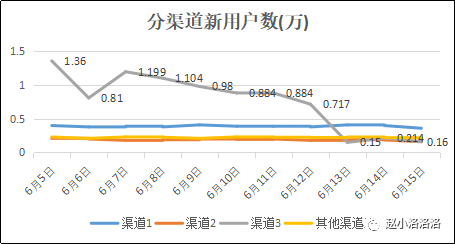
通过渠道拆分,我们发现渠道3自6月13日起新用户下降严重,于是我们把问题定位在渠道3,应该是渠道3的渠道效果发生问题。联系渠道3的负责人一起定位具体原因,渠道线索量降低?渠道转化率降低?渠道平台的问题?找出原因后,再针对原因解决问题,制定渠道优化策略。
例题 GMV下降了20%怎么分析?( **GMV=访客数(uv)订单转化率(cr)单均价 ) 人货场角度(第一步 → (第二步) → 第三步 → 第四步):
1、从人的角度来看。主要会考虑
① 新老客户
② 不同地区客户
vue-d3.js绘制柱状图(含动画和交互) 1、安包 npm install sass-loader -D
npm install node-sass -D
cnpm install node-sass -D
cnpm install core-js@2
2、代码 <template> <div class="d3Chart"></div> </template> <script> import * as d3 from "d3"; export default { mounted() { // 数据——x轴的标签——城市 let labelList = ["成都", "武汉", "上海", "北京", "深圳"]; // 数据——对应y轴的值——城市人口(万) let dataList = [100, 105, 200, 250, 230]; // 画布的参数 let mapWidth = 300; let mapHeight = 300; let mapPadding = 30; // 定义画布—— 宽 300 高 300 外边距 10px let map = d3 .
原标题:电脑开机出现英文字母怎么办?
关注奕奇科技,学习更多小妙招
解决电脑开机时出现英文字母是一个非常好用的电脑技巧,但是许多小伙伴还不了解具体操作方法,一起来学习一下。
开机时常按住del键不同的电脑型号有不同的按键, 进入BISO界面(在bios界面中 方向键选择、回车键确认、ESC键返回)
进入后通过键盘的左右方向键选择进入 BOOT下 然后将第一启动项改为装载系统的硬盘名称 设置完按f10保存重启 (在boot界面下 f5或f6 调到第一位的意思、f10 保存并重新启动 )
以防找不到可以收藏哦!
1.开机不停按del键。
2.设置BIOS,选择Load Optimized Defaults。3.F10保存退出。
4.可能原因出在内存条,显卡金手指氧化,插槽接触不良,导致电脑无法开机。
5.断开电源,打开电脑机箱,把内存条拔出
。6.用橡皮擦对着金手指的部位来回擦几下。
7.换一根内存槽插回去。
8.开机不停按F8。
9.进入高级,选择最后一次正确配置,确定。
·END·
奕奇科技
助力企业搭建PC端及移动端线上营销产品返回搜狐,查看更多
责任编辑:
后端开发常用工具指令(To be Continue) Ubuntu终端Virtualenv(windows环境)Virtualenv(ubuntu环境)DjangoMySQLNginxUwsgiDockerVimVim编辑器配置Git端口占用版本号 Ubuntu终端 #文件重命名 mv 旧名字 新名字 #创建文件 touch 文件名 #创建文件夹 mkdir 文件 #删除文件 rm 文件 # 复制文件 cp 文件名 路径/新文件名 # 查看文件 more/cat 文件名,more只显示第一页,cat显示全部 # 编辑文件 vi 文件名 #文件压缩和解压 压缩格式:tar -zcvf 压缩后的文件名 将要压缩的文件 解压格式:tar -xf 压缩后的文件名 解压zip:unzip 解压文件名 查看解压:zcat 压缩后的文件名 #scp传输工具 scp 要传输的文件 将本地文件推送到远程主机 #文件备份 date [option] #生成密钥对 ssh-keygen -t rsa -P "" -N "" Virtualenv(windows环境) #1、下载virtualenv pip install virtualenv #2、创建一个virtualenv工作目录 mkdir myproject_env #3、创建一个python项目 virtualenv venv #4、启动virtualenv中的venv项目 1.