目录
开题报告
1.实验背景
2.实验目的、意义
3.研究内容
4.技术路线
5.难点内容
6.预期结果
1.实验背景 互联网在社会、经济、以及人们的日常生活中都是必不可少的工具,而互联网的稳定运行是互联网技术能够广泛应用的前提,因此网络监控技术应运而生。网络监控技术能够监控网络整体运行状态,可以提前预判网络中可能存在的问题,进而采取措施,保证网络的稳定运行。本系统采用的基于Zabbix软件的监控系统不仅能够监控网络系统,还可以扩展到其他方面的应用。
计算机网络技术发展迅速,网络在我们学校师生的生活、工作和学习中已经成为必不可少的工具。在网络需求量越来越大的情况下,保障网络运行稳定性,也成为在校师生密切关注和关心的问题。在这样的背景下,对于网络维护人员提出了更高的要求,拥有一个优良的网络设备监控平台就显得尤为重要,通过网络设备监控平台,观察各设备的运行状况,对运行情况进行数据分析,对问题设备及时处理,甚至实时监控和报警,这样才能够尽快处理全校师生在使用网络时遇到的各种问题。
2.实验目的、意义 在当前的开源服务器监控软件中比较热门的有Nagios、Ganglia、 OpenTSDB 、Zabbix等开源软件,每个软件都有自己的特点和功能。
在开源的软件中(Zabbix,Nagios,Cacti等),开源的解决方案有流量监控和性能告警,而且每种软件都有自己特点和功能,各自的侧重点和目标不完全相同,在设计理念和实现方法上也大同小异,更多思想放在服务器监控的属性以及监控流程上,但是随着服务器数量的成倍增加,产生的数据将成倍增加,数据的读写成为最大的问题,所以简单的开源软件的使用已无法满足当前的需求。
学校网络设备监控平台采用的是多年前购买的PRTG平台,PRTG平台是一款通过路由器等设备上的SNMP协议取得流量资讯并产生图形报表的软件,可以为我们产生内部网络包括服务器、路由器、交换机、员工计算机等多种设备的网络流量图形化报表,并能够对这些报表进行统计和绘制。但在具体的使用过程中,仍然暴露出许多问题,我们学校的PRTG平台仅能监控汇聚交换机出入口流量,无邮件报警等及时的问题警告方式,在使用过程中需要人工不断地进行关注平台进出口流量信息来做出判断,对学校的网络硬件设备的监控缺少及时性报警和主动性报警,不能够满足出现网络问题及时发现的需要,给我们的网络管理人员带来很大的不便。
通过Zabbix平台对学校所有交换机、无线AP等网络设备流量、运行状况进行监控和告警,使用第三方平台通知设备负责人员设备的异常或故障,基于Zabbix的校园网监控系统使用更加灵活,对于学校网络管理和运维人员的工作有着切实的辅助作用。
3.研究内容 基于开源系统Zabbix设计与实现监控数量大、速度快的服务器监控方案,特别是对于大规模数据中心的基础设施的监控,从主机、网络、存储等方面实现对整个资源池的资源监控,将服务器的相关指标以可读性强的形式展现给运维人员,让运维人员充分把握服务器的各项指标,当某些指标出现异常时能够将异常以短信或者邮件的方式报给运维人员,在此基础上,分为四个核心要点 。
(1)实时图形:通过Zabbix将监控的网络设备数据绘成实时的图形。
(2)数据采集:通过Zabbix监控系统采集设备运行过程中的通断情况、进出口流量等信息
(3)异常监控:监控各核心设备机房和服务器机房的基本运行设备状态,对异常情况进行监控和记录,并触发告警机制。
(4)报警:对网络设备的运行状态故障、电力故障、接口故障等问题进行及时的报警,并可根据等级发送到不同的用户组。
4.技术路线 Zabbix是一个基于WEB界面的提供分布式系统监控以及网络监控功能的企业级的开源解决方案,采用多种方式进行数据采集,它将采集到的数据先存入数据库,然后对数据做进一步的分析与整理,达到阙值条件的就触发告警,不仅有专门独立的Agent,还可以使用支持SNMP、Telnet、SSH、IPMI、JMX等多种协议的方式。其扩展的灵活性和功能的丰富程度是其他监控系统所不能比的。能监视各种网络参数,保障网络系统的安全运营;并提供灵活的通知机制以让系统管理员快速定位和解决存在的各种问题。
图 1Zabbix 5.0架构
1、Zabbix Server
Zabbix server 是 agent 程序报告系统可用性、系统完整性和统计数据的核心组件,是所有配置信息、统计信息和操作数据的核心存储器。
2、Zabbix 数据库存储
所有配置信息和 Zabbix 收集到的数据都被存储在数据库中。
3、Zabbix Web 界面
为了从任何地方和任何平台都可以轻松的访问Zabbix, 我们提供基于Web的Zabbix界面。该界面是Zabbix Server的一部分,通常(但不一定)跟Zabbix Server运行在同一台物理机器上。
如果使用 SQLite,Zabbix Web 界面必须要跟Zabbix Server运行在同一台物理机器上。
4、Zabbix Proxy 代理服务器
Zabbix proxy 可以替Zabbix Server收集性能和可用性数据。Proxy代理服务器是Zabbix软件可选择部署的一部分;当然,Proxy代理服务器可以帮助单台Zabbix Server分担负载压力。
5、Zabbix Agent 监控代理
Zabbix agents监控代理 部署在监控目标上,能够主动监控本地资源和应用程序,并将收集到的数据报告给Zabbix Server。
通过Annie命令行视频下载 注:现 Annie已经改名为 lux。
当做视频目标检测时,我们常常需要非常多的视频作为数据集。今天推荐一款非常方便好用的视频下载工具 Annie(现更名为lux) 。
1.登录 Github 下载 Github 网址:https://github.com/iawia002/annie
Github 上对于Windows电脑推荐了 2 种安装方式。这里为了方便我选择了 Scoop。点击 Scoop,进入 Scoop 的官网,先安装 Scoop。
2.安装 Scoop 进入Scoop 的官网,发现需要基于 Windows 的 PowerShell 命令行进行安装。
不要以管理员身份打开 PowerShell ,输入以下命令:
Invoke-Expression (New-Object System.Net.WebClient).DownloadString('https://get.scoop.sh') 这个过程中可能要更改一些政策权限才能正常安装,输入以下命令:
Set-ExecutionPolicy RemoteSigned -Scope CurrentUser 改为yes即可,然后再输入第一条安装命令。安装成功后如下图所示:
3.安装Annie 不要以管理员身份打开 PowerShell ,输入以下命令:
scoop install lux 4.下载视频 以管理员身份打开 cmd。输入以下命令,即可下载:
lux 视频地址 视频的存储位置就是我红框标注的路径:
5.更改下载路径 若想更改下载路径,可以先在别的盘下(我这里是G:/盘) 创建一个 Video 文件夹专门存放 Annie 下载下来的视频。
然后cmd命令行先 cd 到 Video 文件夹:
C:\windows\system32>G: G:\>cd Video 再输入下载命令进行下载:
就以这个树为例,来讲讲二叉树的非递归遍历。
先序遍历: 先序遍历结果为3 4 6 5 8 9,就拿树的左枝为例,3是根,打印,4是3的左孩子,打印,6是4的左孩子,打印,6的左孩子为空,所以返回到4,然后去找4的右孩子,4的右孩子也为空,返回到3,这就是左子树遍历的过程。然后非递归主要用到栈来存储结点,栈先进后出,所以应该是右孩子先入栈,左孩子后入栈,这样pop就能先得到左孩子。先将根结点3入栈,接下来就是开始循环,循环结束的条件就是栈为空,先弹出栈顶,再打印栈顶,如果栈顶的右孩子不为null,就把右孩子放进栈中,如果栈顶的左孩子不为null,就把左孩子放入栈中。
用下面一幅图来说明整个过程
void pretravel2(TreeNode root) { if (root == null) return; Stack<TreeNode> s = new Stack<TreeNode>(); s.push(root); while (!s.isEmpty()) { TreeNode node = s.pop(); System.out.print(node.val+" "); if (node.right != null) { s.push(node.right); } if (node.left != null) { s.push(node.left); } } } 中序遍历:中序遍历的结果为6 4 3 8 5 9,其实就是左遍历完了,弹出根,找根的右结点,整个过程是先一路找左结点,找到左结点为null的6,然后找6的根4,接着找4的右,为null,接着找4的根3,接着一路找3的左,直到结点的左孩子为null,这就找到了8,然后找8的根5,再找5的右9,这样就找完了。他们的入栈出栈顺序:根结点入栈,左孩子直接入栈,并且标记这个结点已经走过,以防后面再走,当发现哪个结点的左孩子为null的时候,就打印这个结点,并且将这个结点出栈,让他的右孩子入栈
void intravel2(TreeNode root) { if(root==null) return ; Stack<TreeNode> stack=new Stack<>(); stack.push(root); //使用list来标记结点是否走过 List<TreeNode> list=new ArrayList<>(); while(!
举个例子,假设得到混淆矩阵如下:
[ 真 实 标 签 真 实 标 签 真 实 标 签 真 实 标 签 真 实 标 签 0 1 2 3 4 预 测 标 签 0 16 0 1 1 4 预 测 标 签 1 3 22 0 0 2 预 测 标 签 2 0 5 18 0 1 预 测 标 签 3 0 0 0 15 1 预 测 标 签 4 1 0 1 1 31 ] \begin{bmatrix} &&&真实标签&真实标签&真实标签&真实标签&真实标签 \\&&&0&1&2&3&4 \\ \\ 预测标签&0&&16&0&1&1&4 \\ 预测标签&1&&3&22&0&0&2 \\ 预测标签&2&&0&5&18&0&1\\ 预测标签&3&&0&0&0&15&1\\ 预测标签&4&&1&0&1&1&31 \end{bmatrix} ⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡预测标签预测标签预测标签预测标签预测标签01234真实标签0163001真实标签1022500真实标签2101801真实标签3100151真实标签4421131⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
问题如图所示,我是在GitHub加载environment.yml文件时,遭遇这种情况。
其实,这也不难解决。
其一将environment.yml文件中dependencices中,报错的部分依赖项,放到-pip:下;或者将“_libgcc_mutex=0.1=main”,这样第二个等于号后面的内容删除,这个就改为“_libgcc_mutex=0.1”
其二就是以下的可能,未找到anaconda的环境变量的位置,没法pip install
添加‘Anaconda安装目录\Library\bin’到环境变量中
例如:C:\ProgramData\Anaconda3\Library\bin
F:\Anaconda\Scripts
F:\Anaconda
F:\Anaconda\Library\bin
如若不行,conda update --all
或者
conda update -n base -c defaults conda 其三
以上都不行
可以尝试https://blog.csdn.net/weixin_42455006/article/details/123764420
拍手游戏逢有7的数字和7的倍数拍手
#方法1 for i in range(1, 101): if i % 7 == 0 or i % 10 == 7 or i // 10 == 7: print("Clap", end=" ") else: print(i, end=" ") if i % 20 == 0: #每二十个数换行 print() #方法2 for i in range(1, 101): if i % 7 == 0 or i % 10 == 7 or i // 10 == 7: print("Clap", end=" ") continue print(i, end="
1.centos
2.官网下载源码
https://github.com/opencv/opencv/tagshttps://github.com/opencv/opencv/tags3.解压
unzip opencv-4.5.5.zip cd opencv-4.5.5 4.配置
mkdir build cd build cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/data1/xxx/workspace/opencv/output .. 其中,CMAKE_BUILD_TYPE指定Release或者Debug
CMAKE_INSTALL_PREFIX指定编译以后,安装的目录
.. (点点)指定opencv源码更目录
更多配置选项,参考官网:
OpenCV configuration options referencehttps://docs.opencv.org/4.x/db/d05/tutorial_config_reference.html
由于本机已经存在了ffmpeg的老版本,导致编译报错,不想动老版本,于是把ffmepg禁用掉
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/data1/xxx/workspace/opencv/output -D WITH_FFMPEG=OFF .. 5.编译
make make install 6.hello opencv
cd .. mkdir demo cd demo vim cvdemo.cpp //cvdemo.cpp #include "opencv2/opencv.hpp" int main() { printf("hello opencv!\r\n"); return 0; } build:
g++ -g -Wall -std=c++11 cvdemo.cpp -o cvdemo -I.
问题描述:自己搭建SSM项目时候,访问后台接口报500,Java:java.lang.IncompatibleClassChangeError:Expected non-static field。
解决:百度上找的都是某个变量应该是是非static,应该是导入依赖jar相互冲突,我是导入ssm相关jar包版本并没有对齐,导入相同版本的依赖包重新put into output root,重新启动tomcat就可以了。
第一种办法:正版PD资源 Parallels Desktop17.1.2正版激活(永久授权许可证激活,正版授权,永久使用!)
最强Mac虚拟机软件(适用于 Intel和所有 Apple M1芯片,支持 Monterey)
使用须知
适用于 Intel 和 所有 Apple M1 芯片,支持 Monterey
本许可证,可以永久使用PD17.1.2,支持小版本升级,支持重装
保存好自己的激活码,重装系统,激活码依然有效!(遗失不补)
需要的➕VX:yanqi788
第二种办法:
打开系统偏好设置中的日期与时间 把系统时间改成2021 年 4 月 1日 下载安装包,安装pd,再安装win10系统 Win10安装好后,重启电脑 重启后,在此打开系统偏好设置中的日期与时间,把时间改回来 打开下载的包,把pd启动 安装到应用程序 在应用程序,打开pd启动,如果提示 试用到期,就打开Parallels Desktop。能进win系统的话,全部退出,然后用pd启动打开。如果能进去,说明成功了。。
python的魔术方法大全
转载 保存下链接
https://www.cnblogs.com/nmb-musen/p/10861536.html
说明:
本专栏的第一篇博客,只是搭建了一个完全的分布式Hadoop集群,而且当时的安装目录是在/usr/local/src/下边安装的,后来因为报错的问题,又重新搭建了一次完全分布式的集群,今天就来讲一下,如何搭建真正实现高可用的Hadoop集群。
前提:
必须完成三台节点的jdk,zookeeper的安装配置,至于hadoop的话,接着以前的环境做也可以,删掉从新解压从新配置都可以,因为我比较懒,就是接着做的。
不多废话,直接操作。
Hadoop HA搭建
1,更改环境变量
vi /etc/profile 进行如下配置(此处需先删除第四章配置的环境变量)
#hadoop enviroment export HADOOP_HOME=/opt/local/src/hadoop #HADOOP_HOME指向JAVA安装目录 export HADOOP_PREFIX=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib:$HADOOP_COMMON_LIB_NATIVE_DIR" export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin #java environment export JAVA_HOME=/opt/local/src/java #JAVA_HOME指向JAVA安装目录 export PATH=$PATH:$JAVA_HOME/bin #将JAVA安装目录加入PATH路径 #zookeeper environment export ZK_HOME=/opt/local/src/zookeeper export PATH=$PATH:$ZK_HOME/bin 保存并退出。
2,配置hadoop环境变量
cd /opt/local/src/hadoop/etc/hadoop vi hadoop-env.sh 在最下面添加如下配置:
export JAVA_HOME=/opt/local/src/jdk 保存并退出
3,修改配置文件1
vi core-site.xml 添加如下配置:
<!-- 指定hdfs的nameservice为mycluster --> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <name>hadoop.
#include<stdio.h> int main() { int i,a=0,b=0,c,n; scanf("%d",&n); for(i=0;i<n;i++) { scanf("%d",&c); if(c%2==0) { a++; } else { b++; } } printf("%d %d",b,a); return 0; }
consul服务集群搭建与测试 参考文档 架构 https://www.consul.io/docs/architecture
非官方文档
https://blog.csdn.net/junaozun/article/details/90699384
https://www.cnblogs.com/duanxz/p/10564502.html
推荐架构 https://learn.hashicorp.com/tutorials/consul/reference-architecture?utm_source=consul.io&utm_medium=docs
架构图
consul词汇表 https://www.consul.io/docs/install/glossary
AgentClientServerDatacenterConsensusGossipLAN GossipWAN GossipRPCAccess Control List (ACL)API GatewayApplication SecurityApplication ServicesAuthentication and Authorization (AuthN and AuthZ)Auto Scaling GroupsAutoscalingBlue-Green DeploymentsCanary DeploymentsClient-side Load BalancingCloud Native Computing FoundationCustom Resource Definition (CRD)Egress TrafficElastic ProvisioningEnvoy ProxyForward ProxyHybrid Cloud ArchitectureIdentity-based authorizationInfrastructure as a ServiceInfrastructure as CodeIngress ControllerIngress GatewayIngress TrafficKey-Value StoreL4 - L7 ServicesLayer 7 ObservabilityLoad BalancerLoad BalancingLoad Balancing AlgorithmsMulti-cloudMulti-cloud NetworkingMutual Transport Layer Security (mTLS)Network Middleware AutomationNetwork securityNetwork traffic managementNetwork VisualizationObservabilityElastic ScalingPlatform as a ServiceReverse ProxyRole-based Access ControlsServer side load balancingService configurationService CatalogService DiscoveryService MeshService NetworkingService ProxyService RegistrationService RegistryMicroservice SegmentationService-to-service communicationSoftware as a Service 安装 https://learn.
今天双击打开monitor.bat 出现如下报错
Error: Could not create the Java Virtual Machine. Error: A fatal exception has occurred. Program will exit. 查看原因:因为java版本过高,本地版本为解决方案:重新安装java8版本 (java8 阿里云地址 提取码: 71p0)
然后在双击打来monitor.bat
1. 什么是算术运算?什么是关系运算?什么是逻辑运算? 解析:C语言中这些东西太多了,这里只讲最常见的。
(1)算术运算最常见的有:加减乘除、自增、自减、取模
运算符(优先级):++、-- ; *、/、% ;+、-
(2)关系运算最常见的是关系运算:大于、小于、等于、大于等于、小于等于、不等于
运算符(优先级):>、<、>=、 <=; ==、 !=
(3)逻辑运算基本就是再说 “与或非” 三兄弟
运算符(优先级):!;&&、||
&&:逻辑与,要求左右两边同时为真输出才会为真;
||:逻辑或,符号左右两边只需要有一个为真输出便为真;
!:逻辑非,讲符号右边的内容在逻辑上取反;
注:这里的 !非,优先等级非常高。
以上所提到的所有操作符优先级排列:
++、-- ;!;剩下的算数运算符;关系运算符;剩下逻辑运算符
2. C语言中如何表示“真”和“假”?系统如何判断一个量的“真”和“假”? 解析:纯概念题,书上有原话,我简单概述一下。
在C语言中判断真假很简单:“0为假,非0为真”,具体判断又分为两种:“逻辑常量和逻辑变量”
逻辑常量只有两个:“0和1,0为假,1为真”.
逻辑变量,就跟他的名字一样,会变!因此,逻辑变量可以是数字、字母、符号甚至是表达式,判断方式也是0为假,非0为真。
3. 写出下面各逻辑表达式的值。设a=3,b=4,c=5。 解析:这一题就是上面两题的综合实践版。
(1)a+b>c && b ==c ——> 3+4>5 && 4==5 ——>7>c && 4==5 ——>真 && 假——>假
(2)a||b+c && b-c ——> 3||4+5 && 4-5 ——> 3||9 && -1 ——>真||真&&真 ——>真
(3)!(a>b) && !c||1 ——> !(3>4) && !5||1 ——> !
前言 本系列为精选C语言菜鸟刷题系列,意在巩固已经学习的C语言知识。每天5题,菜鸟逆袭~~~
实例1 💬题目: 输出9*9口诀。
🔍程序分析: 分行与列考虑,共 9 行 9 列,i 控制行,j 控制列。
具体代码:
#include<stdio.h> int main() { int i, j, result; for (i = 1; i <= 9; i++) { for (j = 1; j <= i; j++) { result = i * j; printf("%d*%d=%-3d", i, j, result); //-3d表示左对齐,占3位 } printf("\n");//打印每一行后,换行 } return 0; } 🚀运行结果:
实例2 💬题目: 古典问题(兔子生崽):有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第三个月后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总数为多少?(输出前40个月即可)
🔍程序分析: 这是典型的斐波那契数列问题。兔子的规律为数列1,1,2,3,5,8,13,21…,即下个月是上两个月之和(从第三个月开始)。我们采用迭代循环的方法解决。
迭代循环:重复执行一系列运算步骤,从前面的量依次求出后面的量的过程,直至满足条件为止。
🔱迭代解法: 知道初值,迭代公式,结束条件即可
#include<stdio.h> int main() { int f1 = 1, f2 = 1, i; for (i = 1; i <= 20; i++) { printf("
computed: { ...mapState('vuex子仓库名', ['allList']), localAllList() { uni.setStorageSync('allList', JSON.stringify(this.allList)); return JSON.parse(uni.getStorageSync('allList') || '[]'); }, 使用时直接当做计算属性使用即可
文中所有资源可点击此处免费下载 1、创建VUE项目,安装kindeditor
cnpm i kindeditor -S 2、在components下新建KindEditor文件夹,新建Index.vue组件,
<template> <div class="margin-top-20"> <textarea name="content" :id="id" v-model="outContent"></textarea> <div style="color: #909399">建议样式:字号18px,2倍行距,文字左对齐,图片居中对齐</div> <input type="file" @change="selectedFile" style="display: none" name="imgFile" ref="inputFile" /> </div> </template> <script> // 引入kindeditor组件 import './config/default/default.css' import "./config/kindeditor-all-min" import './config/zh-CN' // 配置文件 import items from "./config/items.js"; import htmlTags from "./config/htmlTags.js"; import fontSizeTable from "./config/fontSizeTable.js"; import otherConfig from "./config/otherConfig.js"; // import { uploadImg } from "@/api/index.js"; import { postApi } from '../../request/http'; export default { name: "
文章目录 一、题目描述二、解题思路与代码三、注意事项 一、题目描述 给你一个长度为 n 的整数数组 nums 和 一个目标值 target。请你从 nums 中选出三个整数,使它们的和与 target 最接近。
返回这三个数的和。
假定每组输入只存在恰好一个解。
示例 1:
输入:nums = [-1,2,1,-4], target = 1
输出:2
解释:与 target 最接近的和是 2 (-1 + 2 + 1 = 2) 。
示例 2:
输入:nums = [0,0,0], target = 1
输出:0
提示:
3 <= nums.length <= 1000
-1000 <= nums[i] <= 1000
-104 <= target <= 104
链接:https://leetcode-cn.com/problems/3sum-closest
二、解题思路与代码 1.暴力解法是最容易想到的。本题求与目标数最接近的三数之和,利用三重循环即可解题。发现题目数组长度范围为
3 <= nums.length <= 1000,O(N3)为10^9,超过测评机每秒运行次数,测评机每秒运行次数在10 ^8左右。因此暴力解法不可行。
目录 一、题目描述二、解题思路与代码三、注意事项 一、题目描述 给定一个只包括 ‘(’,’)’,’{’,’}’,’[’,’]’ 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
示例 1:
输入:s = “()”
输出:true
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/valid-parentheses
二、解题思路与代码 这是一道简单题,初看题目想了几种方法:双指针、递归、动态规划,但是都无从下手,最后瞟了眼题解,嘿嘿。思想还是很简单的,用栈先进先出的特性来解题,思路如下: 1.遍历字符串,将所有左括号入栈,遇到右括号时将栈顶元素弹出,判断是否匹配,若不匹配则返回false,匹配则继续遍历。 2.遍历完成后判断栈是否为空,不为空则表明没有完全匹配,返回false。 注意,遍历前可以先将奇数长度的字符串排除。 public boolean isValid(String s) { if (s == null) { return false; } if (s.length() % 2 != 0) { return false; } Deque<Character> stack = new ArrayDeque<>(); for (int i = 0; i < s.length(); i++) { char ch = s.charAt(i); if (ch == ')' || ch == ']' || ch == '}') { boolean isSame = isTopSame(ch, stack); if (!
电话号码
电话号码
a标签 href=“tel:电话号码” 这样用户点击链接手机端就会弹出呼叫啦
a标签 href=“sms:电话号码” 这样用户点击链接手机端就会跳转到短信页面,就可以发短信啦
手把手教你部署前端项目 1.1 用Vue-cli构建简易前端项目 1.1.1 安装 Vue CLI 包 打开命令行工具,执行下列命令来安装 Vue CLI 包:
npm install -g @vue/cli 可以用下面的命令查看是否安装成功:
vue --version 1.1.2 创建一个项目 新建一个文件夹,命名为simple-website,在simple-website下运行以下命令来创建项目:
vue create frontend 全部选择默认配置即可,
这个过程可能需要几分钟,请耐心等待。
1.1.3 打包项目 在simple-website/frontend目录下执行:
npm run build 1.2 登录服务器,把打包后的文件放入对应目录 如果没有购买服务器,可以把自己电脑当做服务器,可跳过该小节。
如果有购买服务器的话,登录服务器:
ssh -l root xxx.xx.xx.xxx 切换到服务器的home目录下,并新建文件夹simeple-website-frontend:
cd /home mkdir simple-website-frontend 在本地的simple-website/frontend/dist目录下执行如下命令,把打包生成的文件放入服务器对应目录下:
scp -r ./* root@120.76.53.100:/home/simple-website-frontend 1.3 服务器端nginx的安装、配置、启动 1.3.1 nginx安装 在服务器端执行:
sudo su root apt-get install nginx 查看nginx是否安装成功:
nginx -v 如果安装过程中报错Unable to locate package nginx,先执行sudo apt-get update,再执行sudo apt-get install nginx。
MSI X570 A Pro主板更新最新bios后怎么就没网络了。怎么安装网络驱动都没用。
目录
一、什么是进程
二、进程的调度
1.描述一个进程
2.组织若干个进程
3.并发和并行
4.进程的状态
5.优先级 6.记账信息 7.虚拟地址空间 8.进程之间的通信 三.线程与进程 1. 线程是什么?
2.线程的作用 3.进程和线程的区别 四.线程的创建 方法一:Thread类继承
方法二:实现Runnable接口
其他变形
变形1:匿名内部类创建Thread子类对象
变形2:匿名内部类创建Runnable子类对象
变形3:lambda 表达式创建 Runnable 子类对象
拓展:多线程的优势
五.Thread类及其常见方法 常见的构造方法
常见属性
启动一个线程 中断一个线程
等待一个线程 获取当前现象的引用 休眠当前线程 一、什么是进程 每个应用程序运行于现代操作系统之上时,操作系统会提供一种抽象,好像系统上只有这个程序在运行,所有的硬件资源都被这个程序在使用。这种假象是通过抽象了一个进程的概念来完成的,进程可以说是计算机科学中最重要和最成功的概念之一。
进程是操作系统对一个正在运行的程序的一种抽象,换言之,可以把进程看做程序的一次运行过程;同时,在操作系统内部,进程是操作系统进行资源分配的基本单位。
二、进程的调度 1.描述一个进程 明确出一个进程上面的一些相关属性。就比如:形容一个学校的学生,你需要学校姓名,班级、专业等。
2.组织若干个进程 使用一些数据结构(例如链表),把很多描述进程的信息放在一起,方便进行增删改查。
较为典型的就是使用双向链表来把每个进程的PCB给串起来。因为操作系统的类型的不同,内部实现不尽相同。因此我们以 linux 系统为例进行讨论。linux组织进程的方式就是用双向链表来把每个进程的PCB给串起来。或者说,所谓的“创建进程”,就是先创建出 PCB,然后把 PCB 添加到双向链表中,所谓的“销毁进程”,就是找到链表上的某个PCB,将它从链表上移除。而“查看任务管理器”,就是遍历链表,找到我们想要的那一个PCB后,取出相关资料。
有了上述这些基础之后,我们就可以来聊一聊进程是怎么调度的了。 打开任务管理器,我们会发现我们的计算机上有许多任务在正在运行,那么我们的CPU又是如何管理运行他们的?
3.并发和并行 我们首先来明确两个概念:并发和并行
并发:微观上看,假设现在有ABCD四个任务,而我们的CPU并不是让这四个任务同时运行的,CPU先是运行一会A,再运行一会B再运行一会C.......那么循环运行的同时,CPU又在ABCD四个任务之间切换地非常快,那么我们从宏观的角度去看就好像是让ABCD四个任务在同时运行,这就是并发。
并发:单个核心 按照串行的方式 执行多个任务,但是只要它切换的足够快,从宏观来看就好像是多个任务在同时执行一样。
并行:现在有ABCD四个任务,我们的CPU让这四个任务同时运行,这就是并行。
并行:多个核心执行多个任务
从我们人的角度其实是区分不了并发和并行的,因此我们在写代码的时候也不去具体区分这两个词。我们平时常说的并发编程就是包含了 “并发” 和 “并行”的统称。
到这里我们就知道,所谓的进程调度就是让有限的CPU核数,去执行更多的任务。
4.进程的状态 1、就绪状态
2、阻塞状态 / 睡眠状态,暂时不去CPU 上调度执行
aarch64-linux-android-readelf -d *.so
该命令位于目录:Users/admin/Library/Android/sdk/ndk/21.3.6528147/toolchains/arm-linux-androideabi-4.9/prebuilt/darwin-x86_64/bin下,可以写到环境变量中
系列文章目录 这里写目录标题 系列文章目录前言一、计算机组成与体系结构1.数据表示2.体系结构3.层次化存储4.Cache5.校验码1.循环校验码(CRC)2.海明校验码(重点) 二、操作系统原理1.进程的状态2.前趋图3.进程同步与互斥4.PV操作5.死锁问题6.解决死锁-银行家算法7.分区存储组织8.页面置换算法9.位示图10.微内核操作系统 三、数据库系统1.关系代数2.范式3.并发控制4.数据备份5.数据仓库和数据挖掘 四、计算机网络1.DNS协议2.计算机网络的分类-拓扑结构3.网络规划与设计4.子网划分5.特殊含义的IP地址(选择题)6.HTML(出现在选择题)7.IPv68.信息系统安全属性9.网络安全-各个网络层次的安全保障 五、数据结构与算法基础1.数组存储地址计算2.稀疏矩阵3.线性表4.数与二叉树1.二叉树的各种性质2.二叉树遍历3.树转二叉树3.查找(排序)二叉树4.最优二叉树(哈夫曼树)5.构造哈夫曼树6.线索二叉树7.平衡二叉树 8.图1.图的存储-邻接矩阵2.图的存储-邻接表3.图-图的遍历4.图-拓扑排序5.图的最小生成树-普利姆算法5.图的最小生成树-克鲁斯卡尔算法 9.算法的特性10.算法的复杂度11.查找-顺序查找12.查找-二分查找13.排序1.直接插入排序2.希尔排序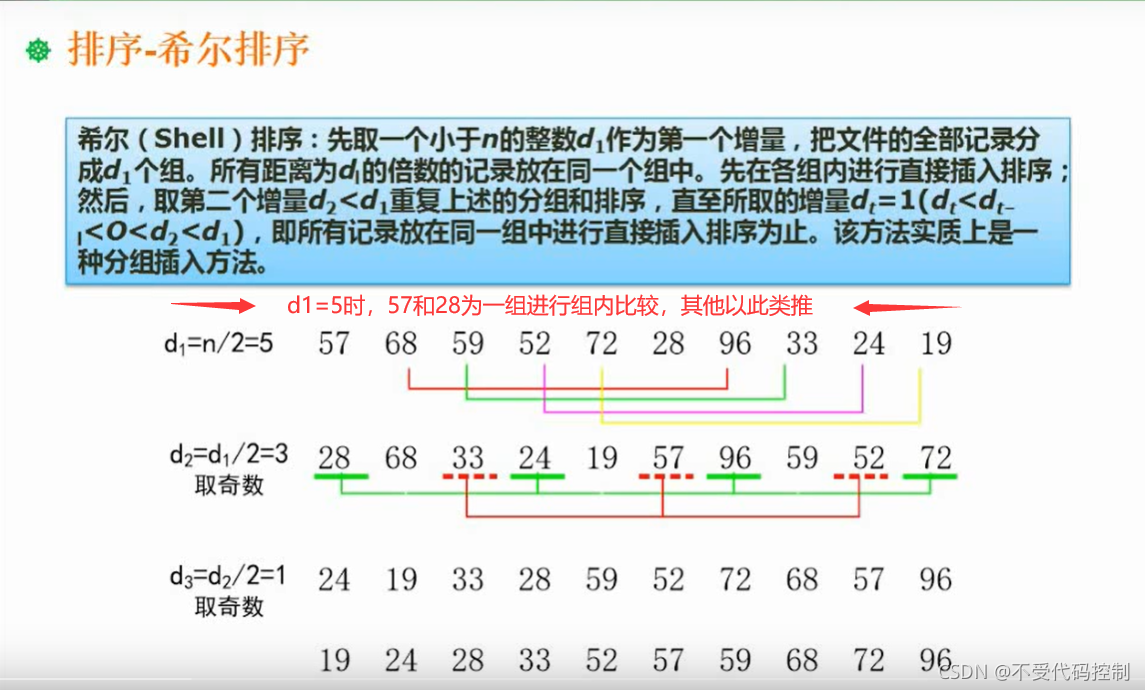3.直接选择排序4.堆排序5.冒泡排序6.归并排序7.快速排序8.基数排序 14.时间复杂度和空间复杂度 8.程序设计与语言处理程序1.文法**2.有限自动机与正规式1.有限自动机2.正规式3.例题 3.表达式4.传值传址 9.法律法规(3分左右)1.保护权限2.知识产权人确定3.侵权判定(重点)4.标准化基础知识-标准的编号 10.多媒体基础(1-3分)1.音频相关概念2.图像相关概念3.媒体的种类4.多媒体的相关计算1.例题 5.数据压缩 10.软件开发模型1.瀑布模型2.螺旋模型3.V型4.喷泉模型和RAD5.构建组装模型CBSD6.敏捷开发模型7.结构化设计8.软件测试9.Macabe复杂度(必考)9.CMMI10.项目管理 12.面向对象设计1.设计原则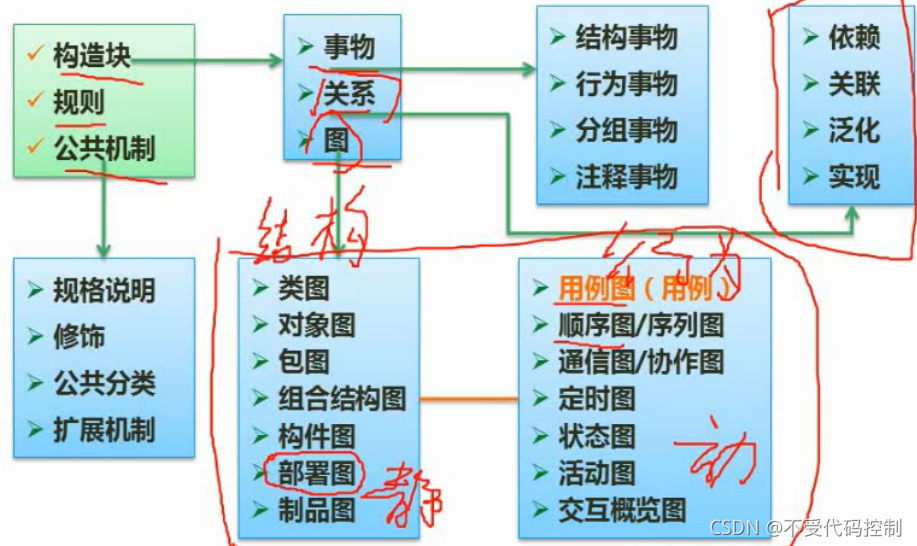2.UML3.设计模式的分类1.创建型模式2.结构型模式2.行为型模式 13.数据流图(重点,分值15分)1.数字字典2.数据流图平衡原则 14.数据库设计(15分)15.UML1.用例图2.类图3.顺序图4.活动图 16.数据结构与算法应用(下午题,较难)1.分治法2.回溯法3.贪心法4.动态规划法1.文法7.归并排序7.归并排序 13.排序9.位示图9.位示图9.位示图9.位示图 前言 一、计算机组成与体系结构 1.数据表示 R进制转化成十进制:例二进制10100.01=1x24+1x22+1x2^-2
十进制转化R进制:短除法求余,除数为R
二进制转八进制与十六进制:每三个二进制为一组计算八进制,每四个二进制为一组计算十进制
原码:-(2(n-1)-1)~2(n-1)-1
反码:-(2(n-1)-1)~2(n-1)-1
补码:-(2(n-1))~2(n-1)-1
正数:符号位为0;负数:符号位为1;
转换方法:原码->反码:符号位不变,其他为取反;
反码->补码:在反码基础上加1;
补码->移码:正负数都在移码符号位取反;
2.体系结构 (1)CISC(复杂)和RISC(精简)
考察方式:选择题
(2)流水线
流水线计算公式:1条指令执行时间+(指令条数-1)*流水线周期)
实践公式:(k+n-1)*△t k:指令分为几个部分(阶段) △t=流水线周期
图例:(3+100-1)*2=204
流水线吞吐率TP=指令条数/执行时间
流水线最大吞吐量TP(max)=1/△t
加速比=不使用流水线时间/使用流水线时间=500/203
效率E=n个任务占用的时空区/K个流水段总时空区=t/KT
3.层次化存储 速度:CPU>Cache>内存>外存
内存:CPU<Cache<内存<外存
4.Cache Cache+主存储器平均周期=hxt1+(1-h)xt2(h:cache访问命中率,t1:cache周期时间,t2:主存器周期时间,1-h:未命中率)
5.校验码 1.循环校验码(CRC) 只可验错不能纠正
余数为0为正确
2.海明校验码(重点) **利用多组数位的奇偶性来检错和纠错
List item **
(1)确认校验码位数:2^r>=k+r+1(k:信息数位数,r:校验码位数)
(2)确认校验码位置:2^n
(3)求出校验码:下面例图
(4)校验码纠正:按上面步骤重新计算校验码并与收到的校验码进行异或运算;
出现1的位置为校验码错误位;
二、操作系统原理 1.进程的状态 2.前趋图 3.
计算机二级C语言笔记 这里写目录标题 计算机二级C语言笔记一、公共基础题1.存储结构2.求结点数性质3.三种遍历方法4.笛卡尔积等运算5.范式6.关系数据模型7.时间复杂度和最坏情况比较次数8.数据库操作系统9.线性结构和非线性结构10.软件工程基础11.软件测试13.关系代数 二、程序基础设计三、C语言基础1.运算符与表达式2.基本语句3.选择结构4.数组5.函数6.指针6.编译预处理和动态存储分配7.结构体与公用体8.结构体传值、传参9.文件 总结 一、公共基础题 1.存储结构 (1)链式存储结构:一组不连续的存储单元存储表中的各个元素,各数据结点是可连续,也可不连续;链表通常有单链表,双链表,循环链表。
(2)树形存储结构: 所谓树形存储结构,就是数据元素与元素之间存在着一对多关系的数据结构。在树形存储结构中,树的根节点没有前驱结点,其余的每个节点有且只有一个前驱结点,除叶子结点没有后续节点外,其他节点的后续节点可以有一个或者多个。
(3)图型存储结构: 数据元素与元素之间的关系是任意的,任意两个元素之间均可相关,即每个节点可能有多个前驱结点和多个后继结点,因此图形结构的存储一般是采用链接的方式。图分为有向图和无向图两种结构,如下图
参考链接
2.求结点数性质 (1)叶子结点数:结点个数n,总结点数=n+各度的结 点数相加
(2)数的性质:数的结点数为树中所有结点的度数之和再加1
(3)二叉树性质:度为0的结点数总是比度为2的结点数多1
(4)二叉树基本性质:深度为k的二叉树,最多有2^k-1个结点
(5)完全二叉树:度为1的结点个数为0或1
(6)满二叉树:深度为k的二叉树,最多有2^k-1
个结点,第k层的结点数2^(k-1)
(7)完全二叉树:具有2n个结点的完全二叉树中,叶子节点数为n
3.三种遍历方法 (1)先(根)序遍历(根左右)
(2)中(根)序遍历(左根右)
(3)后(根)序遍历(左右根)
举个例子:
先(根)序遍历(根左右):A B D H E I C F J K G
中(根)序遍历(左根右) : D H B E I A J F K C G
后(根)序遍历(左右根) : H D I E B J K F G C A
4.笛卡尔积等运算 参考链接
5.范式 第一范式(1NF):主键不为空且不重复,字段不可再分
造成的精度丢失
在javascript中,带小数的数据运算时总会出现好多位小数.这是因为在javascript中浮点数的计算是以2进制计算的
/** * 加法运算,避免数据相加小数点后产生多位数和计算精度损失。 * * @param num1加数1 | num2加数2 */ function numAdd(num1, num2) { var baseNum, baseNum1, baseNum2; try { baseNum1 = num1.toString().split(".")[1].length; } catch (e) { baseNum1 = 0; } try { baseNum2 = num2.toString().split(".")[1].length; } catch (e) { baseNum2 = 0; } baseNum = Math.pow(10, Math.max(baseNum1, baseNum2)); return (num1 * baseNum + num2 * baseNum) / baseNum; }; /** * 加法运算,避免数据相减小数点后产生多位数和计算精度损失。 * * @param num1被减数 | num2减数 */ function numSub(num1, num2) { var baseNum, baseNum1, baseNum2; var precision;// 精度 try { baseNum1 = num1.
本教程重点介绍了一些常见场景下的SQL编写案例,通过优化前后性能对比或正确编写方法介绍,说明DolphinDB SQL脚本的使用技巧,案例共分四类:条件过滤相关案例、分布式表相关案例、分组计算相关案例及元编程相关案例,具体案例可在下方目录快速浏览。
目录
1 测试环境说明
2 条件过滤相关案例
2.1 where 条件子句使用 in 关键字
2.2 分组数据过滤
2.3 where 条件子句使用逗号或 and
2.3.1 过滤条件与序列无关
2.3.2 过滤条件与序列有关
3 分布式表相关案例
3.1 分区剪枝
3.2 GROUP BY并行查询
3.3 分组查询使用 map 关键字
4 分组计算相关案例
4.1 查询最新的 N 条记录
4.2 计算滑动 VWAP
4.3 计算累积 VWAP
4.4 计算 N 股 VWAP
4.5 分段统计股票价格变化率
4.6 计算不同连续区间的最值
4.7 不同聚合方式计算指标
4.8 计算股票收益波动率
4.9 计算股票组合的价值
4.10 根据成交量切分时间窗口
4.11 股票因子归整
4.12 根据交易额统计单子类型
5 元编程相关案例
5.1 动态生成 SQL 语句案例 1
写在前面:CSDN出现了很多需要知识付费的情况,有些东西你抄我我抄你,把别人免费开源的东西照搬拿过来后收费?我不能理解我想抵制这种行为,我想能做点自己能做的事情, 有些东西可以去官方找文档,__官网也有提供下载但就是有不少人要去下载不知道已经第几方来历不明的资源?Why?__知识产权是对的为知识收费没错,有些东西真的称得上知识!!!,但是拿人家免费开源的,然后搬到这里付费我不理解!滑稽…请大伙们多多注意吧,题外话就这么多了.
注意:没有用到数据库
使用链表完成此系统!
多文件实现
正式开始 --代码都可以直接使用 --不想看的,直接复制代码块里面的内容就行! 我用的visual studio 2019 有些使用了 _s 如果是用别的编译器,可以自行修改! 功能介绍 - 增,删,改,查,退出,保存,以至于格式化! - 1.录入学生信息 - 2.查看录入的学生信息(全部学生信息) - 3.修改已录入的学生信息(以学号) - 4.删除已录入的学生信息(以学号) - 5.保存信息到文件 - 6.指定查找(以学号) - 7.隐藏选项(格式化链表--清空) - 'q'退出系统 实现功能 创建源文件main.c 函数部分
//不一一介绍,不懂得去查就行,要学会Google! #include "myList.h" //引入自己写得一个头文件 //菜单界面 void menu(void);//函数声明,菜单显示函数. //按钮互动 void keydown(struct Node* List); int main(void) { struct Node* List = createrList();//创建一个叫List的链表 readInfoFromFile(List, "student.txt");//读取在student.txt的文件 然后写入List链表中 while (true) {//一直循环,知道用户不用这个程序后,输入'q' 退出程序! //显示菜单 menu(); //然后读取用户输入的值,进行操作! keydown(List); system("pause");//暂停程序用的 system("cls");//执行完一次,就清屏一次,看起来比较舒服 } system("
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width,initial-scale=1,maximum-scale=1"> <title>h5实现一键复制到粘贴板 兼容ios</title> </head> <body> <h3>h5实现一键复制到粘贴板 兼容ios</h3> <button onclick="copyText('h5实现一键复制到粘贴板 兼容ios')">copy</button> <script> const copyText = (text) => { // 数字没有 .length 不能执行selectText 需要转化成字符串 const textString = text.toString(); let input = document.querySelector('#copy-input'); if (!input) { input = document.createElement('input'); input.id = "copy-input"; input.readOnly = "readOnly"; // 防止ios聚焦触发键盘事件 input.style.position = "absolute"; input.style.left = "-1000px"; input.style.zIndex = "-1000"; document.body.appendChild(input) } input.value = textString; // ios必须先选中文字且不支持 input.
问题:214748364.00 + 7.00*0.10 = 214748364.69999999
atof(214748364.7) 转出来也是214748364.69999999
解决办法:
分析:
double + double 就会有这个问题
int + double 就没有
前言 一个微服务模块在运行一段时间之后,整体服务就不可用了,但是服务却没有打印任何错误日志。而对服务进行重启之后,服务就可以暂时提供一段时间服务,过一段时间之后再次不可用。
分析 服务进行重启就可以正常提供功能,说明是某些资源没有释放。接下来需要确定的是什么资源被占用不能够释放就可以定位到问题并解决了。
处理过程 1、首先查看服务器的磁盘、cpu占用情况,发现还有很大空闲,因此不是服务器资源不够用的问题;
2、检查JVM的GC情况,我这里是在对服务重启的命令上添加了远程链接的参数,hostname是服务器的ip,port是向外暴露的一个端口号。然后就可以在本地使用jvisualvm对服务器上的JVM运行情况进行检测了。
-Djava.rmi.server.hostname=ip -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false 检测过程中,发现GC情况是正常的,在服务即将不可用之前,也没有出现频繁GC或者内存过高甚至内存溢出的问题。
3、由于短时间之内没有发现问题,且不知道服务什么时候就会失效,只好写了一个定时脚本,检测服务是否可用,不可用时将此刻的内存快照保存下来,以下是检测服务、下载内存快照、重启服务的脚本。
serverurl=http://ip:port/actuator/health urlstatus=$(curl -s -m 5 -IL $serverurl|grep 200) if [ "$urlstatus" == "" ];then echo "eis服务不可用" ID=`ps -ef | grep eis | grep -v "$0" | grep -v "grep" | awk '{print $2}'` echo $ID /home/tkbo/JDK/jdk1.8.0_301/bin/jmap -dump:format=b,file=/home/tkbo/menhuJar/serviceDump.dat $ID kill -9 $ID echo "已终止eis服务" nohup /home/tkbo/JDK/jdk1.8.0_301/bin/java -Djava.rmi.server.hostname=ip -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -jar /home/tkbo/menhuJar/ace-eis-manager.jar --eureka.instance.ip-address=ip --eureka.client.serviceUrl.defaultZone=http://ip:8761/eureka/,http://ip:8761/eureka/ --spring.profiles.active=ergo > /home/tkbo/menhuJar/ace-eis-manager.
1.具有隐藏的作用
当同时编译多个文件时,所有未加static前缀的全局变量和函数都具有全局可见性。
a.c:
char a = 'A'; // global variable void msg() { printf("Hello\n"); } main.c
int main( void) { extern char a; // extern variable must be declared before use printf("%c ", a); ( void)msg(); return 0; } 程序的运行结果是:
A Hello
你可能会问:为什么在a.c中定义的全局变量a和函数msg能在main.c中使用?前面说过,所有未加static前缀的全局变量和函数都具有全局可见性,其它的源文件也能访问。此例中,a是全局变量,msg是函数,并且都没有加static前缀,因此对于另外的源文件main.c是可见的。
如果加了static,就会对其它源文件隐藏。例如在a和msg的定义前加上static,main.c就看不到它们了。利用这一特性可以在不同的文件中定义同名函数和同名变量,而不必担心命名冲突。Static可以用作函数和变量的前缀,对于函数来讲,static的作用仅限于隐藏,而对于变量,static还有下面两个作用。
2.保持变量内容的持久
变量不加 static 修饰:
#include <stdio.h> void test() { int num = 0; num++; printf("%d ", num); } int main() { int i = 0; for (i = 0; i < 10; i++) { test(); } return 0; } 输出:1 1 1 1 1 1 1 1 1 1 1
简介 哈希表(hash table)也叫作散列表,作为数据结构的一种,它的优点在于无论是插入操作还是查找操作,它的时间复杂度是o(1),正是因为这个优点,在海量数据处理的场景都会有它的身影.
这其中的Hash也就是hash值,主要用于信息安全领域的加密算法,它把一些值转换为杂乱的128编码,这些编码值就叫做Hash值,换个方向去看这个Hash值,Hash就是一种数据与数据地址之间的映射关系.
对java源代码有一定的理解的同学,HashSet的底层代码原理是HashMap,而HashMap的底层原理就主要就是HashCode了。在HashMap的底层代码里的第一段注释:
/*
* Implementation notes.
*
* This map usually acts as a binned (bucketed) hash table, but
* when bins get too large, they are transformed into bins of
* TreeNodes, each structured similarly to those in
* java.util.TreeMap. Most methods try to use normal bins, but
* relay to TreeNode methods when applicable (simply by checking
* instanceof a node). Bins of TreeNodes may be traversed and
前言 使用mock可以让前端不在局限于后端接口,在规定好文档格式后甚至能一次性开发完整个前端接口,大大节省了对接时间,可以说是当前前端必备的技能之一了。最近做新项目,重新搭建了下框架,想着写一篇mock的配置文章,让大家共同进步。
一、npm下载插件
npm install mockjs --save-dev 二、创建mock文件夹 1.在跟目录(src目录同级)下创建mock文件夹 2.mock文件夹下新建index.js文件 import Mock from 'mockjs' import { param2Obj } from '../src/utils' import user from './user' const mocks = [ ...user ] // for front mock // please use it cautiously, it will redefine XMLHttpRequest, // which will cause many of your third-party libraries to be invalidated(like progress event). export function mockXHR() { // mock patch // https://github.com/nuysoft/Mock/issues/300 Mock.XHR.prototype.proxy_send = Mock.XHR.prototype.send Mock.
1.什么是null
MySQL 中 null 不代表任务实际的值,类似于一个未知数。
2.执行对比
2.1 查询条件为 =null
执行之后,发现返回行数为0
2.2 查询条件为 is null
执行后发现返回行数为8
2.3两次查询的为何不同
null 在MySQL中不代表任何值,通过运算符是得不到任何结果的,因此只能用 is null(默认情况)
2.4使用 =null的解决方式
因为在非ANSI SQL标准中,data=null等同于data is null,data<>null等同于data is not null,所以使用 =null 可以进行以下设置:
set ANSI_NULLS OFF; 如果 set ANSI_NULLS为 ON 时,表示SQL语句遵循SQL-92标准;如果 set ANSI_NULLS 为 OFF 时,表示不遵从 SQL-92 标准。
但SQL-92 标准要求对null的 = 或不等于 (!= ,<>) 比较取值都为 false,也就是 =null 或者 <>null,返回的都是false。
随着消费者对照明光效、个性化照明、智能化照明、健康节能环保等要求的提升,智能照明作为行之有效的解决方案,无疑是行业发展的必然趋势。
智能照明作为照明行业未来的发展方向,已成为行业共识。对于智能家居、智能楼宇(商业照明)、智能园区与城市而言,各种灯具是重要的智能节点。
在与灯具的组合方面,雷达感应技术相对于红外感应技术显示出无可比拟的优势。智能照明发展将逐渐向智能化、标准化、绿色化和人性化的方向转变,促进智能产业发展。
飞睿智能专注于通过雷达和物联网技术,通过智能感应人体存在,使产品智能化响应操作。
情景联动,进门自动开灯,出门关灯;有节能的需求,如人来灯亮,人走灯灭;有提升用户对光的体验需求,如根据环境光的照度自动调节,如根据人体移动探测、微动探测、呼吸探测人的存在,实现家居空间的照明调节。
利用物联网和感应技术融入照明灯具的应用,丰富了情景联动方式,满足不同人群、不同时间对照明控制的需求。
产品涵盖应用于各类智能感应人体存在的雷达模块。满足了商业及工业照明的智能化、节能化需求。
通用型雷达模块,解决了如面板灯、线条灯、吸顶灯、球泡灯、消毒灯等的应用。低功耗型雷达模块,解决了以往雷达产品不能使用在电池供电的低功耗产品上的痛点,比如充电型小夜灯,充电型衣柜灯等。
组网型雷达模块,如雷达模块+WIFI等,满足了客户端的需求。微波雷达感应器可以给用户带去极佳的智能产品体验,提升智能技术于照明产品的应用,为终端用户提供更优质的智能照明体验。
微波雷达模组智能感知人体存在操控应用,是以节能环保和智能感应为出发点。微波雷达模组配合智能照明系统,达到人工智能响应开启,人走主动封闭,实现智能化人体感应控制应用。
数字化、智能化、健康化等关键技术,是照明行业跨界创新,践行“以人为本”发展理念的主要方向。智能家居照明产品和技术的应用,促进照明行业在物联网领域的延伸发展。
目前,智能照明打开了行业长期成长的空间,其发展前景远大于传统照明,同时也促进了照明电器行业的健康发展。
文章目录 回顾 React单向数据流函数式组件 useState 使用state 两者区别function state 和 class state快照(闭包) vs 最新值(引用) 回顾 React 单向数据流 和angular双向绑定不同,React采用自上而下单向数据流的方式,管理自身的数据与状态。
在单向数据流中,数据只能由父组件触发,向下传递到子组件。
我们可以在父组件中定义state,并通过props的方式传递到子组件。
如果子组件想要修改父组件传递而来的状态,则只能给父组件发送消息,由父组件改变,再重新传递给子组件。
在React中,state与props的改变,都会引发组件重新渲染。
如果是父组件的变化,则父组件下所有子组件都会重新渲染。
在class组件中,组件重新渲染,是执行render方法。
而在函数式组件中,是整个函数重新执行
函数式组件 函数式组件与普通的函数几乎完全一样。
只不过函数执行完毕时,返回的是一个JSX结构。
function Hello() { return <div>hello world.</div> } 函数式组件非常简单,也正因如此,一些特性常常被忽略,而这些特性,是掌握React Hooks的关键。
函数式组件接收props作为自己的参数 import React from 'react'; interface Props { name: string, age: number } function Demo({ name, age }: Props) { return [ <div>name: {name}</div>, <div>age: {age}</div> ] } export default Demo; props的每次变动,组件都会重新渲染一次,函数重新执行
没有this。那么也就意味着,之前在class中由于this带来的困扰就自然消失了
useState 使用 useState Hook 让函数组件也可以有 state 状态,并进行读写操作语法: const [state, setState] = React.
## 0X01 GBK编码查询
GBK编码与汉字之间的转换。
查看字符编码(简体中文)http://www.mytju.com/classcode/tools/encode_gb2312.asp
## 0X02
厘清一些概念 什么是分支? 对于日常开发而言,我们说分支的时候,脑海里是根节点到某叶子节点的一条路径,是那条线。实际上git里面并没有“线”的概念,或者说,从来没有说去操作一条线。
个人理解:分支是一个指针,指向某个节点的一个指针。这里说的节点就是每一次提交记录。
分支不是路径,只是简单地指向某个提交纪录。
基本操作 创建分支 使用git branch <分支名>创建一个分支,上文说过分支是一个指向某节点的指针,那么这句指令执行之后,新建的分支指向的是哪个节点呢?
创建前
创建后(git branch newB)
显然,新分支指向的提交记录和创建时“我”所在的分支一致。*号表示当前所在分支是master而不是newB 切换分支 分支是可以移动、变更的,但是在进行这些操作前,先要切换到该分支上。
git checkout <分支名>
分支的移动 最常见的移动分支操作就是git commit,执行这个指令,当前分支就会移动到新增的一个提交记录上。
虽然分支只是一个节点的指向,但平常看来就像是从根节点到任意一个节点的路径一样,这就是因为如果只是用git commit来移动,那么每个分支走过的路径都是独一无二的。
master和newB都在C1节点的时候进行了一次提交,各自产生并指向了一份记录,节点分别为C2、C3
分支的合并 merge git merge <目标分支名> --目标分支将要合并到当前分支
把 bugFix 合并到 master 里,首先要处于master分支上,然后合并指令git merge bugFix
可以再把 master 分支合并到 bugFix:
git checkout bugFix;git merge master
这里可以看到和上一步是没变化的,这是因为上一步 bugFix 已经合并到 master 里了,这时候的master指向C4节点,C4是C2和C3的子节点,意味着master是在bugFix基础上的变动,是bugFix子分支,已经包含/覆盖了父分支bugFix。
把子分支合并到父分支上,实际上只是简单地将父分支移动到子分支指向的节点了而已。
rebase git rebase <目标分支名> --把当前分支的工作移动到目标分支后面,移动之后看起来是按顺序开发的一条分支
git rebase master之后:
提交树上自由移动 什么是head? 前文说道分支本质就是一个指针,指向提交记录,这里的head也一样,8指向提交记录或者分支,标记的是“我”的位置。
head指向分支的时候,该分支就是当前分支,head跟随分支移动而移动,
但head是可以在提交记录上自由移动的,不一定要跟随分支。
HEAD分离 当我们git checkout 某分支 的时候,实际上是HEAD指针指向了那个分支,这样看起来好像HEAD总是和某个分支粘在一起,可以git checkout 某提交来分开head和某分支:
DB-Engines最新发布的2022年3月时序数据库排名榜单中,国产时序数据库DolphinDB继2月荣登该榜单前10后,又前进至第9名,也是目前唯一排名前10的国产时序数据库。自2019年参与DB-Engines排名以来,DolphinDB凭借广大用户的支持与产品优异的性能,排名一路飙升。
近几年,时序数据库(time-series database)一直是数据库的热点。在DB-Engines最近24个月的流行度报告中,时序数据库力压其他类别的数据库,是增长趋势最快的数据库类别。尽管与关系型数据库相比,时序数据库还很年轻,但关于海量时序数据的新的解决方案、项目和基础工具正在蓬勃发展。
时序数据无处不在 如今时序数据的应用场景十分广泛,许多类型的数据都是时间序列数据:
l 金融市场交易
l 传感器测量(水冷、高温、地震...)
l 服务器监控(CPU、内存、磁盘...)
l 资源消耗(能源、电力...)
l 人体健康(心率、血氧浓度...)
l 网络访问
通过保留数据固有的时间序列性质,我们可以记录下事物是如何随时间变化的事实,正因如此,这一反应真实的客观属性使得时序数据在特定的场景中充满了商业价值:通过分析时序数据,决策者可以了解到生产和业务中的细微变化,从而对资源优化、跟踪、预测、商业智能等方面进行优化。
当然,想要记录并分析时序数据也带来一个明显的问题: 由于时序数据产生的速度非常快,且规模庞大,如何以一种高性能的方式记录、查询和分析如此大规模的数据,成为了一个难题。时序数据库(time-series database)应运而生。
掌握过去、了解现在和预测未来 在时序数据库成为热点之前,时序数据通常使用MySQL或PostgreSQL等关系数据库进行处理。但自2010年以来,随着互联网和通信技术的发展,网络中产生的时间序列数据量有了爆炸式的增长,传统的数据库已经无法处理这种万亿级的海量数据。不仅如此,现代业务对数据价值挖掘的需求已不仅仅停留在简单计算和绘制图表的层面上,而是需要更多精细、复杂的计算分析。以对数据价值嗅觉最敏感的金融领域为例,早在20年前,华尔街就已经开始使用时序数据库对股票交易数据进行实时的计算分析。
高压缩比,高写入吞吐量,以及高速的时间序列查询,是时序数据库相比于关系数据库在处理海量时序数据方面的最基本的能力和优势。DolphinDB支持每秒百万级以上(随集群规模增大而增大)的数据写入,万亿级数据毫秒级查询以及秒级的计算响应。
真正让DolphinDB脱颖而出的,是DolphinDB强大的实时数据处理能力和历史数据分析能力。DolphinDB内置了高效的流数据系统和1000+计算函数。在同一个系统内实现了海量历史数据和实时流数据的便捷存储、查询、分析仿真和可视化。同时流批一体的产品设计,让用户可以在极短时间内将研发成果部署到生产环境,极大提高工作效率,提升企业的竞争优势。
DolphinDB的付费客户遍及中国大陆及港台地区、欧洲、美国、澳大利亚等地,客户领域包括金融、能源、智能制造、电信、化工、水务、营销分析、智慧城市等。DolphinDB让企业从海量数据中高效发掘数据尤其是实时数据的价值,以实时反控业务系统,助力企业和用户实时商业决策,真正做到掌握过去、了解现在和预测未来。
标签定义图形,比如图表和其他图像,您必须使用脚本来绘制图形。
在画布上(Canvas)画一个红色矩形,渐变矩形,彩色矩形,和一些彩色的文字。
HTML5 元素用于图形的绘制,通过脚本 (通常是JavaScript)来完成.
标签只是图形容器,您必须使用脚本来绘制图形。
实现画笔颜色切换画笔粗细调整清除图像绘制矩形绘制圆形 创建一个画布(Canvas) <canvas id="canvas" width="900" height=500" style="border: 2px #550000 solid;"> 画板代码 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>绘制画板</title> </head> <body> <div class=""> <input type="color" value="#ff5821" id="color"/> <input type="range" class="range" min="1" max="20" value="1" id="cu"> <button type="button" id="cls">清除图像</button> <button type="button" id="rectangle">绘制矩形</button> <button type="button" id="round">绘制圆</button> </div> <canvas id="canvas" width="900" height=500" style="border: 2px #550000 solid;"> </canvas> <script type="text/javascript"> // 颜色 let color = document.querySelector("#color"); // 清除 let cls = document.
全局安装脚手架
npm install -g @vue/cli
PS D:\www\vue> vue.cmd --version
@vue/cli 5.0.3
创建项目
PS D:\www\vue> vue.cmd create vueproject01
Vue CLI v5.0.3 ? Please pick a preset: Default ([Vue 3] babel, eslint) Default ([Vue 2] babel, eslint) > Manually select features Vue CLI v5.0.3 ? Please pick a preset: Manually select features ? Check the features needed for your project: (Press <space> to select, <a> to toggle all, <i> to invert selection, and <enter> to proceed) (*) Babel ( ) TypeScript ( ) Progressive Web App (PWA) Support (*) Router (*) Vuex (*) CSS Pre-processors >( ) Linter / Formatter ( ) Unit Testing ( ) E2E Testing Vue CLI v5.
头像上传主要的难点在于后端的操作。接下来我会从最开始一步步实现。
我用的是vant组件 其实感觉移动端的话vant组件还是非常好用的Vant 2 - Mobile UI Components built on Vue
这里使用的是Vant 2的Uploader 文件上传
首先在页面中使用该组件
<template> <div> <van-uploader :after-read="afterRead" /> </div> </template> <script> export default { methods: { afterRead(file) { // 此时可以自行将文件上传至服务器 console.log(file); }, }, }; </script> <style lang="scss" scoped> </style> 当我们随便上传一张图片之后就会出来一个file对象
这样就能获取到图片的一些信息 比如:图片大小 图片格式 ........
回到页面开始写发送请求 这里注意要写一个name字段
<template> <div> <van-uploader name='uploadFile' :after-read="afterRead" /> </div> </template> <script> export default { methods: { afterRead(file) { // 此时可以自行将文件上传至服务器 console.log(file); // 创建一个新的FromData const fd = new FormData() // 这一步是把刚才获取到的图片信息 添加到fd里面 fd.
和ubuntu、win10双系统打了一晚上的交道,怕以后还会用到,于是做个记录。
首先是卸载,卸载分两步,一步是删除或者格式化原来安装时分的区,其中除了EFI分区外都可以在磁盘管理处直接删除,而EFI分区可以使用一些软件删除,比如diskgenius。
第二步是删除启动项。如果是第一次卸载ubuntu可以使用easyUEFI,很直观地删除,教程为Win10 + Ubuntu双系统,删除Ubuntu系统 - 寻觅beyond - 博客园。但是它有试用期,如果之前用过八成现在就已经过了试用期了。除这种方法外还可以用windows自带的diskpart来删除,教程为在win10+Ubuntu双系统下,完美卸载Ubuntu_guikunchen的博客-CSDN博客_卸载ubuntu
然后是安装,安装主要可以参考链接
windows10安装ubuntu双系统教程(绝对史上最详细) - 不妨不妨,来日方长 - 博客园
Ubuntu系统安装分区_sealee01的博客-CSDN博客_ubuntu安装分区
其中第一个链接时介绍全过程比较好的,第二个链接的磁盘分区讲的比较详细。
注意,第一个链接里有提到安装之前什么在win下分好区,他的意思是留足空间的意思,并不是要我们真正去划分一个区,要保证这些空间为未分配状态。
其次,第一个链接里说空间留100G左右就行了,而第二个链接则留了500G,说要留大一些,建议空间够的情况下还是留足一些比较好。
附注:我的是神舟电脑,bios进入快捷键是f2
1、Date类
最早使用的时间类
Date是从1900年1月1日0时0分0秒开始的,因此在创建Date类时需注意,
有参构造的:
new Date(int year, int month, int day);
这个year需要传年减去1900的值,比如你想要2022年那么你需要传个122
这个month是从0开始的,0-11表示1到12月,因此如果你想要3月你需要传个2
所以相对的
从一个Date内获取年份,需要加上1900 也就是说date.getYear()返回的也会是122,这个122对应的就是2022年
从一个Date内获取月份,需要加上1也就是说date.getMonth()返回的也会是2,这个2对应的就是3月
还有一个特殊的就是获取日期的星期数
getDay() 返回的是 0代表周日,其他1-6代表周一到周六
2、simpleDateFormat
simpleDateFormat是用于格式化日期的一个类,通常用于Date的格式转化。
为什么需要格式化日期的类,
由于世界上的日期表现形式有很多种,不同地方用不同的格式但是对应的含义又是一样的,那么两个不同地区的人怎么能让对方明白这个日期的具体数值呢?这里就需要格式化类了,其实也就是相当于一个翻译器的功能。
Date NowDate = new Date(); SimpleDateFormat formatter =new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); SimpleDateFormat formatter =new SimpleDateFormat("yyyy/MM/dd HH:mm:ss"); String CurrentTime = formatter.format(NowDate); 使用不同的调用就会有不同的结果出现,只要知道规则就能找到对应的日期了。
3、Calendar
由于Date在很多情况下使用都比较不友好,比如我要指定年份还需要计算一下才能知道参数,再一个Date类没办法进行加减操作,很多时候我们需要拿到去年,或者两个月前的日期,这种就不好用Date类了,因此,诞生了Calendar类
Calendar 是一个抽象类,所以不能直接调用构造出来。
Calendar c1 = Calendar.getInstance(); 可以直接使用类里的静态方法得到一个实例化对象。
我们可以直接调用c1.set(2022, 4- 1, 29);来设置日期 这里需要注意月份还是和Date类一样设置都是从0开始的
另一个注意点是这里星期的规则和原本就不一样了。
由于国外都是算周日是一个星期的开始,因此这里使用1代表星期日,2代表星期一依次类推。
还有个比较好的方法就是它的add方法,可以对日期,月份,年份进行加减。
4、LocalDate、LocalTime和LocalDateTime
为什么需要这三个类?
对于Date来说Date是一个时间点,那么日期和时间就被一个Date掌控了,这不符合单一职责原则,此外,由于地球很多地方处于不同时区,那么地球上同一时间却有了不同的时间表示,因此诞生了LocalDate类来处理日期,LocalTime来处理时间,以及LocalDateTime类来处理对应的日期+时间,这里是可以传入时区参数来获取不同时区的时间的,这对于一些国际化项目来说是十分重要的,当然这三个类还是线程安全的类,这一点在多线程运行环境下也十分重要。
这些类的使用方式?
//获取当前时区的日期
LocalDate localDate = LocalDate.
纵有千古、横有八方 目录
一、⏱️本章重点
二、⏱️队列实现栈
三、⏱️栈实现队列
四、⏱️解题思路总结
一、⏱️本章重点 用两个队列实现栈用两个栈实现队列解题思路总结 二、⏱️队列实现栈 我们有两个队列:
入栈数据1、 2、 3
可以将数据入队列至队列一或者队列二。
如何出栈?
但出栈要先出1,怎么办?
第一步:
将队列一出队n-1个至队列二。
第二步:
pop队列一的最后一个元素。
接下来怎么入栈呢?
将元素入队至不为空的队列。
怎么判断栈空?
队列一和队列二都为空的情况下,栈就是空的。
如何取栈顶元素?
取不为空的队列尾部元素。
总的来说就是,入栈时就将数据插入不为空的队列,出栈就将不为空的队列的前n-1个数据导入至另一个队列,然后pop最后一个元素。
代码实现:
首先我们要构造一个栈。
这个栈要包含两个队列
typedef struct { Queue q1; Queue q2; } MyStack; 在此之前我们要准备好队列的一般接口:
我这里的队列是用单链表来构建的,具体接口实现可以看我之前的文章。
typedef int QTypeData; typedef struct QueueNode { struct QueueNode* next; QTypeData val; }QN; void QueueInit(Queue* pq)//初始化队列 size_t QueueSize(Queue* pq)//求队列元素个数 int QueueBack(Queue* pq)//取队列尾部数据 void QueuePush(Queue* pq, QTypeData x)//将x入队 void QueuePop(Queue* pq)//出队 void QueueDestroy(Queue* pq)//结束队列 我们要用队列实现栈的接口:
1. 安装 babel-plugin-component
npm install babel-plugin-component -D 2. 在项目目录下创建 elementUi / index.js 目录及文件
elementUi / index.js
// 里面的这些 MessageBox Dropdown 都是 element 组件库标签的驼峰写法 import { MessageBox, Message, Dropdown, DropdownMenu, DropdownItem } from 'element-ui'; const element = { install: function (Vue) { Vue.use(Dropdown); Vue.use(DropdownMenu); Vue.use(DropdownItem); // 下面是注册 element 的 动态组件重命名 到 原型中 Vue.prototype.$msgbox = MessageBox; Vue.prototype.$alert = MessageBox.alert; Vue.prototype.$confirm = MessageBox.confirm; Vue.prototype.$message = Message; }, }; export default element; 3. 在 main.
环境: 服务器主机 :腾讯云 1核 1GB 1Mbps
服务器操作系统:CentOS 7.2 64位
可能用到的软件:
Proxifier : 用来测试连接情况
Firefox : 就是浏览器…任何一个都可以
ssh登录出现问题 使用ssh-keygen -R 服务器ip地址 更新我们的认证信息
ssh-keygen -R 156.232.7.132 关于SOCKS5 这里只做简单介绍。
SOCKS5 是一个代理协议,它在使用TCP/IP协议通讯的前端机器和服务器机器之间扮演一个中介角色,使得内部网中的前端机器变得能够访问Internet网中的服务器,或者使通讯更加安全。
正常情况下客户端和服务端的通信:
客户端<–>服务端
使用了SOCKS5代理后的通讯:
客户端<–>代理服务器<–>服务端
我接触这个是因为,我的客户端没有办法直接访问一部分服务端(被墙了),但是我可以访问代理服务器,而且代理服务器可以访问我需要的服务端。
所以我尝试通过代理服务器来访问需要的服务端(翻墙)。
本文适用于CentOS 7.2 64位操作系统。
通过yum安装ss5 依赖包:
yum install gcc openldap-devel pam-devel openssl-devel 安装成功之后,安装ss5:
# 这个是一个日本大学的sourceforge镜像 wget http://jaist.dl.sourceforge.net/project/ss5/ss5/3.8.9-8/ss5-3.8.9-8.tar.gz 然后解压压缩包:
# 解压,"ss5-3.8.9-8.tar.gz"是刚才下载的压缩包 # -v过程显示文件 -z解压/压缩gzip -x解压操作 -f 后面加要操作的文件 tar -vzx -f ss5-3.8.9-8.tar.gz 会解压出来很多文件,进入解压目录:
cd ss5-3.8.9/ 运行’./configure’
# configure是一个shell脚本 # 主要的作用是对即将安装的程序进行配置, # 检查当前的环境是否满足要安装程序的依赖关系.