方法一 (推荐) 使用apache提供的工具类
import org.apache.commons.lang3.time.StopWatch; public class Test { public static void main(String[] args) { //初始化 StopWatch stopWatch = new StopWatch(); //开始时间统计 stopWatch.start(); method(); //结束时间统计 stopWatch.stop(); //运行时间ns System.out.println(stopWatch.getNanoTime()); //运行时间ms System.out.println(stopWatch.getTime()); } private static void method() { for (int i = 0; i < 1000000; i++) { Math.sqrt(1.44); } } } 方法二 这个是最原始的方法,来统计代码的运行时长了。
public class tmpTest { public static void main(String[] args) { //开始时间 long stime = System.currentTimeMillis(); Math.sqrt(1.44); //结束时间 long etime = System.
2020.8最新版本为TF2.3,安装时容易出现的问题是各软件程序版本不统一的问题,GPU版本对应表如下图所示,图片来源于Tensorflow 官网。
//--------------------------------------------------分割线------------------------------------------------------------------------
//--------------------------------------------------分割线------------------------------------------------------------------------
//--------------------------------------------------分割线------------------------------------------------------------------------
首先, 在命令窗口中查看自己的python版本
python --version 如出现python3.7.0(3.5以上版本均有可能出现这个问题),python版本过高导致TensorFlow不能正确安装。此时需要安装低版本的python,如python3.5
conda install python=3.5 报错:
PackagesNotFoundError: The following packages are not available from current channels: - pythons3.5 在等待安装完成后,重新查看自己的python版本,如显示python3.5.x,再进行TensorFlow的后续安装
参考链接 [1] keras|遇到no module name keras/keras.models/keras.layers/…怎么办? 2018.8
[2] Windows安装TensorFlow方法,及错误解决方案 2018.12
什么是fiddler fiddler是一个强大好用的http抓包工具,它通过代理服务器的方式将http客户端(可以是浏览器,可以是安卓APP,或者苹果APP)的请求进行拦截处理,只要能够拦截到http请求,那么fiddler就可以做请求和响应报文打印、请求断点调试、等功能,更高级的用法可以通过自己编写脚本实现自动化测试平台能力,事实上fiddler功能上我们用的最多的其实还是它的抓包,通过抓包来分析和定位前后端对接和联调问题。
下载安装fiddler 1、直接从本人的阿里云盘下载免费的fiddler安装包(新手推荐方式):
https://www.aliyundrive.com/s/HKvdb2DBq42
2、从fiddler官网下载免费的fiddler安装包(大牛推荐方式):
fiddler官方地址:https://www.telerik.com/
从官网可以看出,fiddler已经发展为平台级解决方案,并且改名为:“Fiddler Everywhere”,同时也嗅到了商业味道,fiddler平台级解决方案属于商业化需要收费,““Fiddler Everywhere”相比旧版fiddler功能更加强大,但是这里我们不过多介绍它,好在的是fiddler老的版本目前仍然是免费的,现在就跟大家说说怎么在官网找到免费的老版本fiddler,并下载使用。
1、访问上方官网地址进入官网后,点击导航栏的All Products(所有产品)。
2、继续点击VIEW ALL PRODUCTS(查看所有产品):
3、进入后点击Free tools(免费工具)
4、点击Fiddler Classic:
5、接下来就自己下载fiddler的需求填下表单,然后点击Download For Windows(免费的fiddler只支持windows版本的),等待下载完成即可。
6、双击FiddlerSetup.exe,点击I Agree:
7、选择安装目录,继续点击Install:
8、安装完成,点击Close关闭对话框即可:
fiddler浏览器抓包 接下来带大家操作下如何使用fiddler抓取浏览器的http请求包。
1、双击安装目录下的fiddler.exe(也可以发送到桌面)。
2、勾选Capture Traffic,表示开启抓包,再次点击表示关闭抓包,fiddler默认启动的代理服务器地址是127.0.0.1:8888。
3、打开浏览器,随便访问某个网站即可抓包,例如我们访问CSDN网站:https://www.csdn.net/,可以看到抓包列表抓取所有访问CSDN的包:
4、可以通过点击X图标,点击Remove all清空列表:
fiddler抓包原理 当勾选Capture Traffic后,fiddler会修改浏览器代理状态为开启,如果你用的谷歌浏览器,可以进入浏览器的(设置->高级->系统->打开您计算机的代理设置)这个路径,或者直接访问:chrome://settings/system,然后分别点击两次Capture Traffic,每点击一次就进去该路径下观察开关会自动被打开和自动被关闭。打开后代理url设置的正是fiddler默认的代理地址:127.0.0.1:8888,这就是fiddler通过代理服务器实现抓包的核心原理。
fiddler导出抓包报文 右键某一行请求,点击Save(保存)-> Selected Session -> as Text即可将某个请求HTTP完整报文通过txt文件保存到电脑本地进行问题定位和分析。
fiddler查看抓包报文 点击右边区域的Inspectors,可以在工具里面查看请求报文信息:
fiddler抓取指定的请求 1、可以通过点击Rules,隐藏一些不重要的请求,例如图片请求,HTT握手连接请求,304读取浏览器本地缓存请求。
3、fiddler过滤只抓取指定ip的请求:
如上方式,还可以指定fiddler过滤隐藏指定ip的请求。
4、fiddler过滤符合某个正则表达式的请求:
fiddler断点调试功能 点击Rules -> Automatic Breakpoints -> Before Requests:
fiddler断点调试最重要的就是可以修改请求相关的报文参数,或请求头信息,具体修改方式如下:
fiddler安卓APP抓包 1、要求手机能够访问到fiddler所在的电脑的ip,一般做法就是让手机和电脑连接同一个网络。
2、点击fiddler的File -> Capture Traffic,开启fiddler的抓包代理功能。
3、点击Tools -> Options,点击HTTPS,勾选Capture HTTPS CONNESTs和Decrypt HTTPS traffic:
本文将会介绍 Elasticsearch 向量搜索的两种方式。
向量搜索 提到向量搜索,我想你一定想知道:
向量搜索是什么?
向量搜索的应用场景有哪些?
向量搜索与全文搜索有何不同?
ES 的全文搜索简而言之就是将文本进行分词,然后基于词通过 BM25 算法计算相关性得分,从而找到与搜索语句相似的文本,其本质上是一种 term-based(基于词)的搜索。
全文搜索的实际使用已经非常广泛,核心技术也非常成熟。但是,除了文本内容之外,现实生活中还有非常多其它的数据形式,例如:图片、音频、视频等等,我们能不能也对这些数据进行搜索呢?
答案是 Yes !
随着机器学习和人工智能等技术的发展,万物皆可 Embedding。换句话说就是,我们可以对文本、图片、音频、视频等等一切数据通过 Embedding 相关技术将其转换成特征向量,而一旦向量有了,向量搜索的需求随之也越发强烈,向量搜索的应用场景也变得一望无际、充满想象力。
图片来源 damo.alibaba.com/events/112
ES 向量搜索说明 ES 向量搜索目前有两种方式:
script_score
_knn_search
script_score 精确搜索 ES 7.6 版本对新增的字段类型 dense_vector 确认了稳定性保证,这个字段类型就是用来表示向量数据的。
数据建模示例:
PUT my-index { "mappings": { "properties": { "my_vector": { "type": "dense_vector", "dims": 128 }, "my_text" : { "type" : "keyword" } } } } 如上图所示,我们在索引中建立了一个 dims 维度为 128 的向量数据字段。
script_score 搜索示例:
{ "
cms和g1的主要区别
1.cms是内存分布式分代连续的,也就是新生代一块连续的区间,年老代一块连续的区间,而g1是把堆分成了2048个region,每个区域region可以作为新生代也可以作为年老代,并且新生代的大小(也即region的个数)是根据期望的暂停时间动态调整的.
2.cms中大对象是直接分配到年老代的,而且ygc是没法回收年老代中的大对象的,必须要通过cms gc才能回收,而g1中大对象是直接分配到Humongous大对象区域的(不过该区域一般认为是年老代),这里g1比较好的一点是ygc的时候就可以回收掉没有引用的大对象了,而不用等到mixed gc再回收
3.cms的主要步骤有:初始标识(stw),并发标识,重新标识(stw),并发清理(cms的清理阶段是和应用线程并发进行的,使用的是标记清除算法,会产生大量的内存碎片); g1的mixed gc中的全局并发标识阶段的主要步骤有:初始标识(stw),并发标识,重新标识(stw),初始清理(stw),并发清理, 混合gc中的初始清理+并发清理作用只是回收完全没有引用的region,然后计算要回收的region中垃圾的占比,排好序后为后面混合gc的时候加入CSet回收集中做好准备,比如为后面的8次gc回收做好计划,如每次回收把哪些region加入到cset集合中,真正的回收操作是紧跟着的mixed gc的evacuation阶段,在evacuation阶段中会分8次回收全局并发标识阶段标记的Region,使用的是标记整理的算法,不会产生内存碎片(但是是stw的).
4.g1比cms会使用更多的内存和cpu负载,所以更适合用于大堆的应用
文章目录 wsl的安装一.启动wsl功能二.子系统的下载三 .子系统的安装四.wsl的迁移五.更换为ubuntu国内源六.软件更新七.安装必要开发工具关于图形化界面的安装将会在近期更新 wsl的安装 所需条件
window 专业版 2004 及更高版本
一.启动wsl功能 首先进行如下操作
点击控制面板
首先启动hype-v服务
然后wsl服务
重启更新
二.子系统的下载 搜索linux会发现很多发行版本
ubuntu是资源占有最小的推荐安装
三 .子系统的安装 下载wsl2 linux内核升级包
下载地址
以管理员身份运行powershell
wsl --set-default-version 2 打开下载的wsl
根据提示完成最小化安装
四.wsl的迁移 由于wsl默认安装在c盘,因此我们需要进行迁移
1关闭wsl
wsl --shutdown 2将需要迁移的Linux,进行导出
wsl --export Ubuntu E:\export.tar //具体为你的wsl地址 3 卸载原有wsl
wsl --unregister Ubuntu 4 导入新地址
wsl --import Ubuntu D:\export\ D:\export.tar --version 2 五.更换为ubuntu国内源 先查看系统版本
源地址
vi /etc/apt/sources.list 将原有源#注释或删除并替换复制的国内源
六.软件更新 apt-get update 七.安装必要开发工具 sudo apt-get install build-essential ! build-essential 包括gcc 等编译器
前言:假期在家没事干,写个小小的项目吧,写的过程中遇到了对我来说是个难题的图片上传,看了很多的博客,琢磨了半天终于写出来了,咱就在这里浅浅的总结一下吧。
先看下效果吧~~
html部分
点击弹框,具体请参考Vant中Popup组件
<template> <div class="box"> <van-cell is-link @click="show = true" class="btn box_btn">点击弹框</van-cell> <van-popup v-model:show="show" round> <div class="box-content"> <p class="title">标题</p> <van-form @submit="onSubmit"> <van-cell-group inset> <van-field v-model="contenttext" name="输入文字" placeholder="请输入文字" :rules="[{ required: true, message: '请输入输入文字' }]" /> <div class="uploader"> <van-uploader :after-read="afterRead" v-model="fileList" multiple :max-count="1" :max-size="1080 * 2400" @oversize="onOversize" /> <!-- 文件预览:v-model="fileList" multiple 限制上传数量::max-count="1" 限制上传大小::max-size="500 * 1024" @oversize="onOversize" --> <p>请上传二维码</p> </div> </van-cell-group> <div class="submit_btn"> <van-button round block type="primary" @click="show = false"> 取消 </van-button> <van-button round block type="
一、安装第三方模块 openpyxl是一个用于处理xlsx格式Excel表格文件的第三方python库,其支持Excel表格绝大多数基本操作。
首先要下载名为"openpyxl"的模块,然后import该模块
安装方法 :1.第一种方法:按win+r----> 输入cmd—>输入以下命令即可
pip install openpyxl 2.第二种方法:打开pycharm,点击File,再点击settings,点击settings之后再点击project下面的project Interpreter,在界面中点击+号,直接搜索openpyxl模块,直接安装即可。
二、excel表内容 1.工作薄(workbook):一个EXCEL文件就称为一个工作薄,一个工作薄中可以包含若干张工作表。
2.工作表(sheet):工作薄中的每一张表格称为工作表,每张工作表都有一个标签,默认为sheet1\sheet2\sheet3来命名,(一个工作 薄默认为由3个工作表组成)
4.单元格(cell): 工作表的每一个格称为单元格
5.行(row): 工作表中的每一行行首数字(1、2、3、)称为行标题;一张工作表最多有65536行
6.列(column): 列标题:工作表中每一列列首的字母(A、B、C)称为列标题;一张工作表最多有256列
三、操作excel 1、工作簿
创建工作簿
工作簿=openpyxl.Workbook('文件名称.xlsx') 工作簿.save(路径) 打开工作簿
工作簿 =openpyxl.load_workbook('文件名称.xlsx') 工作簿属性作用
wb = openpyxl.load_workbook('文件名称.xlsx') print(wb.sheetnames) print(wb.properties) print(wb.active) print(wb.encoding) print(wb.read_only) print(wb.data_only) print(wb.worksheets) 2、工作表
工作表属性作用
单元格属性作用
wb = openpyxl.load_workbook('文件.xlsx') ##选择要操作的工作表, 返回工作表对象 sheet = wb['工作表名称'] #获取工作表的名称 print(sheet.title) # 获取工作表中行和列的最值 print(sheet.max_row) print(sheet.max_column) print(sheet.min_row) print(sheet.min_column) ##修改表的名称 sheet.title = '新名称' print(sheet.title) # 返回指定行指定列的单元格信息 print(sheet.cell(row=1, column=2).value) cell = sheet['B1'] print(cell) print(cell.
文章目录 前言
一.工具安装
二、引入模块
三.开始爬虫
三.使用数据库
四.查询网站
五.拓展
总结
前言 本学期期中作业是 新闻爬虫及爬取结果的查询网站,作为只有c语言基础的小菜鸟,刚看到要求时还是一脸懵,通过半个学期的学习,借助老师的代码,撸起袖子加油干,跌跌撞撞地也实现了爬虫。先来看看啥是爬虫,爬虫就是个自动获取网络内容的程序,又称为网页蜘蛛,网络机器人......(来自百度百科...)ok 话不多说 现在开始实现新闻爬虫以及爬取结果的查询网站。
一.工具安装 1.Nodejs
百度搜索nodejs进入官网
点击下载,找到自己需要的版本
按照提示一路next 安装完成 在cmd中输入node -v可以查看安装版本
2.编码工具VsCode
这里因为以前写C/C++时下载过VScode所以稍微下个插件直接用了,也可以下载WebStorm,Sublime等等
WebStorm下载地址: WebStorm: The Smartest JavaScript IDE, by JetBrains
Sublime下载地址: Sublime Text - Text Editing, Done Right
VScode是一个轻量且强大的跨平台开源代码编辑器(IDE) 打开VScode应用商店下载nodejs插件
3.安装MySQL
下载地址:MySQL :: Download MySQL Community Server
数据库 根据自己需要的版本 下载 后面会详细描述
要下载的工具下载的差不多了,下面正式开始爬虫
二、引入模块 这里先看一下npm这个东西
npm就是Nodejs下的包管理器
允许用户从NPM服务器下载别人编写的第三方包到本地使用。允许用户从NPM服务器下载并安装别人编写的命令行程序到本地使用。允许用户将自己编写的包或命令行程序上传到NPM服务器供别人使用 但是,npm的服务器位于国外可能会影响安装 所以淘宝团队做了国内镜像cnpm,与官方同步频率目前为 10分钟 一次以保证尽量与官方服务同步。
安装方法:
安装:命令提示符执行
npm install cnpm -g --registry=https://registry.npm.taobao.orgcnpm -v 来测试是否成功安装 通过改变地址来使用淘宝镜像
如下图中的while循环
其中变量 如下定义
static uint8_t nb_uart_tx_done = 0; 且在中断中将其赋值1,发现当中断中已经赋值,这个while也跳转不出来,如下是仿真观察到的变量和while不跳出情形
查阅资料发现是这么个情况:
在进入循环的时候,实际上是将A从内存加载到寄存器里面运行的,在整个循环中,A这个变量都只是在读取寄存器里面的值。
而当进入中断的时候,中断里面会从内存加载A到寄存器,修改完之后又存到内存里,然后退出中断,再回到循环里面。但这个时候循环里使用的A并没有重新从内存加载A这个变量,所以一直都在循环里面。
解决方法:
nb_uart_tx_done 变量的定义前加上volatile,详细理解自行查找volatile的用法。
static volatile uint8_t nb_uart_tx_done = 0; 如此一来就不会有前面的加载到寄存器的问题了
一般说来,volatile用在如下的几个地方:
1、中断服务程序中修改的供其它程序检测的变量需要加volatile;
2、多任务环境下各任务间共享的标志应该加volatile;
3、存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能有不同意义;另外,以上这几种情况经常还要同时考虑数据的完整性(相互关联的几个标志读了一半被打断了重写),在1中可以通过关中断来实现,2 中可以禁止任务调度,3中则只能依靠硬件的良好设计了。
2^2+2^3+2^4 = 28 次方当作类型,比如2是添加,3是修改,4是删除
对应的数据转换为二进制 ,然后进行&(位运算,例如相对应位都是1,则结果为1,否则为0)
/** * 是否有权限发布投票 * * @param currentType 当前类型 * @return */ public boolean isPermission(int currentType) { if (getBeanInfo().getUser() != null) { int permission = 28; int currentPow = (int) Math.pow(2, currentType); return currentPow == (permission & currentPow); } return false; }
环境准备:两个mysql服务器分别运行以下命令:
show VARIABLES like 'log_bin' 出现以下信息表示支持
如果value字段是false,需要配置bin_log日志开启
linux下 找到my.cnf在[mysqld]下加入以下配置
log-bin=mysql-bin #主从库此值不能相等 从库 server-id=2 server-id=1 windos下.exe安装的mysql
找到my.ini配置相同配置
重启mysql服务
linux: service mysql restart
docker: docker restart 容器id
windos: 右键 重新启动
再次运行
show VARIABLES like 'log_bin'
完成以上操作后
查看mysql 端口是否开放
先看防火墙是否开启
systemctl status firewalld 以上表示防火墙关闭,跳过端口开放过程
lsof -i:端口号
lsof -i:3306 以上表示端口开放
上面命令执行不了的 可以运行下面的命令
firewall-cmd --query-port=3306/tcp 打开端口号
firewall-cmd --add-port=3306/tcp --permanent 重启一下防火墙
firewall-cmd --reload 环境准备好后 开始主从搭建
一、在主服务上创建一个slave用户
根据自己的mysql版本创建
mysql 5.7 默认身份验证插件default_authentication_plugin是:mysql_native_password
mysql 8.0 默认身份验证插件default_authentication_plugin是:caching_sha2_password
CREATE USER 'slave'@'ip地址' IDENTIFIED WITH caching_sha2_password BY 'password'; CREATE USER 'slave'@'ip地址' IDENTIFIED WITH mysql_native_password BY 'password'; 以防万一这里可以执行以下刷新权限
git中的SSL certificate problem: unable to get local issuer certificate错误的解决办法 我们在使用git初始化一个项目时,尤其是通过git submodule update --init --remote初始化子模块时,可能会遇到下面这个错误:
fatal: unable to access 'https://myserver.com/gogs/user1/myapp/': SSL certificate problem: unable to get local issuer certificate 这是由于当你通过HTTPS访问Git远程仓库的时候,如果服务器上的SSL证书未经过第三方机构认证,git就会报错。原因是因为未知的没有签署过的证书意味着可能存在很大的风险。解决办法就是通过下面的命令将git中的sslverify关掉:
git config --global http.sslverify false 上面这行命令的影响范围是系统当前用户,如果要设置为全局所有用户,可以改成这样:
git config --system http.sslverify false 如果只是想针对当前仓库进行设置,可以在需要修改的仓库目录下执行:
git config http.sslverify false 如果你的仓库中存在嵌套的git子模块(就是子模块中又引用了子模块),在进行初始化时,仍然有可能遇到self signed certificate in certificate chain的错误,此时可以通过执行下面的命令来解决:
npm config set strict-ssl false
具体使用语法规则可以查看下面地址中文档说明: QLExpress:https://github.com/alibaba/QLExpress
<dependency> <groupId>com.alibaba</groupId> <artifactId>QLExpress</artifactId> <version>3.2.0</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.36</version> </dependency> import com.alibaba.fastjson.JSONObject; import com.ql.util.express.DefaultContext; import com.ql.util.express.ExpressRunner; import org.apache.commons.lang3.StringUtils; public class Application { public static void main(String[] args) throws Exception { /** 简单运算表达式 */ ExpressRunner runner_1 = new ExpressRunner(); DefaultContext<String, Object> context_1 = new DefaultContext<String, Object>(); context_1.put("a", 1); context_1.put("b", 2); context_1.put("c", 3); String express_1 = "a + b * c"; Object result_1 = runner_1.execute(express_1, context_1, null, true, false); System.
1. 问题描述:
给你一个字符串 s,找到 s 中最长的回文子串。
示例 1:
输入:s = "babad"
输出:"bab"
解释:"aba" 同样是符合题意的答案。
示例 2:
输入:s = "cbbd"
输出:"bb" 提示:
1 <= s.length <= 1000
s 仅由数字和英文字母组成
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/longest-palindromic-substring/
2. 思路分析:
这道题目类似于最长回文子序列的问题,而子串的限制要求字符串是连续的,但是也是类似的思路,因为同样是求解一个区间中满足某个限制的问题,所以可以使用区间 dp 来解决,只是在状态计算的时候会有些不一样,只需要细微调整一下即可,对于长度为 1 的子串那么回文串的长度为 1;对于长度为 2 的子串判断 s[i] == s[j],相等则为 2;长度大于 2 的子串判断 s[i] == s[j] 并且 f(i + 1,j - 1) 大于 0 说明 s[i + 1:j - 1] 才是回文串。
3. 代码如下:
python(超时):
class Solution: def longestPalindrome(self, s: str) -> str: n = len(s) f = [[0] * (n + 10) for i in range(n + 10)] res = "
Cannot generate ORC metadata for CONFIG_UNWINDER_ORC=y, please install libelf-dev, libelf-devel or elfutils-libelf-devel 错误信息 解决方法 centos需要下载的是提示中的最后一个
yum install elfutils-libelf-devel unable to initialize decompress status for section .debug_info 错误信息: 解决方法: 更新gcc到最新版
yum -y install centos-release-scl yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils scl enable devtoolset-9 bash 编译成功 显示 我这里并没有像其他人那样显示done,我就反复make install了好几次,然后还是这样,就reboot了
用uname-a查看,显示你编译的内核版本
说明成功了
在刚接触PCL时,配置PCL环境应该是最头疼的事情了。
作为一名新手小白,配置PCL环境过程中遇到了很多的坑,浪费了我很多时间。经过我多次的尝试,终于能够很快并且准确无误的配置完成PCL环境。
当然,有的方法比我的可能会更好,我也在不断的学习,希望大家都能够多多进步!
好了,话不多说,我们开始吧!
在开始之前,先讲一下,本文一共分为三个步骤:资料准备、安装程序和配置环境。
希望读者能够先从头到尾阅读完毕,再回过头来开始配置环境,这样可以做到心中有数,不至于出现意想不到的问题。
一、资料准备 1、VS2015版本 VS下载链接:https://visualstudio.microsoft.com/zh-hans/downloads/
2、OpenGL库 OpenGL下载链接:http://链接:https://pan.baidu.com/s/1uJJOOOZ0lH_a7wSFMoo1Fg 提取码:ga8d
OpenGL库有的同学会用到,所以在这里给出链接,自行取用,但我没写配置过程,自行搜索吧,超简单。
3、PCL1.8.0安装程序 PCL下载链接:http://链接:https://pan.baidu.com/s/1NPri0xBFmxnzszHgAQT2fw 提取码:ozmp
二、安装程序 1、PCL安装 PCL整个安装过程需要注意以下三点,其它默认即可(我是安装在C盘):
(1)安装路径不要有中文字符;
(2)安装时,勾选上“Add PCL to the system PATH for all users”;
(3)安装时,会提示安装OpenNI,建议安装在PCL安装路径的3rdParty下的OpenNI2文件夹下;
2、配置pdb文件 安装完成之后,将下载好的PCL-1.8.0-AllInOne-msvc2015-win64-pdb解压,将pdb文件夹中的所有pdb文件拷贝到PCL 安装路径下的bin文件夹中。
三、配置环境 1、系统环境变量配置 (1)右键“我的电脑”或者“此电脑”等,点击 属性->高级系统设置->环境变量,在Path添加上刚才我们安装的PCL里面的bin目录和OpenNI的tools目录
注意:路径要选择自己的PCL程序安装路径,后面所有的路径都要改成你自己的真实路径。
系统变量配置完成后重启电脑,,,重启电脑,,,重启电脑,,,
2、项目环境配置 (1)包含目录和库目录
打开VS,新建一个项目(这里随意哈,项目的名字和路径都随意)。
在菜单栏找到“视图”->"其他窗口"->“属性管理器”,如下图,你将在右侧看到属性管理器页面。
左键选中“Release|64”,右键“添加新项目属性表”,名称你随意,不要中文字符、自己知道就行。
然后确定,你会得到一个新的属性表,如下图。
在新建的属性表上右键->属性。
打开”VC++目录“,选择包含目录,把PCL里面的include目录路径输入进去。
你可以直接复制我的,但我不建议你这么做。
C:\Program Files\PCL 1.8.0\3rdParty\VTK\include\vtk-7.0; C:\Program Files\PCL 1.8.0\3rdParty\Qhull\include; C:\Program Files\PCL 1.8.0\3rdParty\OpenNI2\Include; C:\Program Files\PCL 1.8.0\3rdParty\FLANN\include; C:\Program Files\PCL 1.8.0\3rdParty\Eigen\eigen3; C:\Program Files\PCL 1.8.0\3rdParty\Boost\include\boost-1_61; C:\Program Files\PCL 1.8.0\include\pcl-1.8 打开”VC++目录“,选择库目录,把PCL里面lib目录路径填进去。
本文以7系列的XC7K325T进行介绍,首先看看FPGA的电源主要由核电VCCINT,block RAM供电VCCBRAM,辅助电压VCCAUX和VCCAUX_IO,IO电压VCCO,高速GTX接口电压VMGTAVCC,VMGTAVTT,VMGTVCCAUX,VMGTAVTTRCAL等电压组成,具体如下图1所示。在设计采用典型设计即可,需要注意的VCCO里面分为HR bank电压和HP bank电压,其中HR bank电压一般为3.3V设计,但是遇到网络接口时一般设计为2.5V;HP为高速bank,常常用于ddr设计,电压为1.5V,后面会一章专门讲到DDR设计方面的内容。高速GTX接口电压VMGTAVCC,VMGTAVTT,VMGTVCCAUX,VMGTAVTTRCAL分别按照为1.05V,1.2V,1.8V,1.2V进行设计。需要注意的是,如果咱们使用的GTX中QPLL的时钟速率没有超过10.3125GHZ时,VMGTAVCC和VCCINT电压可以一致。
上面讲了电压的分类,接下来讲一下各个电压电流要求,对于我们电源设计非常重要,通过下图2我们可以查找FPGA的上电各个电压电流要求,以XC7K325T为例,通过手册查询到ICCINTQ,ICCAUXQ,ICCOQ,ICCOAUXIOQ,ICCBRAMQ的电流值,并根据下图计算各个电压的需要的电流值,在计算电流
前面讲了电源电压分类和上电电流要求,接下来讲一下各电压上电顺序要求,具体如下:
(1)VCCINT VCCBRAM VCCAUX VCCAUX_IO VCCO ;
(2)VMGTAVCC VMGTAVTT VMGTAVTTRCAL VMGTVCCAUX。
在上电顺序满足要求的情况下,电压的上电斜坡时间必须满足下图3中的要求,所有电源电压斜坡时间在0.2ms~50ms之间,超过此时间FPGA启动异常。需要说明一下,这里说的是斜坡时间不是说所有电源电压的在50ms之内输出完成。
输出时要考虑上电浪涌会造成电流变大的,所以在选择电源电流输出留有较大裕量。本文以7系列FPGA举例说明电源设计要求,这些都是我们在看看FPGA技术手册常常关注的设计点,有了这些知识点,再设计自己的电源电路部分或者参考别人设计的电源电路时,就知道怎么去考虑,怎么去理解别人设计的电路,才能够设计出稳定可靠的FPGA供电电源,从而避免在FPGA高低试验过程中 ,因为电源设计问题造成FPGA工作不正常的情况。
1. 问题描述:
给定一个正整数 x,你可以对其各个数位上的数字进行反转操作。反转操作是指将一个数 t 替换为 9−t,请你计算,通过一系列的反转操作(也可以不进行任何操作),能够将 x 转换为的最小可能正整数,注意,最终数字不能以 0 开头。
输入格式
一个正整数 x
输出格式
一个正整数,表示可以得到的最小可能正整数
数据范围
所有测试点满足 1 ≤ x ≤ 10 ^ 18
输入样例1:
27
输出样例1:
22
输入样例2:
9
输出样例2:
9
输入样例3:
91730629
输出样例3:
91230320
来源:https://www.acwing.com/problem/content/description/4428/
2. 思路分析:
分析题目可以知道当某一位大于等于 5 之后那么应该翻转一下,而对于首位则需要特判一下,判断是否是替换后是否是 0,如果是 0 那么就需要将其换为 9,依次枚举每一位模拟整个过程即可。
3. 代码如下:
python:
if __name__ == '__main__': n = int(input()) nums = list() while n > 0: nums.append(n % 10) n //= 10 res = 0 for i in range(len(nums) - 1, -1, -1): x = nums[i] if x >= 5: x = 9 - x if i == len(nums) - 1 and x == 0: x = 9 res = res * 10 + x print(res) go:
作为C/C++开发人员,在平时的项目开发过程中,或多或少的听过左值和右值的概念,甚至在编译器报错的时候,遇到过lvalue和rvalue等字样;甚至使用过std::move(),但是不知道其含义。作为多年的C++开发人员,一直以来,对左值右值的理解没有一个系统的认识,总感觉似懂非懂。今天,借助本文,详细的介绍下这些知识点,并从代码实例的角度去分析什么是左值或者右值,同时,也算是给自己知识点做一个总结。
1背景 作为C++开发人员,相信我们都写过如下代码:
void fun(int &x) { // } int main() { fun(10); return 0; } 在编译的时候,会提示如下:
error: invalid initialization of non-const reference of type ‘int&’ from an rvalue of type ‘int’
从“int”类型的右值对“int&”类型的非常量引用进行无效初始
其中上述报错中的rvalue就是10,也就是说10就是rvalue,那么到底什么是rvalue,rvalue的意义是什么?这就是本文的目的,通过本文,让你彻底搞清楚什么C++下的值类别,以及如何区分左值、纯右值和将亡值。
本文的主要内容如下图所示:
2历史 在正式介绍左值和右值之前,我们先介绍下其历史。
编程语言CPL第一次引入了值类别,不过其定义比较简单,即对于赋值运算符,在运算符左边的为左值,在运算符右边的为右值。
C语言遵循与CPL类似的分类法,但是弱化了赋值的作用,C语言中的表达式被分为左值和其它(函数和非对象值),其中左值被定义为标识一个对象的表达式。不过,C语言中的左值与CPL中的左值区别是,在C语言中lvalue是locator value的简写,因此lvalue对应了一块内存地址。
C++11之前,左值遵循了C语言的分类法,但与C不同的是,其将非左值表达式统称为右值,函数为左值,并添加了引用能绑定到左值但唯有const的引用能绑定到右值的规则。几种非左值的C表达式在C++中成为了左值表达式。
自C++11开始,对值类别又进行了详细分类,在原有左值的基础上增加了纯右值和消亡值,并对以上三种类型通过是否具名(identity)和可移动(moveable),又增加了glvalue和rvalue两种组合类型,在后面的内容中,会对这几种类型进行详细讲解。
3表达式 C/C++代码是由标识符、表达式和语句以及一些必要的符号(大括号等)组成。
表达式由按照语言规则排列的运算符,常量和变量组成。一个表达式可以包含一个或多个操作数,零个或多个运算符来计算值。每个表达式都会产生一些值,该值将在赋值运算符的帮助下分配给变量。
在C/C++中,表达式有很多种,我们常见的有前后缀表达式、条件运算符表达式等。字面值(literal)和变量(variable)是最简单的表达式,函数的返回值也被认为是表达式。
表达式是可求值的,对表达式求值可得到一个结果,这个结果有两个属性:
类型。这个我们很常见,比如int、string、引用或者我们自定义的类。类型确定了表达式可以进行哪些操作。值类别(在下节中会细讲)。 4值类别 在上节中,我们提到表达式是可求值的,而值类别就是求值结果的属性之一。
在C++11之前,表达式的值分为左值和右值两种,其中右值就是我们理解中的字面值1、true、NULL等。
自C++11开始,表达式的值分为左值(lvalue, left value)、将亡值(xvalue, expiring value)、纯右值(prvalue, pure ravlue)以及两种混合类别泛左值(glvalue, generalized lvalue)和右值(rvalue, right value)五种。
这五种类别的分类基于表达式的两个特征:
具名(identity):可以确定表达式是否与另一表达式指代同一实体,例如通过比较它们所标识的对象或函数的(直接或间接获得的)地址可被移动:移动构造函数、移动赋值运算符或实现了移动语义的其他函数重载能够绑定于这个表达式 结合上述两个特征,对五种表达式值类别进行重新定义:
lvalue:具名且不可被移动xvaue:具名且可被移动prvalue:不具名且可被移动glvalue:具名,lvalue和xvalue都属于glvaluervalue:可被移动的表达式,prvalue和xvalue都属于rvalue
用图表示如下: 从glvalue和rvalue出发,将具名(indentity)和可移动两个特征结合起来,如下图所示:
在上图中,I代表indentity,M代表moveable。以xvalue为例,在上图中xvalue为(I&M),即代表具名且可移动。
隔离DC-DC电源模块是指隔离电源是使用变压器将各种不同电压(如:48VDC,24VDC,12VDC等)通过变压器将电压降到所需要的电压,然后作为负载供电使用。
非隔离DC-DC电源模块是将各种不同电压直接引入到电子电路,再通过电子元件进行升降压输出,输入输出是通过电子元件直接连接的,中间并没有经过变压器等带隔离性的器件,所以称非隔离电源模块。
小编多年与客户沟通中,会经常遇到客户提问:“隔离电源模块和非隔离电源模块有什么区别?”今天,小编就从以下几点给大家做一下简要的解释,同时也把俞霖科技的DC-DC隔离电源模块与非隔离电源模块给大家进行对比。
市场上隔离电源模块与非隔离电源模块的区别
1.安全性
DC-DC隔离电源模块是指隔离电源是使用变压器将各种不同电压(如:48VDC,24VDC,12VDC等)通过变压器将电压降到所需要的电压,然后作为负载供电使用。
DC-DC非隔离电源模块是将各种不同电压直接引入到电子电路,再通过电子元件进行升降压输出,输入输出是通过电子元件直接连接的,中间并没有经过变压器等带隔离性的器件,所以称非隔离电源模块。
考虑到用户的安全使用产品以及用户和市场的需求,俞霖科技工程师们在设计电源方案时一般都会考虑系统的绝缘以及隔离的可靠性。相比之下,DC-DC隔离电源模块相比非隔离电源模块安全性更高一些。
2.效率
非隔离电源模块由于少了变压的磁电转换所损失的能量,所以效率一般较高,行业中大多电源厂家的非隔离电源模块的效率都能达到91%以上。相比之下,DC-DC隔离电源模块一般效率都在88%以下,所以DC-DC隔离电源模块发热相对来说会比非隔离电源模块的大。
3.成本与体积
非隔离电源模块由于不需要采用变压器进行输入输出之间的电气隔离,所以相比DC-DC隔离电源模块,同样的输出功率,同样的输出性能(如输出精度,负载效应,动态响应等),非隔离电源模块所需要的体积更小,成本更低,设计难度相对较小。如果说设计上可以考虑输入输出之间不隔离,相比DC-DC隔离电源模块,采用非隔离电源模块来进行设计那可以说是工程师的首选。
4.带载范围
DC-DC隔离电源模块的输出带载范围小于非隔离电源模块带载范围。
一般来讲DC-DC隔离电源模块的输出带载范围为30-42V,非隔离电源模块带载范围可以为30-84V。众多厂家在选择电源的时候为了整体的适应性都要求电源能够适应全电压90-265V输入,带载范围也要求高达84V,这样的选择是存在一定风险和隐患的。90V输入的时候电源可能丧失恒流功能,总谐波失真这些非隔离适合做高压小电流,做大电流成本并不比隔离的便宜。
俞霖科技隔离电源模块与非隔离电源模块对比
HRB 系列隔离宽电压输入高电压稳压输出 应用 HRB W2~40W 系列模块电源是一种DC-DC升压变换器。该模块电源的输入电压分为:4.5~9V、9~18V、及18~36VDC标准(2:1)宽输入电压范围(宽电压输入模块电源是指输入电压可以允许在很宽的范围内变化)。输出单电压:50V、100VDC、110VDC、150VDC、200VDC、250VDC、400VDC、500VDC、600VDC、800VDC、1000VDC等,具有功率密度大,输出功率高,应用范围广等优点。
特点 效率高达 80%以上1*2英寸标准封装单电压输出价格低稳压输出工作温度: -40℃~+85℃阻燃封装,满足UL94-V0 要求温度特性好可直接焊在PCB 上 技术参数 HRB隔离升压产品型号选择指南
输入电压值,可根据客户的需求设定最小输入值电压输出电压值,如果只是给定一个电压值,就是不带调节端的产品,如果给定一个范围,那就是带ADJ调节端的产品,具体电位器的电阻值,可根据产品标签上值来匹配.功率大小都可以按客户的具体要求来订制,因为每一款升压模块都是特殊的,所以不存在订制产品费用.开关控制端, 当需要控制高压关断的时候就要加上这个后缀,这个控制端子是高电位有效,高于2.5V就可以打开输出高电压,需要关断的时候,直接给定低于0.3V的电压或者直接短接到负输入端即可. 部分产品型号参数 产品举例说明 型号:HRB12110D-10W,输出端E2电容可选 22UF/200V的电解电容。输入电压Vin:9~18VDC;输出电压Vout:110VDC;输出功率:10W型号:HRB24200~300D-10W,输出端E2电容可选 10UF/450V的电解电容。输入电压Vin:18~36VDC;输出电压Vout:250VDC;输出功率:10W型号:HRB24500D-6W-REM ,输出端E2电容可选10UF/450V的电解电容两个进行串联来来滤波 输入电压Vin:18~36VDC;输出电压Vout:500VDC;输出功率:6W 带控制高压输出的REM端. 外型尺寸及引脚描述 HRB 0.2~40W 系列 产品尺寸:50.8x25.4x12.5 单位: mm
产品应用原理图及器件选型 FUSE:1.5~2 倍的最大输入电流E1:至少两倍的输入电压耐压容量 47~220UFC1:0.1UF/50VL1:10~100UH 2 倍的最大输入电流,可选加E2 至少1.5 倍的输出高压耐压,容值建议值 10~47UF,要选用高频低阻型的电解电容.ADJ(20K):如果需要电压调节,就必须接这个电位器,或者改用电阻替换,短接时输出最高电压值,20K 输出最小值电压值.REM控制端:高电位有效高电压输出. GRB 系列非隔离宽电压输入高电压稳压输出 产品特点 效率高达 75%以上1*2英寸标准封装单电压输出可直接焊在PCB 上工作温度: -40℃~+75℃阻燃封装,满足UL94-V0 要求温度特性好电压控制输出,输出电压随控制电压的变化线 产品应用 GRB 系列模块电源是一种DC-DC升压变换器。该模块电源的输入电压分为:4.5~9V、9~18V、及18~36VDC标准(2:1)宽输入电压范围(宽电压输入模块电源是指输入电压可以允许在很宽的范围内变化)。输出最高电压:50V、100VDC、110VDC、150VDC、200VDC、250VDC、300VDC、350VDC、500、1000V等,具有功率密度大,输出功率高,应用范围广等优点。
技术参数 部分产品型号参数 GRB XX XXXD-XXmA-U1
文章目录 1.进入官网下载最新版本2.Apache在windows系统上的服务配置1. 首先解压至指定位置2.服务的安装进入安装路径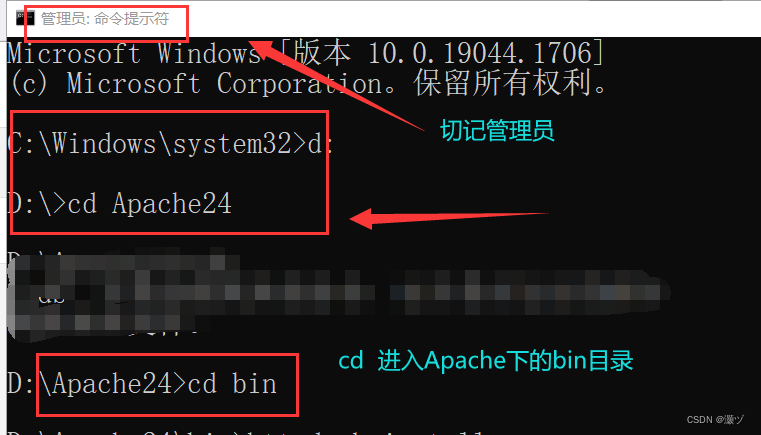安装服务!提示错误** 安装成功 3.httpd网络配置相关参数说明通过浏览器访问http服务查询本机ip最后浏览器输入http://ip地址 4.配置自己的网页相关错误处理 https://httpd.apache.org/
1.进入官网下载最新版本 选择Windows版
按照本机系统选择
2.Apache在windows系统上的服务配置 1. 首先解压至指定位置 HTML文件为软件的相关说明
2.服务的安装 以管理员身份打开cmd
进入安装路径 安装服务 httpd -k install !提示错误** 需进行相关配置
安装成功 3.httpd网络配置 相关参数说明 httpd.conf: Listen: //http服务的监听端口 ServerRoot: //设置服务器所在目录 \extra\httpd-ahssl.conf中的Listen :https监听端口 通过浏览器访问http服务 查询本机ip cmd输入
ipconfig
找到这个
iPV4
如果为有线网络则选以太网
最后浏览器输入http://ip地址 4.配置自己的网页 apache 安装目录下的htdocs目录为网站文件
打开首页名称必须为index.html
由于ip原因当前网页只能局域网内访问,公共网页请使用公网服务器或内网穿透
相关错误处理 请确定为管理员身份是控制面板不是powershell其他错误可能为依赖问题
创建表SQL create table Student(sid varchar(10),sname varchar(10),sage datetime,ssex nvarchar(10)); insert into Student values('01' , '赵雷' , '1990-01-01' , '男'); insert into Student values('02' , '钱电' , '1990-12-21' , '男'); insert into Student values('03' , '孙风' , '1990-05-20' , '男'); insert into Student values('04' , '李云' , '1990-08-06' , '男'); insert into Student values('05' , '周梅' , '1991-12-01' , '女'); insert into Student values('06' , '吴兰' , '1992-03-01' , '女'); insert into Student values('07' , '郑竹' , '1989-07-01' , '女'); insert into Student values('08' , '王菊' , '1990-01-20' , '女'); create table Course(cid varchar(10),cname varchar(10),tid varchar(10)); insert into Course values('01' , '语文' , '02'); insert into Course values('02' , '数学' , '01'); insert into Course values('03' , '英语' , '03'); create table Teacher(tid varchar(10),tname varchar(10)); insert into Teacher values('01' , '张三'); insert into Teacher values('02' , '李四'); insert into Teacher values('03' , '王五'); create table SC(sid varchar(10),cid varchar(10),score decimal(18,1)); insert into SC values('01' , '01' , 80); insert into SC values('01' , '02' , 90); insert into SC values('01' , '03' , 99); insert into SC values('02' , '01' , 70); insert into SC values('02' , '02' , 60); insert into SC values('02' , '03' , 80); insert into SC values('03' , '01' , 80); insert into SC values('03' , '02' , 80); insert into SC values('03' , '03' , 80); insert into SC values('04' , '01' , 50); insert into SC values('04' , '02' , 30); insert into SC values('04' , '03' , 20); insert into SC values('05' , '01' , 76); insert into SC values('05' , '02' , 87); insert into SC values('06' , '01' , 31); insert into SC values('06' , '03' , 34); insert into SC values('07' , '02' , 89); insert into SC values('07' , '03' , 98); 表结构 学生表 Student
同步、异步,并发、并行、串行,这些名词在我们的开发中会经常遇到,这里对异步编程做一个详细的归纳总结,希望可以对这方面的开发有一些帮助。
1 几个名词的概念 多任务的时候,才会遇到的情况,如:同步、异步,并发、并行。
1.1 理清它们的基本概念 逻辑调用方式逻辑结构的设计模式同步:多任务开始执行,任务 A、B、C 全部执行完成后才算是结束。
异步:多任务开始执行,只需要主任务 A 执行完成就算结束,主任务执行的时候,可以同时执行异步任务 B、C,主任务 A 可以不需要等待异步任务 B、C 的结果。并发:多个任务在同一个时间段内同时执行,如果是单核心计算机,CPU 会不断地切换任务来完成并发操作。
并行:多任务在同一个时刻同时执行,计算机需要有多核心,每个核心独立执行一个任务,多个任务同时执行,不需要切换。串行是同步的一种实现,就是没有并发,所有任务一个一个执行完成。并发、并行是异步的 2 种实现方式。 1.2 举一个例子 你的朋友在广州,但是有 2 辆小汽车在深圳,需要你帮忙把这 2 辆小汽车送到广州去。
同步的方式,你先开一辆小汽车到广州,然后再坐火车回深圳,再开另外一辆小汽车去广州。这是串行的方法,2 辆车需要的时间也就更长了。
异步的方式,你开一辆小汽车从深圳去广州,同时请一个代驾开另外一辆小汽车从深圳开去广州。这也就是并行方法,两个人两辆车,可以同时行驶,速度很快。
并发的方式,你一个人,先开一辆车走 500 米,停车跑回来,再开另外一辆车前行 1000 米,停车再跑回来,循环从深圳往广州开。并发的方式,你可以把 2 辆车一块送到朋友手里,但是过程还是很辛苦的。
1.3 思考问题 你找一家汽车托运公司,把 2 辆车一起托运到广州。这种方式是同步、异步,并发、并行的哪种情况呢?
2 并发/并行执行会遇到的问题 2.1 问题 1:并发的任务数量控制 假设:某个接口的并发请求会达到 1 万的 qps,所以对接口的性能、响应时长都要求很高。
接口内部又有大量 redis、mysql 数据读写,程序中还有很多处理逻辑。如果接口内的所有逻辑处理、数据调用都是串行化,那么单个请求耗时可能会超过 100ms,为了性能优化,就会把数据读取的部分与逻辑计算的部分分开来考虑和实现,能够独立的部分单独剥离出来作为异步任务来执行,这样就把串行化的耗时优化为并发执行,充分利用多核计算机的性能,减少单个接口请求的耗时。
假设的数据具体化,如:这个接口的数据全部是可以独立获取(支持并发),需要读取来自不同数据结构的 redis 共 10 个,读取不同数据表的数据共 10 个。那么一次请求,数据获取就会启动 10 个 redis 读取任务,10 个 mysql 读取任务。每秒钟 1 万接口请求,会有 10 万个 redis 读取任务和 10 万个 mysql 读取任务。这 21 万的并发任务,在一秒钟内由 16/32 核的后端部署单机来完成,虽然在同一时刻的任务数量不一定会是 21 万(速度快的话会少于 21 万,如果处理速度慢,出现请求积压拥堵,会超过 21 万)。
一、echarts 案例借鉴 1、官网案例借鉴
2、echarts 案例集锦,支持在线修改,查看属性,下载案例到本地,新增收藏等
二、echarts 柱状图(bar) 1、x轴 增加滚动条
// charts x轴 增加滚动条 // 在option 配置项中添加 【 dataZoom 中配置 】 设置x轴滚动条 // 效果图: 动态拖动 // 以下参考代码 // dataZoom配置 option = { xAxis: { type: 'category', data: ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'] }, dataZoom: [{ type: 'slider', show: true, xAxisIndex: [0], left: '9%', bottom: -5, start: 10, end: 90 //初始化滚动条 }], yAxis: { type: 'value' }, series: [{ data: [120, 200, 150, 80, 70, 110, 130], type: 'bar', barWidth:30,//设置柱状图宽度 }] }; 2、x y 轴滚动
1. LocalDateTime获取某月的第一天开始时间和最后一天的结束时间 /** * 获取指定年和月的第一天和最后一天 * 应用:数据库同步,本地库和其他库按照月份分组统计后,两两比对后,得到不相同的月份, * 根据月份的第一天和最后一天,查询两个库具体值,做交集或差集,然后得到未同步 * 的数据后同步数据 * 2022-12 xx * 2022-11 xx * @param month 2022-12 * @return */ public static Map<String, LocalDateTime> getDateOfMonth(String month){ Map<String,LocalDateTime> map = new HashMap<String, LocalDateTime>(2); LocalDate date = LocalDate.parse(month +"-10", DateTimeFormatter.ofPattern("yyyy-MM-dd")); //根据月份的随便一天获取这个月的第一天以及最后一天 LocalDate first = date.with(TemporalAdjusters.firstDayOfMonth()); LocalDate last = date.with(TemporalAdjusters.lastDayOfMonth()); //获取一天的第一秒和最后一秒 LocalTime beginTime = LocalTime.MIN; LocalTime endTime = LocalTime.MAX; //某月的第一天的第一秒 LocalDateTime beginDatetime = LocalDateTime.of(first, beginTime); //某月的最后一天的最后一秒 LocalDateTime endDatetime = LocalDateTime.
Kubernetes 部署 MySQL 高可用读写分离 简介: 在有状态应用中,MySQL是我们最常见也是最常用的。本文我们将实战部署一个一组多从的MySQL集群。
一、配置准备 configMap cat > mysql-configmap.yaml << EOF apiVersion: v1 kind: ConfigMap metadata: name: mysql labels: app: mysql data: master.cnf: | # Apply this config only on the master. [mysqld] log-bin slave.cnf: | # Apply this config only on slaves. [mysqld] super-read-only EOF configMap可以将配置文件和镜像解耦开。
上面的配置意思是,创建一个master.cnf文件配置内容为:log-bin,即开启bin-log日志,供主节点使用。
创建一个slave.cnf文件配置内容为:super-read-only,设为该节点只读,供备用节点使用。
service cat > mysql-services.yaml << EOF apiVersion: v1 kind: Service metadata: name: mysql labels: app: mysql spec: ports: - name: mysql port: 3306 clusterIP: None selector: app: mysql --- # Client service for connecting to any MySQL instance for reads.
本文由RT-Thread论坛用户@出出啊原创发布:https://club.rt-thread.org/ask/article/2460fcd7db4821ae.html
前言 接触 rt-thread 已有半年,混论坛也5个半月了,期间遇到过各种奇奇怪怪的棘手问题,有过尴尬,也自信曾经提供过比较妙的应对方案。所以产生了将一些典型的使用技巧汇总分享出来的想法,遂有此篇。
入门篇 Q1. 刚下载的 SDK 啥也没干,编译没错,为啥程序跑不起来? 如果使用 keil + env 环境,下载源码后的第一件事就是 menuconfig ;
如果使用 RT-Studio ,创建项目后的第一件事就是打开 Settings ;
把其中所有配置页面所有配置项全浏览一遍,取消掉所有不相干的配置,最后只留一个内核。
先保证最小系统跑起来,用点灯程序验证最小系统运行正常。然后再添加自己需要用到的功能和底层外设等等。
Q2. 刚下载的 SDK 啥也没干,编译没错,为啥程序跑起来 hard fault on thread? 同上
Q3. 刚下载的 SDK 啥也没干,编译为啥报错了? 同上
内核篇 Q1. RT_NAME_MAX 定义多少合适 原则上越少越省内存,以内核对象 100 个为例,一个对象名占用 8 字节,总共是 800 字节。但是考虑到 struct rt_object 结构体定义,后面跟了两个 rt_uint8_t 型变量。
RT_NAME_MAX 可以定义成 2n + 2
Q2. RT_DEBUG 如非必要,不要开启内核调试。除非,你真的想学习内核,或者调试内核的问题。
Q3. 线程栈大小定义多少合适? 这个问题和应用有很大关系,如果仅仅是一个最小内核系统,除了 idle 线程,没有使用其它中断和应用,256 也将将够。如果添加了应用代码,还有中断和消息机制。建议 1024 起步。
要在 Mysql 中保存 4 字节长度的 UTF-8 字符,需要使用 utf8mb4 字符集(mb4就是most bytes 4的意思,专门用来兼容四字节的unicode),但只有 5.5.3 版本以后的才支持。
为了获取更好的兼容性,应该总是使用 utf8mb4 而非 utf8. 对于 CHAR 类型数据,utf8mb4 会多消耗一些空间,根据 Mysql 官方建议,使用 VARCHAR 替代 CHAR。其实,utf8mb4是utf8的超集,理论上原来使用utf8,然后将字符集修改为utf8mb4,也会不会对已有的utf8编码读取产生任何问题。当然,为了节省空间一般情况下使用utf8也就够了!转换是否有影响
MySQL 可以设置数据库级别,表级别,列级别 字符集编码 优先级顺序为:数据库字符集 < 表字符集 < 列字符集
也就是 上面三个级别 字符集不一致时,以 更小范围的配置 为准;
例如:数据库字符集为utf8,表字符集不设置的情况下会默认utf8。如果表主动设置了编码 utf8mb4,那么表的字符集编码就为utf8mb4。
MySQL数据库的"utf8"并不是真正概念里的UTF-8 转载链接
MySQL中的“utf8”编码只支持最大3字节每字符。真正的大家正在使用的UTF-8编码是应该能支持4字节每个字符。
MySQL的开发者没有修复这个bug。他们在2010年增加了一个变通的方法:一个新的字符集“utf8mb4”
当然,他们并没有对外公布(可能因为这个bug有点尴尬)。现在很多指南推荐用户使用“utf8”其实都错了!
简单的说:
MySQL中的 “utf8mb4” 才是 真正意义上的“UTF-8”。
MySQL的utf8是个“特殊的字符编码”。这种编码很多Unicode字符保存不了。
建议MySQL和MariaDB用户使用“utf8mb4”而不是“utf8”。
编码是什么?什么是UTF-8?
计算机使用0和1存储文字。比如第一段第一个字符存储为“01000011”表示“C”,计算机通过以下两个步骤选择用“C”表示:
计算机读取到“01000011”后计算出这是数字67。
计算机通过查找Unicode字符集来确认67代表的“C”。
同样的事情发生在我打字输入C的时候。
计算机通过Unicode字符集将“C” 映射为67。
计算机把67编码为“01000011”发送给web服务器。
几乎所有的程序和互联网应用使用Unicode字符集。
Unicode字符集里有超过100万个字符(“C” 和 “❤” 是两种不同的字符)。UTF-32是最简单的编码方式,它在表示每个字符的时候使用32个bits。这样编码简单,但是并不实用,明显浪费了太多的空间。
UTF-8相比UTF-32更加节约空间。在UTF-8中,像“C”这样的字符占用8bits,“❤”这样的占用32 bits。其他字符占用16或者24 bits。用UTF-8存储比用UTF-32节省4倍左右的空间。更小的空间占用也意味着加载速度会快上4倍。
Python 官网:https://www.python.org/
Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅仅是基础那么简单…… My CSDN主页、My HOT博、My Python 学习个人备忘录好文力荐、 老齐教室 自学并不是什么神秘的东西,一个人一辈子自学的时间总是比在学校学习的时间长,没有老师的时候总是比有老师的时候多。
—— 华罗庚
Python 的字符串处理 朴实无华的四则运算计算器 批量计算小学生四则运算表达式 题目 Python 的字符串处理, 一个朴实无华的四则运算计算器,批量计算小学生四则运算表达式
# -*- coding: UTF-8 -*- import re def naive_calc(code): def test(): code = ''' 1+2 3+4 5-3 4*3 10/2 ''' naive_calc(code) if __name__ == '__main__': test() 此题目错误选项忽略了re获取的数字是str的事实,没有用int转换。
其实,还可以用python内置函数eval()直接转换str.split(“/n”)得来的字符串计算表达式。
效果
代码:
def naive_calc(code): ''' 简单计算器 ''' return eval(code) # 用python内置函数eval()转换计算表达式字符串为python可执行代码语句。 if __name__ == '__main__': codes = ''' 1+2 3+4 5-3 4*3 10/2 ''' tem = [code.
一、实验名称 超文本传输协议 Http分析
二、实验目的 1. 掌握使用Wireshark分析俘获HTTP协议的基本技能;
2. 深刻理解HTTP重要的工作机理和过程。
三、实验内容和要求 1、 Http协议的Get/Resonse互动机制;
2、 Http协议的分组格式;
3、 如何利用Http传输Html文件;
4、 如何利用Http传输图片、动画等嵌入式文件;
四、实验环境
1. 运行windows 10 操作系统的PC一台。
2. IE浏览器等软件。
3. 每台PC运行程序协议分析仪 Wireshark。
五、操作方法和实验具体步骤
1.Http 的基本请求/响应互动机制
(1)打开 chrome 浏览器
(2)打开 Wireshark软件,打开抓包菜单中的网络接口子菜单,从中选择本机使用的网络接口。
(3)切入包捕获界面后,在过滤栏中输入http&&ip.dst==128.119.245.12||ip.src==128.119.245.12,即只观察与128.119.245.12交互的http分组。
(4)在chrome浏览器输入 :http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file1.html;此时浏览器应该会显示一个最简单的 html 页面(只有一行 ),如图1所示:
图1 浏览器显示的页面
(5)此时,Wireshak软件应该抓取的Http数据包如图2所示。
图2 俘获的http分组
从上图中可观察到总共捕获到四个 http 包,其中,包括 Http 的 Get分组(由本机浏览器向服务器 gaia.cs.umass.edu发出的请求 )以及服务器返回的响应分组。需要注意的是,第一轮请求与回复请求的是具体的页面;而第二轮请求与回复涉及的却是一个 favicon.ico 文件。分组内容展示窗口中可以观察这两个分组的详细信息。从展开的分组内容中可以看出: Http 包是经由Tcp协议传输,而 Tcp 又是附加在IP 数据包的基础上,后者又附加在一个以太网帧内。以第一轮分组为观察目标,试着回答如下问题:
(1 )你的浏览器运行的是什么协议版本? Http1.0 还是Http1. 1?服务器运行的又是什么版本呢?
我的浏览器运行的是Http1. 1版本(Request Version: HTTP/1.
jsp
Java Server Page
什么是jsp jsp站在客户端来看,jsp是一个显示内容的页面,能动态的显示页面中的内容,所以称jsp为动态页面,比如login.jsp(能从后台获取数据更新自己的页面),能在jsp页面写java代码,所以jsp可以看成是java+html,站在程序员来看,其实jsp就是一个servlet(在tomcat容器中将访问的jsp编译并翻译为servlet),但各自有各自的特点,所以共存,jsp重点用于显示动态内容,servlet则重于完成动态数据模型的业务逻辑处理
为什么会有jsp? html 多数情况下用来显示静态内容 , 一成不变的。 但是有时候我们需要在网页上显示一些动态数据, 比如: 查询所有的学生信息, 根据姓名去查询具体某个学生。 这些动作都需要去查询数据库,然后在网页上显示。 html是不支持写java代码 , jsp里面可以写java代码。
怎么用JSP
指令写法
<%@ 指令名字 %>
page指令
language 表明jsp页面中可以写java代码
contentType 其实即使说这个文件是什么类型,告诉浏览器我是什么内容类型,以及使用什么编码
contentType="text/html; charset=UTF-8"
text/html MIMEType 这是一个文本,html网页
pageEncoding jsp内容编码extends 用于指定jsp翻译成java文件后,继承的父类是谁,一般不用改。import 导包使用的,一般不用手写。session 值可选的有true or false .
用于控制在这个jsp页面里面,能够直接使用session对象。
具体的区别是,请看翻译后的java文件 如果该值是true , 那么在代码里面会有getSession()的调用,如果是false : 那么就不会有该方法调用,也就是没有session对象了。在页面上自然也就不能使用session了。
errorPage 指的是错误的页面, 值需要给错误的页面路径
isErrorPage 上面的errorPage 用于指定错误的时候跑到哪一个页面去。 那么这个isErroPage , 就是声明某一个页面到底是不是错误的页面。
页面设置errorPage跳转属性的结果页面
应该这样呈现给客户端
而非这样:
include
包含另外一个jsp的内容进来。
<%@ include file="other02.jsp"%>
背后细节: 把另外一个页面的所有内容拿过来一起输出。 所有的标签元素都包含进来。
游戏由服务器端和客户端两部分组成。
在服务器端,ServerModel类主要用来创建主机,ServerView类主要负责服务器端图形界面的面板信息的设置,ServerControler类处理来自服务器视图框架的输入,包括创立通信与帮助信息等,enemy类主要负责敌方坦克的创建,player类主要用来设置玩家的得分及其显示位置等信息,drawingPanel类主要负责服务器端界面窗口的创建和设置,powerUp类主要用来设置子弹属性,例如加快速度、提升火力等,feedbackHandler类主要用来解码从客户端发来的指令字符串,再将其转换成指令来判断游戏失败后玩家是否继续游戏的问题。
在客户端,ClientModel类主要用来设置与服务器的连接,ClientView类主要负责客户端端图形界面的面板信息,ClientControler类主要负责处理来自客户端视图框架的输入和创立通信与帮助信息等,drawingPanel主要用来设置客户端窗口界面,instructionHandler类主要用来解码从服务器端发来的指令字符串,再将其转换成指令来判断游戏失败后玩家是否继续游戏的问题,shield类主要负责设置坦克吃掉头盔图标获得保护时的状态,normalObject类主要用来创建和描绘其他物体对象。
在服务器端和客户端中都存在的类中,Actor类主要用来创建接口,base类主要用来创建基地并设置属性,bullet类主要用来创建子弹并设置属性,Ticker类主要用来创建时间信息,bomb类主要用来创建子弹打出后产生的爆炸效果,river类主要用来创建河道并设置属性,grass类主要负责创建草坪并设置属性,Steelwall类主要用来创建铁墙并设置属性,wall类主要用来创建和设置普通墙及其属性,level类负责创建关卡。如表1,表2所示。
表1 游戏服务器端各类功能表
ServerModel
创建主机
ServerView
设置服务器端图形界面的面板信息
ServerControler
处理来自服务器视图框架的输入
enemy
创建敌方坦克
player
设置玩家的得分及其显示位置等信息
drawingPanel
创建和设置服务器端界面窗口
powerUp
加快子弹速度并提升火力
feedbackHandler
判断指令并执行
Actor
创建接口
base
创建并设置基地
Ticker
创建并设置时间信息
bullet
创建子弹并设置属性
bomb
设置爆炸效果
river
创建河道并设置属性
grass
创建草坪并设置属性
Steelwall
创建铁墙并设置属性
wall
创建普通墙并设置属性
level
创建关卡
表2 游戏客户端各类功能表
ClientModel
设置与服务器的连接
ClientView
设置客户端端图形界面的面板信息
ClientControler
负责处理来自客户端视图框架的输入
drawingPanel
设置客户端窗口界面
instructionHandler
判断指令并执行
shield
设置玩家坦克防护盾
normalObject
创建并描绘其他的物体对象
level
创建关卡
base
创建并设置基地
Ticker
创建并设置时间信息
bullet
创建子弹并设置属性
bomb
设置爆炸效果
river
创建表SQL create table Student(sid varchar(10),sname varchar(10),sage datetime,ssex nvarchar(10)); insert into Student values('01' , '赵雷' , '1990-01-01' , '男'); insert into Student values('02' , '钱电' , '1990-12-21' , '男'); insert into Student values('03' , '孙风' , '1990-05-20' , '男'); insert into Student values('04' , '李云' , '1990-08-06' , '男'); insert into Student values('05' , '周梅' , '1991-12-01' , '女'); insert into Student values('06' , '吴兰' , '1992-03-01' , '女'); insert into Student values('07' , '郑竹' , '1989-07-01' , '女'); insert into Student values('08' , '王菊' , '1990-01-20' , '女'); create table Course(cid varchar(10),cname varchar(10),tid varchar(10)); insert into Course values('01' , '语文' , '02'); insert into Course values('02' , '数学' , '01'); insert into Course values('03' , '英语' , '03'); create table Teacher(tid varchar(10),tname varchar(10)); insert into Teacher values('01' , '张三'); insert into Teacher values('02' , '李四'); insert into Teacher values('03' , '王五'); create table SC(sid varchar(10),cid varchar(10),score decimal(18,1)); insert into SC values('01' , '01' , 80); insert into SC values('01' , '02' , 90); insert into SC values('01' , '03' , 99); insert into SC values('02' , '01' , 70); insert into SC values('02' , '02' , 60); insert into SC values('02' , '03' , 80); insert into SC values('03' , '01' , 80); insert into SC values('03' , '02' , 80); insert into SC values('03' , '03' , 80); insert into SC values('04' , '01' , 50); insert into SC values('04' , '02' , 30); insert into SC values('04' , '03' , 20); insert into SC values('05' , '01' , 76); insert into SC values('05' , '02' , 87); insert into SC values('06' , '01' , 31); insert into SC values('06' , '03' , 34); insert into SC values('07' , '02' , 89); insert into SC values('07' , '03' , 98); 表结构 学生表 Student
前言 现存其实已经有很多博客实现了这个代码,但是可能不完整或者不能直接用于测试集的指标计算,这里简单概括一下。
一些概念、代码参考: [1] 憨批的语义分割9——语义分割评价指标mIOU的计算
[2]【语义分割】评价指标:PA、CPA、MPA、IoU、MIoU详细总结和代码实现(零基础从入门到精通系列!)
[3] 【语义分割】评价指标总结及代码实现
混淆矩阵 语义分割的各种评价指标都是基于混淆矩阵来的。
对于一个只有背景0和目标1的语义分割任务来说,混淆矩阵可以简单理解为:
TP(1被认为是1)FP(0被认为是1)FN(1被认为是0)TN(0被认为是0) 各种指标的计算 1. 像素准确率 PA =(TP+TN)/(TP+TN+FP+FN)
2. 类别像素准确率 CPA = TP / (TP+FP)
3. 类别平均像素准确率 MPA = (CPA1+...+CPAn)/ n
4. 交并比 IoU = TP / (TP+FP+FN) 5. 平均交并比 MIoU = (IoU1+...+IoUn) / n
6. 频权交并比 FWIoU = [ (TP+FN) / (TP+FP+TN+FN) ] * [ TP / (TP + FP + FN) ]
代码实现 """ https://blog.csdn.net/sinat_29047129/article/details/103642140 https://www.cnblogs.com/Trevo/p/11795503.html refer to https://github.
一. 在javaEE项目中经常要判断一些字段的格式是否正确。在以前基本上都是用if(啥啥 啥)else(啥啥啥) 。但是在知道@Validated之后就开始尝试用这个注解了。不但减轻代码量而 且代码更加的易读规整。
二. 下面就以简单例子来说明。
Controller 层 @PostMapping("student") @ApiOperation("学生注册") public @ResponseBody Map<String, Object> registerStudent(@RequestBody @Validated UserJsonBean user, HttpServletRequest request) throws UnsupportedEncodingException, NoSuchAlgorithmException { Map<String,Object> retMap; retMap=registerService.baseRegister(user,0,request); return retMap; } 在要校验对象上加上@Validated注解
2.Bean层
(1) public class UserJsonBean extends User (2) public class User { @Id @Column(name="id",nullable = false) @GeneratedValue private Long id; @Email @Column(name = "user_email", nullable = false) private String userEmail; 3.测试
(1)传入数据
{ "emailCode": 1234, "phoneCode": "1234", "
目录
Class Sequential
Used in the guide:
Used in the tutorials:
__init__
Properties
layers
metrics_names
run_eagerly
sample_weights
state_updates
stateful
Methods
add
compile
evaluate
evaluate_generator
fit
fit_generator
get_layer
load_weights
pop
predict
predict_classes
predict_generator
predict_on_batch
predict_proba
reset_metrics
reset_states
save
save_weights
summary
test_on_batch
to_json
to_yaml
train_on_batch
Class Sequential Linear stack of layers.
Inherits From: Model
Aliases: tf.compat.v1.keras.Sequential, tf.compat.v1.keras.models.Sequential, tf.compat.v2.keras.Sequential, tf.compat.v2.keras.models.Sequential, tf.keras.models.Sequential
Used in the guide: Keras overviewMigrate your TensorFlow 1 code to TensorFlow 2Recurrent Neural Networks (RNN) with KerasDistributed training with TensorFlowEager execution Used in the tutorials: Overfit and underfitTime series forecastingConvolutional Variational AutoencoderDeep Convolutional Generative Adversarial NetworkPix2Pix Arguments:
文章目录 一、Docker 概述1.1 Docker 为什么出现1.2 Docker 的历史1.3 聊聊 Docker1.4 Docker 能干嘛 二、Docker 安装2.1 Docker 的基本组成2.2 安装 Docker2.3 阿里云镜像加速 一、Docker 概述 1.1 Docker 为什么出现 要解决的问题
一款产品: 开发 – 上线 两套环境! 应用环境, 应用配置!
开发 – 运维.
问题: 我在我的电脑上可以运行! 版本更新, 导致服务不可用! 对于运维来说, 考验就十分大!
环境配置十分的麻烦, 每一个机器都要部署环境(集群Redis、ES、Hadoop…)! 费时费力。
发布一个项目(jar + (Redis + MySQL jdk ES)), 项目能不能都带上环境安装打包!
之前在服务器配置一个应用的环境 Redis MySQL jdk ES Hadoop , 配置超麻烦, 不能够跨平台.
Windows, 最后发布到 Linux!
传统: 开发jar, 运维来做!
现在: 开发打包部署上线, 一套流程做完!
文章目录 26、请输入星期几的第一个字母来判断一下是星期几,如果第一个字母一样,则继续判断第二个字母。27、求100之内的素数。28、对10个数进行排序。29、求一个3*3矩阵对角线元素之和。30、有一个已经排好序的数组。现输入一个数,要求按原来的规律将它插入数组中。31、将一个数组逆序输出。32、取一个整数a从右端开始的4~7位。33、打印出杨辉三角形(要求打印出10行)34、输入3个数 a、b、c,按大小顺序输出。35、输入数组,最大的与第一个元素交换,最小的与最后一个元素交换,输出数组。36、有n个整数,使其前面各数顺序向后移m个位置,最后m个数变成最前面的m个数。37、有n个人围成一圈,顺序排号。从第一个人开始报数(从1到3报数),凡报到3的人退出圈子,问最后留下的是原来第几号的那位。38、写一个函数,求一个字符串的长度,在main函数中输入字符串,并输出其长度。39、编写一个函数,输入n为偶数时,调用函数求1/2+1/4+...+1/n,当输入n为奇数时,调用函数1/1+1/3+...+1/n。40、字符串排序。41、海滩上有一堆桃子,五只猴子来分。第一只猴子把这堆桃子凭据分为五份,多了一个,这只猴子把多的一个扔入海中,拿走了一份。第二只猴子把剩下的桃子又平均分成五份,又多了一个,它同样把多的一个扔入海中,拿走了一份,第三、第四、第五只猴子都是这样做的,问海滩上原来最少有多少个桃子?42、809*??=800*??+9*??,其中??代表的两位数,8*??的结果为两位数,9*??的结果为3位数。求??代表的两位数,及809*??后的结果。43、求0—7所能组成的奇数个数。44、一个偶数总能表示为两个素数之和。45、判断一个数能被几个9整除。46、两个字符串连接程序。47、读取7个数(1—50)的整数值,每读取一个值,程序打印出该值个数的*。48、某个公司采用公用电话传递数据,数据是四位的整数,在传递过程中是加密的,加密规则如下:每位数字都加上5,然后用和除以10的余数代替该数字,再将第一位和第四位交换,第二位和第三位交换。49、计算字符串中子串出现的次数。50、有五个学生,每个学生有3门课的成绩,从键盘输入以上数据(包括学生号,姓名,三门课成绩),计算出平均成绩,把原有的数据和计算出的平均分数存放在磁盘文件 "stud "中。 26、请输入星期几的第一个字母来判断一下是星期几,如果第一个字母一样,则继续判断第二个字母。 该题目指定用单个字符来进行日期的判断,而单个字符是可以当int型使用的,所以在此处用switch…case较为方便,示例代码如下:
private static String judgeWeek(char[] weeks){ String week=""; switch(weeks[0]){ case 'M': case 'm': week="Monday"; break; case 'T': case 't': if(weeks[1]=='u'||weeks[1]=='U') week="Tuesday"; else if(weeks[1]=='h'||weeks[1]=='H') week="Thursday"; break; case 'W': case 'w': week="Wednesday"; break; case 'F': case 'f': week="Friday"; break; case 'S': case 's': if(weeks[1]=='a'||weeks[1]=='A') week="Saturday"; else if(weeks[1]=='s'||weeks[1]=='U') week="Sunday"; break; } return week; } 27、求100之内的素数。 该题目的逻辑并不复杂,之前的题目中也有类似的,双层for循环,外层被除数,内层除数,遍历相除,输出筛选出来的值即可。此处说一下可能会采的坑。初版代码如下:
private static void printNum(int num){ boolean isPrint=true; for(int i=3;i<num;i++){ for(int j=2;j<=(int)Math.
创建表SQL create table Student(sid varchar(10),sname varchar(10),sage datetime,ssex nvarchar(10)); insert into Student values('01' , '赵雷' , '1990-01-01' , '男'); insert into Student values('02' , '钱电' , '1990-12-21' , '男'); insert into Student values('03' , '孙风' , '1990-05-20' , '男'); insert into Student values('04' , '李云' , '1990-08-06' , '男'); insert into Student values('05' , '周梅' , '1991-12-01' , '女'); insert into Student values('06' , '吴兰' , '1992-03-01' , '女'); insert into Student values('07' , '郑竹' , '1989-07-01' , '女'); insert into Student values('08' , '王菊' , '1990-01-20' , '女'); create table Course(cid varchar(10),cname varchar(10),tid varchar(10)); insert into Course values('01' , '语文' , '02'); insert into Course values('02' , '数学' , '01'); insert into Course values('03' , '英语' , '03'); create table Teacher(tid varchar(10),tname varchar(10)); insert into Teacher values('01' , '张三'); insert into Teacher values('02' , '李四'); insert into Teacher values('03' , '王五'); create table SC(sid varchar(10),cid varchar(10),score decimal(18,1)); insert into SC values('01' , '01' , 80); insert into SC values('01' , '02' , 90); insert into SC values('01' , '03' , 99); insert into SC values('02' , '01' , 70); insert into SC values('02' , '02' , 60); insert into SC values('02' , '03' , 80); insert into SC values('03' , '01' , 80); insert into SC values('03' , '02' , 80); insert into SC values('03' , '03' , 80); insert into SC values('04' , '01' , 50); insert into SC values('04' , '02' , 30); insert into SC values('04' , '03' , 20); insert into SC values('05' , '01' , 76); insert into SC values('05' , '02' , 87); insert into SC values('06' , '01' , 31); insert into SC values('06' , '03' , 34); insert into SC values('07' , '02' , 89); insert into SC values('07' , '03' , 98); 表结构 学生表 Student
一、实验目的
1. 掌握使用Wireshark分析俘获trace文件的基本技能;
2. 深刻理解IP报文结构和工作原理。
二、实验内容和要求
1. 分析俘获的分组;
2. 分析IP报文结构。
3. 记录每一字段的值,分析它的作用
三、实验环境
运行Windows10操作系统的PC一台。
PC具有以太网卡一块,通过双绞线与校园网相连;或者具有适合的踪迹文件。
运行程序协议分析仪Wireshark 3.6.3。
四、操作方法和实验具体步骤
分析俘获的分组
打开踪迹文件,选中编号15的分组,用鼠标指向其源地址,打开如图1所示菜单,点击“选中”,就会出现如图2所示的界面。可见,系统已经自动用其源地址作为过滤条件,从众多分组中过滤出与编号为15的分组有关分组了。更一般的定义条件,可选用“分析/显示过滤器”功能,如图三所示。
图1分组列表窗口的弹出菜单
图2以源地址作为条件进行过滤
图3显示过滤器
有时为了清晰可见,需要屏蔽较高层协议的细节,可以点击“分析/启动的协议”打开窗口,若除去选择IP,则将屏蔽IP相关信息。
(2)分析IP报文结构
将计算机联入网络,打开Wireshark俘获分组,从本机向选定的Web服务器发送Ping报文。(图4)选中其中一条Ping报文,该帧中的协议结构是:Ethernet:IP:ICMP:data。为了进一步分析IP数据报结构,点击首部细节信息栏中的“Internet Protocol”行,有关信息展开如图5,6首部信息窗口所示。
图4发送ping报文
图5
图6“Internet Protocol”详细信息
查看本机IP(图7),得到自己的计算机IP地址是:IP v4 192.168.43.32
图7查看IP
IP数据报(图 8)如下:
4500 020c 73b7 4000 3506 d8f5 7169 9a0d c0a8 2b20
图8 IP数据报
(1)版本:占4位,该IP数据报版本为4;
(2)首部长度:占4位,首部长度20个字节;
(3)区分服务:占8位,不区分服务;
(4)总长度:占16位,总长度524字节,其中首部20字节,数据504字节;
(5)标识:占16位,0x73b7,即29623;
(6)标志:占3位,目前只有两位有意义,DF=1,不能分片,MF=0,这已经是若干分片的最后一个;
(7)片偏移:占13位,该IP数据报片偏移为0;
(8)生存时间:占8位,TTL=53;
(9)首部检验和:占16位,该IP数据报首部检验和为0xd8f5,
(10)源地址:占32位,113.105.154.13;
(11)目的地址:占32位,192.168.43.32。
由上述信息我可以得到:
(1)我使用的计算机的IP地址是什么?
192.168.43.32
(2)在IP数据报首部,较高层协议字段中的值是什么?
1(ICMP)。
(3)IP首部有多少字节?载荷字段有多少字节
首部有20字节,载荷字段有40字节。
(4)该IP数据包分段了没有?如何判断该IP数据报有没有分段?
没有;片偏移为0则说明该IP数据报没有分段。
问题描述 启动服务器失败,报错信息如下:
Error: connect ECONNREFUSED 127.0.0.1:3306 at TCPConnectWrap.afterConnect [as oncomplete] (node:net:1157:16) --------------------
原因分析: 数据库名称不对: 解决方案: 1.打开后台数据库命名文件夹 config 找到数据库命名项
2.更改database项中命名.
3.重启控制器,重新连接数据库,
提示:这种情况要么是命名不对,要么是你的sql文件没有导入,建议检查!
目录
Class Model
Used in the guide:
Used in the tutorials:
__init__
Properties
layers
metrics_names
run_eagerly
sample_weights
state_updates
stateful
Methods
compile
evaluate
evaluate_generator
fit
fit_generator
get_layer
load_weights
predict
predict_generator
predict_on_batch
reset_metrics
reset_states
save
save_weights
summary
test_on_batch
to_json
to_yaml
train_on_batch
Class Model Model groups layers into an object with training and inference features.
Aliases: tf.compat.v1.keras.Model, tf.compat.v1.keras.models.Model, tf.compat.v2.keras.Model, tf.compat.v2.keras.models.Model, tf.keras.models.Model
Used in the guide: The Keras functional API in TensorFlowTrain and evaluate with KerasWriting custom layers and models with KerasSave and serialize models with KerasRecurrent Neural Networks (RNN) with Keras Used in the tutorials: Pix2PixImage segmentationDeepDreamNeural style transferLoad a pandas.
本期推荐开源项目目录:
1. App ideas
2. 中国程序员容易发音错误的单词
3. 新型冠状病毒数据库
4. 全新的构建 Web 界面的方法
5. Vite & Vue 支持的静态站点生成器。
6. 视频制作机器人
7. 50 天 50 个项目
8. 北京买房攻略
01 App ideas
这个项目是一个项目列表,该列表会根据开发者的水平提供一些练手项目,帮助你提升编程技巧。
这个开源项目可以帮助你:提高编程能力;助你尝试新技术;增加你的项目经验。这个列表中提到的小项目,易于完成,易于扩展。
这不仅是一个简单的列表,每个项目都描述的足够详细,有明确的描述性目标和应当实施的用户故事列表,以方便你从头开始进行开发。
开源地址:https://github.com/florinpop17/app-ideas
02 中国程序员容易发音错误的单词
本开源项目收集了技术栈相关的容易发音错误的单词。本着简单的原则,又为了避免程序猿们出现选择困难症, '正确音标'采用了最接近有道词典音频的英式 DJ 音标,,不代表其唯一性。
开源地址:https://github.com/shimohq/chinese-programmer-wrong-pronunciation
03 新型冠状病毒数据库
这是由约翰霍普金斯大学系统科学与工程中心 (JHU CSSE) 运营的 2019 年新型冠状病毒可视化仪表板的数据存储库。此外,由 ESRI Living Atlas 团队和约翰霍普金斯大学应用物理实验室 (JHU APL) 提供支持。
开源地址:https://github.com/CSSEGISandData/COVID-19
04 全新的构建 Web 界面的方法
Svelte 是一种全新的构建用户界面的方法。传统框架如 React 和 Vue 在浏览器中需要做大量的工作,而 Svelte 将这些工作放到构建应用程序的编译阶段来处理。
与使用虚拟(virtual)DOM 差异对比不同。Svelte 编写的代码在应用程序的状态更改时就能像做外科手术一样更新 DOM。
redhat7 安装telnet服务 1. 先检查是否安装了telnet 和 xinetd rpm -qa | grep telnet rpm -qa | grep xinetd 2. 安装telnet服务器 2.1 安装之前养成好习惯 ,先更新一下yum .
sudo yum update 2.2 安装
(a. 安装telent服务端)
yum -y install telnet-server.x86_64 (b. 安装telent客户端)
yum -y install telnet.x86_64 (c.安装telnet守护进程xinetd )
yum -y install xinetd.x86_64 3. 安装后检查 rpm -qa | grep telnet rpm -qa | grep xinetd 4. 安装完成后,设置开机自启动 # 设置开机自启动 sudo systemctl enable xinetd.service # 启动命令服务 sudo systemctl start telnet.
这里搭建的是squid代理服务器 Squid是一个高性能的代理缓存服务器,Squid支持FTP、gopher、HTTPS和HTTP协议。 服务器环境:服务器centos7.9、 redhat7.0
搭建环境:主机A(redhat7.0)不能上网,而同一网关内的主机B(centos7.9)可以上网。在主机B上搭建了squid代理服务器,方便主机A上网。
1、安装 1.1安装之前养成好习惯
sudo yum update 1.2 进行安装
yum install squid -y yum install httpd-tools -y 2、密码文件操作 2.1 生成密码文件
mkdir /etc/squid3/ # usernameNet 是用户名 htpasswd -cd /etc/squid3/passwords usernameNet # 提示输入密码,在这里我设的密码为 123456 # 注意密码不要超过8位 2.2 测试密码文件
/usr/lib64/squid/basic_ncsa_auth /etc/squid3/passwords # 输入 用户名 密码 usernameNet 123456 # 提示OK说明成功,ERR是有问题,请检查一下之前步骤 OK # 测试完成,crtl + c 打断 3、配置 vim /etc/squid/squid.conf # 在最后添加 auth_param basic program /usr/lib64/squid/basic_ncsa_auth /etc/squid3/passwords auth_param basic realm proxy acl authenticated proxy_auth REQUIRED http_access allow authenticated # 这里是端口号,可以按需修改 # http_port 3128 这样写会同时监听ipv6和ipv4的端口,推荐适应下面的配置方法。 http_port 0.
pytorch CrossEntropyloss使用方法(包括多维度) 官方文档给出的用法如下:
也就是说,在网络的output要把分类放在第二维,第二维后面的代表的是网络的维度,看起来非常简单,示例代码如下:
loss = nn.CrossEntropyLoss() input = torch.randn(9, 5, 2) target = torch.empty(9, 2, dtype = torch.long).random_(5) output = loss(input, target)
之前用windows时,一直使用Capslock+这个工具,关于这个工具可以参考我的这篇博客https://blog.csdn.net/qq_38048756/article/details/109263043
最近转到mac,虽然Capslock+对应有mac版capslox,前两个月免费,后面是需要付费的。
找了一圈终于找到了一个更强大的免费开源工具Karabiner Elements
这个工具比capslox还要强大,他支持自定义配置。
而且提供了很多人提供的一些定义好的配置,其中包括:基于karabiner实现替代capslox软件部分功能的配置
你只需要下载好Karabiner Elements,然后直接导入别人已定义好的capslox软件部分功能的配置,然后就可以直接使用了(需要注意的是:大小写切换为:capslock + Esc | 中英文切换:capslock+空格)。
如果你打算自定义复杂配置,可参考官网教程https://karabiner-elements.pqrs.org/docs/json/(注意from后面跟的改变后的key,to后面跟的是改变前的key)。
参考链接:
https://karabiner-elements.pqrs.org/docs/
https://github.com/yqchilde/capslox-karabiner
https://yqqy.top/capslox-karabiner/
https://blog.csdn.net/qq_26012495/article/details/88539120
在VMware中,有三种方式搭建虚拟服务器:桥接、nat和host-only。当选用"桥接"方式时,不仅当前机器(搭建虚拟机的机器)可以和虚拟机进通信,而且同一网段的其他电脑也可以和虚拟机进行通信。当选用"nat"方式时,仅当前机器能和虚拟机进行通信,并且当当前机器能够访问网络时,虚拟机也可以访问网络。当选用"host-only"时,仅当前机器能和虚拟机进行通信,并且当当前机器能够访问网络时,虚拟机不可以访问网络。
桥接 选用"桥接"方式,虚拟机会占用一个真实网卡,在同一多人环境下会发生ip冲突现象,但是使用桥接方式搭建服务器,可以和同一网段的其他电脑机箱通信。
修改配置
查看ip(无线网),在配置linux的网络配置文件中的虚拟机ip时,虚拟机ip必须和这个ip是同一网段的。
修改linux的ip地址
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33 [root@localhost ~]# systemctl restart network #追加如下内容 IPADDR=192.168.0.128 NETMASK=255.255.255.0 GATEWAY=192.168.0.1 DNS1=8.8.8.8 nat 修改配置
修改ip地址
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33 [root@localhost ~]# systemctl restart network IPADDR=192.168.163.128 NETMASK=255.255.255.0 GATEWAY=192.168.163.2 DNS1=8.8.8.8 host-only 修改配置
修改ip
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33 [root@localhost ~]# systemctl restart network IPADDR=192.168.184.128 NETMASK=255.255.255.0 GATEWAY=192.168.184.2 DNS1=8.8.8.8
vue-cookies过期时间设置无效 最近项目用到了vue-cookies,用是挺好用的,但是在设置过期时间时让我傻了眼,因为我按照之前网上的设置过期时间的方法,完全没用,不管怎么样设置他都是会话内生效。
搞得我直接人麻掉,因为我是想让它存在个两三天的,这肯定不行,我的设置方法是按照网上的说的这样设的:
或者把后面的D改成小写,改成什么day啥的,都试过,完全没用。后来我无意间发现了一个可以用的设置,改了之后果然生效了,大家可以试一下。
后面的数字表示过期时间,60就是一分钟,246060就是一天,246060*7就是7天。
大家如果也遇到了vue-cookie过期时间设置无效的情况可以试试,万一有用呢。