MyBatis特性 MyBatis 是支持定制化 SQL、存储过程以及高级映射的优秀的持久层框架MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集MyBatis可以使用简单的XML或注解用于配置和原始映射,将接口和Java的POJO(Plain Old Java Objects,普通的Java对象)映射成数据库中的记录MyBatis 是一个 半自动的ORM(Object Relation Mapping)框架-下面有解释 搭建MyBatis 1.在pom.xml种将打包方式写成 <packaging>jar</packaging> 2.引入依赖 <dependencies> <!-- Mybatis核心 --> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.5.7</version> </dependency> <!-- junit测试 --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency> <!-- MySQL驱动 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.16</version> </dependency> <!-- 日志--> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> </dependencies> 3.创建mybatis-config.xml-核心配置文件 核心配置文件中的标签必须按照固定的顺序(有的标签可以不写,但顺序一定不能乱):
properties、settings、typeAliases、typeHandlers、objectFactory、objectWrapperFactory、reflectorFactory、plugins、environments、databaseIdProvider、mappers
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <!--引入properties文件,此时就可以${属性名}的方式访问属性值--> <properties resource="
今天我们来聊聊MySQL原理
基础篇主要是侧重基础知识,原理篇是有一定基础后的递进,通过学习本篇,不仅可以进一步了解MySQL的各项特性,还能为接下来的容灾调优打下坚实的基础。
现在,就让我们继续跟随阿柴进行这场沉浸式面试吧。
ACID与隔离级别
那你先来说说MySQL的四种隔离级别吧。
SQL标准定义了4类隔离级别,包括一些具体规则,用来限定事务之间的隔离性。
这四种级别分别是读未提交、读已提交、可重复读、串型化。
读未提交,顾名思义,就是可以读到还没有提交的数据;读已提交会读到其它事务已经提交的数据;可重复读确保了同一事务中,读取同一条数据时,会看到同样的数据行;串型化通过强制事务排序,使其不可能相互冲突。
重点介绍下Repeatable Read吧。
Repeatable Read就是可重复读。它确保了在同一事务中,读取同一条数据时,会看到同样的数据行。
它也是MyQL的默认事务隔离级别,这种级别事务之间影响很小,通常已经能够满足日常需要了。
说出四种隔离级别只是最低要求,能每一项具体去阐述特性就算过关。如果还能指出存在的问题、依赖的技术,那么就是妥妥的加分了!
下面我们来聊聊InnoDB中ACID的实现吧,先说一下原子性是怎么实现的。
事务要么失败,要么成功,不能做一半。聪明的InnoDB,在干活儿之前,先将要做的事情记录到一个叫undo log的日志文件中,如果失败了或者主动rollback,就可以通过undo log的内容,将事务回滚。
那undo log里面具体记录了什么信息呢?
undo log属于逻辑日志,它记录的是sql执行相关的信息。当发生回滚时,InnoDB会根据undo log的内容做与之前相反的工作,使数据回到之前的状态。。。
那持久性又是怎么实现的?
持久性是用来保证一旦给客户返回成功,数据就不会消失,持久存在。最简单的做法,是每次写完磁盘落地之后,再给客户返回成功。但如果每次读写数据都需要磁盘IO,效率就会很低。
为此,追求极致的InnoDB提供了缓冲。当向数据库写入数据时,会首先写入缓冲池,缓冲池中修改的数据会定期刷新到磁盘中,这一过程称为刷脏。
如果MySQL宕机,那此时Buffer Pool中修改的数据不是丢失了吗?
Innodb引入了redo log来解决这个问题。当数据修改时,会先在redo log记录这次操作,然后再修改缓冲池中的数据,当事务提交时,会调用fsync接口对redo log进行刷盘。
如果MySQL宕机,重启时可以读取redo log中的数据,对数据库进行恢复。由于redo log是WAL日志,也就是预写式日志,所有修改先写入日志,所以保证了数据不会因MySQL宕机而丢失,从而满足了持久性要求。
按你所说,redo log 也需要写磁盘,为什么不直接将数据写磁盘呢?
嗯。。。主要是有以下两方面的原因:
1.对Buffer Pool进行刷脏是随机IO,因为每次修改的数据位置随机,但写redo log是追加操作,属于顺序IO;
2.刷脏是以数据页为单位,MySQL默认页大小是16KB,一个Page上一个小修改都要整页写入,所以积累一些数据一并写入会大大提升性能;而redo log中只包含真正需要写入的部分,无效IO比较少。
redo log是持久性的核心,WAL的思路也是持久化的常见解决方式,只有先落地了,才能应对后续的各种异常。
那隔离性怎么实现呢?
MySQL能支持Repeatable Read这种高隔离级别,主要是锁和MVCC一起努力的结果。
我先说锁吧。事务在读取某数据的瞬间,必须先对其加行级共享锁,直到事务结束才释放;事务在更新某数据的瞬间,必须先对其加行级排他锁,直到事务结束才释放;
为了防止幻读,还会有间隙锁进行区间排它锁定。
然后是MVCC,多版本并发控制,主要是为了实现可重复读,虽然锁也可以,但是为了更高性能考虑,使用了这种多版本快照的方式。
因为是快照,所以一个事务针对同一条Sql查询语句的结果,不会受其它事务影响。
索引原理
索引的底层实现是什么?
用的B+树,它是一个N叉排序树,每个节点通常有多个子节点。节点种类有普通节点和叶子节点。根节点可能是一个叶子节点, 也可能是个普通节点。
B+树
那MySQL为什么用树做索引?
一般而言,能做索引的,要么Hash,要么树,要么就是比较特殊的跳表。Hash不支持范围查询,跳表不适合这种磁盘场景,而树支持范围查询,且多种多样,很多树适合磁盘存储。所以MySQL选择了树来做索引。
那你能说说为什么是B+树,而不是平衡二叉树、红黑树或者B-树吗?
平衡二叉树追求绝对平衡,条件比较苛刻,实现起来比较麻烦,每次插入新节点之后需要旋转的次数不能预知。
同时,B+树优势在于每个节点能存储多个信息,这样深度比平衡二叉树会浅很多,减少数据查找的次数。
平衡二叉树
红黑树放弃了追求完全平衡,只追求大致平衡,在与平衡二叉树的时间复杂度相差不大的情况下,保证每次插入最多只需要三次旋转就能达到平衡,实现起来也更为简单。
但是红黑树多用于内部排序,即全放在内存中,而B+树多用于外存上时,B+也被称为一个磁盘友好的数据结构。
同时,红黑树和平衡二叉树有相同缺点,即每个节点存储一个关键词,数据量大时,导致它们的深度很深,MySQL每次读取时都会消耗大量IO。
红黑树
那B+树相比B-树有什么优点呢?
http协议是无状态的,在很多场景下往往需要保持会话状态,因此cookie和session应运而生。
cookie cookie的内容就是保存的一小段文本信息,这些文本信息组成了一个通行证。
存在本地的Cookies实际上是一个sqlite数据库文件
key-value的数据:
● name:cookie的名称
● value:cookie的值
● max-age:生存周期,max-age用秒来设置cookie的生存期
max-age属性为正数,则表示该cookie会在max-age秒之后自动失效max-age为负数,则表示该cookie仅在本浏览器窗口以及本窗口打开的子窗口内有效,关闭窗口后该cookie即失效。max-age为0,则表示删除该cookie ● domain:Cookie 所属的域 path:Cookie 来源的网址路径
● secure:该Cookie是否仅被使用于安全协议传输。安全协议有HTTPS,SSL等,在网络上传输数据之前先将数据加密。
● httponly:指示 Cookie 应仅由浏览器在 HTTP 请求中设置,而无法通过 JavaScript 访问。
以自动填充用户名和密码登录为例介绍cookie:
当我们登录某个网站时,在输入账号和密码之后,当勾选记住密码,点击登录后,浏览器会将表单上的数据作为登录请求的内容发送到服务器,服务器接收到登录请求后,会对记住密码判断是否勾选,如果勾选,就会设置set-cookie字段(里面是一些键值对),然后在响应的头部中放入该字段,然后返回给浏览器。浏览器在接收到响应之后,会查看是否有set-cookie信息,如果有,就会将服务器发挥的cookie信息存储起来。
当用户再次打开此登录页面时,浏览器发送获取登录页面的http请求,此时会将cookie放到请求的头部。服务器端接收到请求后(另外,登录后发送其他请求时由于会将cookie一起发送到服务器,服务器可以通过分析cookie中的内容,得到客户端的特有信息,比如:知道用户名)返回登录的页面http响应,浏览器加载并渲染该登录页面,登录页面中的js代码会检查并获取到cookie中的登录信息,如果当前的cookie在有效期内,便会提取到账号密码填入到表单中,此时便完成了自动填充账号密码。
关于cookie的生存周期
cookie并不是关闭浏览器后就会自动清除,它的生存周期可以通过查看cookie的maxAge属性获得,如果该属性值为session,表示和session一起失效。
cookie不可以跨域名、跨浏览器使用,这是其隐私安全机制决定的。因此你在一个网站记住的账号密码,在另一个其他网站是不可以使用的,即使二者完全一样。
session session的原理 cookie虽然可以记录会话状态,但是由于其存储在客户端,用户是可见的,并且可以随意地修改,其安全性无法得到保证。而session是存储在服务端的,其安全性更高。
session的工作原理如下:
服务器程序运行的过程中产生session,并且为该session生成唯一的session ID 这个session ID在随后的请求中会被用来重新获得已经创建的session。在session创建后,就可以调用session相关的方法向session中增加内容,这些内容只会保存在服务器中。 服务器将session ID发送给客户端客户端再次发送请求时,会将这个session ID带上服务器接收到请求之后,根据session ID找到相应的session,完成请求响应。 session的传输媒介 第一种方式:通过cookie传输
session的信息保存在服务器端,但是它对客户端是透明的,他的正常运行需要客户端浏览器的支持,因为session需要使用cookie作为识别标志。服务器会向客户端发送一个关于session的cookie,它的值为该session的ID。后续客户端发送消息时,只需要在cookie中带上这个session ID即可。
第二种方式:通过URL地址重写
如果客户端浏览器禁用cookie或者不支持cookie,此时对于session的传输方法就需要利用URL地址重写。
它的原理是将该用户的session ID信息重写到URL地址中,服务区能够解析重写后的URL,获得session的ID,这样即使客户端不支持cookie,也可以使用session来记录用户状态。
session的生存周期问题:
session的生存周期可以通过cookie中的session ID的expire字段来查看,如果该值为-1表示只要关闭该窗口,session就会失效。
二者的区别 ● 存储位置不同
○ session存储在服务器端,cookie存储在浏览器端
● 生命周期不同
○ session依赖于jessonid的cookie,它的过期时间默认为-1,只要关闭窗口该session就会失效。session不能达到长期有效的效果,即使利用url重写也不行,因为如果session设置的超时时间过长,服务器累计的session过多,会导致内存溢出。服务器会把长时间没有活动的Session从服务器内存中清除,此时Session便失效(可以人为设置)
○ cookie也可以预先设置生命周期,或者是永久的保存在本地文件中存储内容的
○ 服务器如何设置cookie失效,通过在返回的响应中设置cookie的失效时间
1、写题:全排列(有重复的元素);
2、介绍项目经历(技术栈、框架、实现了什么功能);
3、登录、鉴权、权限控制前台架构(用什么存了用户的信息,怎么去拦截的,怎么进行权限校验的);
4、路由守卫;
5、通过axios怎样封装接口;
6、什么情况下用post接口、什么情况下用get接口;
7、在项目中webpack的配置有什么(vue.config.js还是web pack.js);
8、loader和plugin的区别(loader(编译压缩)plugin插件(比较复杂的事件监听));
9、JS的编程规范(ES6 复杂高级的一些写法);
10、var、const、let的区别;
11、异步的发展历程:自己的理解(回调函数、promise、async await);
12、浏览器输入一个url会发生什么;
13、资源文件的加载顺序(html、css、js、图片等):先加载index.html,查询依赖的css文件、js文件,再加载js import的文件;
14、白屏优化;
15、虚拟dom机制(有dom更新才会刷新);
16、项目中遇到的一些比较难的问题的总结;
17、数组树形化应不应该前端来做
每日一问02 Question:在训练过程中,若一个模型不收敛,是否说明这个模型无效?导致模型不收敛的原因有哪些? 在训练过程中,如果模型不收敛并不能说明该模型时无效的。
导致模型不收敛的原因包括:
1. 没有对数据做归一化处理。
2. 没有使用正则化。
3.Batch Size设的太大
4.学习率设置的太大容易产生震荡,太小会导致不收敛。
5.没有做数据预处理。
6.没有检查过预处理结果和最终的训练测试结果。
7.网络存在坏梯度,比如当Relu对负值的梯度为0,反向传播时,梯度为0表示不传播。
8.网络设定不合理,网络太浅或者太深。
9.最后一层的激活函数错误。
10.参数初始化错误。
11.隐藏层神经元数量错误。
12.数据集标签的设置有错误。
【OpenCV(C++)】查找并绘制图像轮廓 寻找轮廓:findContours()函数绘制轮廓:drawContours()函数基础轮廓查找查找并绘制轮廓 一个轮廓一般对应一系列点,也就是图像中的一条曲线。其表示方法可能根据不同的情况而有所不同。
寻找轮廓:findContours()函数 findContours()函数用于在二值函数中寻找轮廓。
void findContours( InputOutputArray image, OutputArrayOfArrarys contours, OutputArray hierarchy, int mode, int method, Point offset=Point() ); 绘制轮廓:drawContours()函数 drawContours()函数用于在图像中绘制外部或内部轮廓。
void drawContours( InputOutputArray image, InputArrayOfArrays contours, int contourIdx, const Scalar& color, int thickness=1, int lineType=8, InputArray hierarchy = noArray(), int maxLevel = INT_MAX, Point offset = Point() ); 基础轮廓查找 #include <opencv2/opencv.hpp> #include <opencv2/highgui/highgui.hpp> #include <opencv2/imgproc/imgproc.hpp> using namespace cv; using namespace std; int main(int argc, char** argv) { Mat srcImage = imread("
文章目录 现象排查原因总结 现象 通过直接访问pod 可以访问通,通过clusterip&nodeport 两种方式都不通
排查 这是正常的service,serivce 能够映射到具体的pod,有问题的时候,endpoints为空,所以service 一直不通
原因 这种肯定是service的配置不对,没能通过label,映射到具体的pod
发现service 这里配置的不对
selector:
app: spring-java-demo
总结 网上有各种各样的答案,需要自己静下心来慢慢分析原因。这种不是随便都能找到答案的。
目录
3D立体图形
3D绘图
3D散点图
3D曲线图
3D平面图
3D立体图形 绘制三维图像主要通过 mplot3d 模块实现。
from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D %matplotlib notebook 3D绘图 3D绘图与2D绘图使用的方法基本一致,不同的是,操作的对象变为了 Axes3D() 对象。
3D散点图 from matplotlib import pyplot as plt import numpy as np from mpl_toolkits.mplot3d import Axes3D x = np.random.rand(100) y = np.random.rand(100) z = np.random.rand(100) fig = plt.figure() ax = Axes3D(fig) ax.scatter(x,y,z,s=10,color="r",marker='o') plt.show() 3D曲线图 from matplotlib import pyplot as plt import numpy as np from mpl_toolkits.
针对android 11即使有了读取手机状态权限,使用反射依然获取不到IMEI,关键是还需要一项权限READ_PRIVILEGED_PHONE_STATE,这项权限没有获取途径,只能改系统。
文件路径
alps/frameworks/base/telephony/common/com/android/internal/telephony/TelephonyPermissions.java
checkPrivilegedReadPermissionOrCarrierPrivilegePermission 函数中添加指定app可读取IMEI
if(callingPackage.equals("com.xxx.xxx")){
return true;
}
或者开放权限所有APP都可能读取
if(1==1)
return true;
差分对与差分阻抗(二)
1.实际耦合影响
当我们把两条带状线靠得很近时,它们的边缘电场和磁场就会互相覆盖之间的耦合强度也会很强。由电容和电感矩阵元素描述的耦合与所加电压完全无关,它只与导线的几何结构和材料特性有关。两条信号线的间距越小,他们之间的耦合就越强。
2.当两条信号线距离非常近时,邻近信号线的存在将会影响线1的阻抗称为接近效应。
(1)两条信号线由方向相反的两个信号跳变驱动,电流从驱动器流进信号线1,然后流向返回路径,当两条信号线靠近时,为了驱动单端信号线更大的电容,这个电流将会增大。如果所加电压没有变化而电流增加,则对驱动器而言,意味着输入阻抗减小。当给第二条信号线加上相反的信号,第一条信号线的单端特性阻抗会减小;
(2)假设给第二条信号线加上与第一条信号相同的信号,只有电容C11存在,这就意味着要驱动的电容减小了。此时流经信号线1的电流为:
3.我们发现,当有第二条临近信号线存在时,信号线1的特性阻抗不是一个特定的值,它还取决于邻近信号线被驱动的情况。
(1)如果信号线2被固定在0电位,则阻抗值接近于未耦合时的值;
(2)如果信号线2加相反信号,阻抗值就会降低;
(3)如果信号线2加相同信号,阻抗值就会升高。
差分信号在这两条信号上分别驱动两个相反的信号。正如前面所讨论的,此时每条信号线的阻抗会因为彼此之间的耦合而减小。
4.只处理单端信号,一条传输线仅用一个阻抗描述。但是当他是一对线中的一个且存在耦合时,需要用3种不同阻抗加以描述。
当两条信号线的间距逐渐减小时,差分阻抗的变化情况,对带状线而言,相比于线间距等于3倍线宽的无耦合情况,在可制造的最小间距(如线间距等于线宽)下,存在耦合时的差分阻抗也仅仅减小了12%。
5.五种分析计算差分阻值的变化
(1)直接使用近似式的结果;
(2)直接使用场求解器的结果;
(3)采用基于模态的分析;
(4)采用基于电容和电感矩阵的分析;
(5)采用基于阻抗矩阵的分析。
近似式:微带线差分阻抗的近似式:
耦合带状线,差分阻抗近似为:
准确场求解器计算:这里,近似算法先要借用场求解器给出的单端特性阻抗,再用近似就能预估出耦合对差分阻抗产生的轻微影响。只要给出特性阻抗初始值是正确的,这种近似误差在1%~10%之间。
运用场求解器的一个优势在于:在很多种几何结构中,基于此方法的一些计算工具的误差在1%以下。当准确度要求比较严格时,比较交付制造使用PCB版图的签发,这时唯一能够用的工具就是核验过的二维场求解器。绝对不能将近似式运用到设计签发当中。
6.一条信号线上的差分信号的返回电流由另一条信号线运送,等量电流从一条信号线流入,再从另一条信号线流出,这的确是事实,但并不是事实的全部。
因为这里差分对的两条信号线的线间距比较大,所以当用差分信号驱动时,返回平面中的电流不出现重叠。此时返回路径平面的总电流为0,但每条信号线下的平面中都有确定的局部电流分布,任何改变电流分布的因素都将会改变差分对的差分阻抗。
7.当差分对的信号线与返回路径平面之间的耦合程度大于两条信号之间的耦合时,返回路径平面中就会出现两路不同的相互分离的电流,并且返回路径电流分布只出现微小的重叠,返回路径电流分布严重制约差分对的差分阻抗,返回路径电流分布的扰动直接影响到差分阻抗。
8.对于任何一对公用返回导体的单端传输线而言,如果返回导体距信号走线足够远,差分信号的返回导体电流分布就相互重叠,并完全抵消掉。此时返回路径导体的存在对差分阻抗产生不了任何影响。这种特定的条件下,第一条信号线上的返回电流将完全可能由另一条信号线运送,有以下3种需要关注。
(1)边缘耦合微带线,返回平面足够远;
(2)双绞线电缆;
(3)宽边耦合带状线,返回平面足够远。
9.当信号线阻抗约为50Ω,线间距最小时,返回平面中有明显的电流分布,平面的存在将影响差分阻抗。如果将平面移到更远处,那么每条线的单端阻抗将会增加,差分阻抗也将会增加。然而,随着平面越移越远,差分信号的返回电流在平面中的重叠程度也就更大。
10.根据经验法则,当信号线与返回路径平面之间的距离大于等于两条信号线外边缘之间的跨度时,返回路径平面内的电流相互重叠,返回路径平面的存在对信号线的差分阻抗没有影响,此时对差分信号而言,一条信号线的返回电流完全可以看成由另一条信号线运送。
11.(1)当信号线与返回平面之间的耦合度大于两条信号之间的耦合度时,返回路径中出现明显的返回电流,平面在确定差分对差分阻抗时起到了重要作用;
(2)当两条信号线之间的耦合度远大于信号与返回平面之间的耦合度时,平面中的大部分返回电流会叠加抵消掉,平面不影响差分信号,将它移走也不影响到差分阻抗。
12.经验法则,要使两条信号线之间的耦合度大于信号信号线与返回平面之间的耦合度,则信号线与最近平面之间的距离必须大于两条信号线间距的2倍。
前言 这是我自己在学习c语言基础后,产生兴趣想继续深入学习,故开篇文章来记录一下,这段时光,这个最坏的时光,也是最好的时光。
关键字 c语言标准定义的32个关键字 关键字 意义
auto 声明自动变量,缺省时编译器一般默认auto
int 声明整形变量
double 声明双精度变量
long 声明长整型变量
char 声明字符型变量
float 声明浮点型变量
short 声明短整型变量
signed 声明有符号类型变量
unsigned 声明无符号类型变量
struct 声明结构体变量
union 声明联合体数据类型
enum 声明枚举类型
static 声明静态变量
switch 用于开关语句
case 开关语句分支
default 开关语句中的“其他”分支
break 跳出当前循环
register 声明寄存器变量
const 声明只读变量
volatile 说明变量在程序执行中可被隐含的改变
typedef 主要用以给数据类型取别名
extern 声明变量是在其他文件中声明
return 子程序返回语句(可以带参数,也可以不带参数)
void 声明函数无返回值或无参数,声明空类型指针
continue 结束当前循环,开始下一轮循环
do 循环语句的循环体
while 循环语句的循环条件
if 条件语句
else 条件语句否定分支(与if连用)
for 一种循环体
goto 无条件跳转语句
sizeof 计算对象所占内存空间大小
欢迎大家去我的个人网站踩踩 点这里哦 一、前言 最近项目做安全测试,发现存在XSS攻击的可能,于是乎上网找找看,找了很多基本都是继承HttpServletRequestWrapper,对getParam、getQueryString等获取参数的方法进行重写,对参数进行html转义,马上找一个加上试了试,可是发现保存的对象还是没有转义的,后来才想到项目是前后端分离,基本都是@RequestBody注解接收application/json格式参数,通过以上方法是获取不到参数的。
二、网上大多数的解决方案 XssHttpServletRequestWrapper、XssFilter
package com.mukanyun.common.extension; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletRequestWrapper; import org.apache.commons.lang3.ArrayUtils; import org.apache.commons.text.StringEscapeUtils; public class XssHttpServletRequestWrapper extends HttpServletRequestWrapper { public XssHttpServletRequestWrapper(HttpServletRequest request) { super(request); } @Override public String getQueryString() { return StringEscapeUtils.escapeHtml4(super.getQueryString()); } @Override public String getParameter(String name) { return StringEscapeUtils.escapeHtml4(super.getParameter(name)); } @Override public String[] getParameterValues(String name) { String[] values = super.getParameterValues(name); if (ArrayUtils.isEmpty(values)) { return values; } int length = values.length; String[] escapeValues = new String[length]; for (int i = 0; i < length; i++) { escapeValues[i] = StringEscapeUtils.
法一
在Anaconda里安装一个插件(在虚拟环境下)。
conda install nb_conda 然后启动Jupyter notebook即可
参考https://www.jianshu.com/p/afea092dda1d
法二
先激活想要添加的虚拟环境
然后
pip install ipykernel ipython 安装成功后
ipython kernel install --user --name pytorch1.6 注意:pytorch1.6是自己的虚拟环境名,大家按照自己的更改
输入命令之后,敲回车,会出现
Installed kernelspec pytorch1.6 in C:\Users\Sir\AppData\Roaming\jupyter\kernels\pytorch1.6 即表示添加虚拟环境成功。
打开Jupyter notebook,会看到原本只有Python3的地方,多了一个虚拟环境,添加成功啦啦。
如果大家以后想把已经添加成功的虚拟环境删除,可以先激活想要删除的虚拟环境
然后输入:
jupyter kernelspec remove pytorch1.6 终端处输入:Y — 表示同意删除,即可成功删除添加的虚拟环境
参考https://zhuanlan.zhihu.com/p/409063952
通常的柱状图 渐变色非的简单
series: [ { type: 'bar', data: this.rank.num, barWidth: '10%', itemStyle: { color: { type: 'linear', x: 0, y: 0, x2: 0, y2: 1, colorStops: [{ offset: 0, color: '##00BFFF' // 0% 处的颜色 }, { offset: 1, color: '#54FF9F' // 100% 处的颜色 }], global: false // 缺省为 false } } } ] 横向的图表却不能照搬 因为渐变还是自下而上的就像这样:
在横向的图表中我们希望渐变是从左到右的
这种效果只需要改一下color的配置
```javascript series: [ { type: 'bar', barWidth: 12, data: this.justice.num, itemStyle: { barBorderRadius: [0, 20, 20, 0], color: new this.
差分对与差分阻抗(一)
1.差分对是指存在耦合的一对传输线。
差分信令是用两个输出驱动器去驱动两条独立的传输线,所测量的信号是两条线之间的差。差分信令与单端信令相比有许多优点:
(1)双驱动器产生的di/dt比单端驱动器时的大幅降低,从而减小了地弹,轨道塌陷和潜在的EMI。
(2)与单端放大器相比,接收器中的差分放大器可以有更高的增益;
(3)差分信号在一对紧耦合差分对中传播,其串扰较小,应对差分对的两条传输线公共返回路径中的突变的稳健性也比较好。
(4)差分信号通过连接器或封装时,不易受到地弹和开关噪声的干扰。
(5)使用价格低廉的双绞线即可实现较远距离的差分信号的传输。
缺点:
(1)会产生潜在的电磁干扰,存在共摸分量等;
(2)与单端传输信号相比,传输线差分信号需要两倍数量的信号;
(3)要理解许多新原理和重要的设计原则。
2.当两路驱动器驱动一个差分对时,除了各自的单端信号,这两路信号之间还存在一个电压差,这样的信号称为差分信号。
Vdiff=V1-V2
3.共摸信号定义:两条信号线上你给的平均电压表示:
4.这些有关差分信号和共摸信号的定义适用于所有的信号,任何加在一对传输线上的任意信号都可用差分分量和共摸分量去描述,并且这种描述方法是完整和唯一的。给出差分信号和共摸信号分量,每条信号与返回路径之间的单端信号电压可表示为:
5.在理想情况下,通常认为共模信号是恒定不变的直流。共摸信号通常不携带信息,因此也不会影响信号完整性和系统性能。
但是在实际电路互连物理过程中,共摸分量的改变将会潜在地引起如下两个十分重要的问题:
(1)如果共摸信号电压过高,就会使差分接收器的输入放大器饱和,使之不能准确的读入差分信号。
(2)如果在同轴线缆中的有变化的共摸信号,就会潜在地引起过量的EMI。
6.差分和共摸这两个术语总是并且只是指信号的特性,而不是指令传输线差分对的性质。
7.构成差分对只需要两条传输线就足够了,每条线都可以是简单地单端传输线,这两条线合在一起就称为一个差分对,常见的差分对外形截面:
(1)差分对最重要的是,它的横截面积恒定不变,而且使差分信号有一个恒定的阻抗;
(2)差分对第二个重要性质,每条线上的时延是相同的,从而确保了差分信号边沿的陡峭;
(3)两条传输线应该完全相同,线宽和两条线之间的介质间距也该完全相同;
(4)传输线的长度也必须完全相同,就能保证传输线上的时延相同。
(5)差分对的两条传输线之间不一定有耦合,但没有耦合将导致差分对的抗噪声能力下降。
8.差分信号感受到的阻抗,即差分阻抗,是差分信号的电压与其电流的比值,差分对最重要的电特性就是对差分信号的阻抗,称为差分阻抗。
9.流经信号线与返回路径之间的电流为
差分阻抗大小是单端信号特性阻抗的2倍,因为两条信号线之间的电压是每条信号线自身电压的2倍,而流经差分信号线的电流却与流经单端信号线的相同,如果单端信号的特性阻抗是50Ω,差分阻抗就是2*100Ω。
10.出现振铃的原因就在于差分信号在低阻抗的驱动器和高阻抗的线末端之间出现了多次反弹。消除反射的一种方法是在两条信号线的末端跨接一个端接电阻,去匹配差分阻抗,这个电阻器的阻值必须为:Rterm=Zdiff=2*Z0.
两条信号线之间的等效阻抗(差分阻抗)是串联阻抗,即Zdiff=Z0+Z0=2*Z0(不考虑耦合的情况下)。
1.电脑安装软件
2.点击确定
3.下一步
4.下一步
5.下一步
6.下一步
7.下一步
8.等待安装完成
9.等待
10.完成安装
11.打开 ST Visual Programmer
12.选择芯片
13.选择芯片类型(STM8L051x3)【我自己刷的是这个芯片,其他芯片可以自己在里面搜索】
14.打开文件
15.找到固件文件【一般尾缀是.hex,我的是自己的】
16.打开
17.进行硬件连接,电脑USB terminal与ST-LINK USB terminal 连接【注意:你烧录的模块记得通电,很多人没把设备通电就刷,会报错的,显示是连接失败(cannot communicate with the devices)】
18.设备连接如下图: 19.点击箭头的按钮进行烧录即可
20.完成烧录,将ST-LINK连接去除,设备即可使用。
21.如果烧录报错,检查文件名称是否正确,下图是可以看到文件名称【我这里是door_sensor_433_77(2).hex】
22.如果烧录报错,检查ST-Link是否是烧录的黄色灯,如果是黄色灯,可能是之前你烧录过,还没断开连接,解决方法是:将ST-Link与电脑USB口重新断开,再插入,即可解决!
23.注意:每次烧录尽量关闭软件后重新打开,这样保证不会刷错到以前的程序!
如何手动创建Spring的applicationContext.xml配置文件 1、新建一个web工程,File—>New—>Dynamic Web Project,起名,连续两个Next后,勾选Generate web.xml deployment descriptor(这一步忘了勾选也没关系,是用来自动生成web.xml文件的,可以后期补。)
2、找到src,右键New—>Other,
输入spring,找到Spring Bean Configuration File,Next
输入名称applicationContext.xml【该配置文件名称可以自定义,但通常在实际开发中,都会将配置文件命名为applicationContext.xml(有时也会命名为beans.xml)】,Finish。
我是因为已经创建了一个applicationContext.xml,所以图片里我写的是applicationContext1.xml,不然Finish是灰色的不好截图。
最终效果:
同时你的工程文件也会由一个普通工程转变为Spring工程,图标的右上角J->S(在第一步你新建web工程后右上角最初是J,没观察到的话你可以再新建一个观察一下,图中chapter_02就是为了我方便对比新建的没有配置applicationContext.xml文件的普通工程)。
END(后为无意义内容)
整理这一部分主要是自己困惑过,自己在大学里学习Spring时就晕头转向,配置文件这一块书上并没有详细操作,只有学的时候跟着老师操作过一次,之后都是复制工程直接改,在毕业设计时想要手动创建却不记得选哪一个选项了,查了百度,感觉最普遍的一个答案明显跟自己记忆中不符,最终放弃,依然是复制的之前的工程。今天去找了B站的Spring视频,试了一下发现步骤是对的,整理在这里,希望能帮到其他跟我一样的小白。
第二个就是也曾经百度过如何让Java工程右上角的J变成S,最后得到的只有把工程文件变成Spring文件就可以这样很随便的答案(废话啊!我就是想知道怎么变成Spring文件啊!是谁让这么白痴的答案上榜的!),所以百度也不一定靠谱。
目录
一.Matplotlib介绍安装
Matplotlib介绍
作用
Matplotlib安装
二.使用Matplotlib绘制基本图形 1.折线图
折线图绘制
折线图特点
2.plt基本方法——图形的基本设置
方法
中文显示问题及负数显示
使用Jupyter的plt.show()不直接显示图像问题
添加注释文本
3. 条形图
条形图绘制
条形图特点 4.饼图
饼图绘制
饼图特点
5.直方图
直方图绘制
直方图特点
6.箱线图
绘制箱线图
箱线图特点 7.散点图
散点图绘制
散点图特点 8.雷达图
绘制雷达图
雷达图特点
一.Matplotlib介绍安装 Matplotlib介绍 Matplotlib是一个Python的基本绘图库,它可以和Numpy一起使用。代替Matlab的一些功能。
作用 1.将数据进行可视化,使数据更直观;
2.使数据更加更具有说服力;
Matplotlib安装 由于Matplotlib是第三方库,所以我们需要安装它才可以使用。
安装命令:pip install matplotlib
安装参考:Installation — Matplotlib 3.5.2 documentationhttps://matplotlib.org/stable/users/installing/index.html
二.使用Matplotlib绘制基本图形 1.折线图 折线图绘制 方法:plot()函数
plt.plot(x,y)——默认的线样式及颜色绘制x,y构建的图形
实例:
参数:
(1)color 设置线的颜色;
(2)linestyle 设置线的样式;
(3)marker 标记样式;
(4)markerfacecolor 标记样式的颜色;
(5)markersize 标记样式的大小;
样式表:
等......
实例:
有时CentOS7启动异常,报XFS的错误,可以在emergency mode下尝试xfs_repair命令修复。
如果是LVM分区,先查看分区
#ls -l /dev/mapper
如果报错中明确告知了哪个分区出错了,比如dm-2,则针对其进行修复,命令如下:
#xfs_repair /dev/dm-2
若出现如下提示:
加上-L参数:
#xfs_repair -L /dev/dm-2
最后重启
#init 6
2022-06-16补充
如果报XFS(sda1): I/O Error 之类的错误,可在尝试在emergency mode,执行如下命令修复:
#xfs_repair -L /dev/sda1
目录
前言
基本说明
BeanPostProcessor的基本使用
实例应用
总结
前言 在这篇文章中,将会介绍bean的后置处理器,由于这个涉及到AOP的思想,这里不进行过多的深入,也就是不讲原理(后面文章会手写源码),这里只介绍后置处理器如何使用。
基本说明 在spring中,后置处理器会在bean初始化化之前和初始化之后进行调用,做相应的处理,我们可以在后置处理器中对bean进行统一的管理和操作
BeanPostProcessor的基本使用 我们要使用后置处理器,首先需要实现BeanPoatProcessor这个接口,下面我们创建一个类来实现这个接口。 在IDEA中,按ctrl+i,重写2个方法
postProcessBeforeInitialization和 postProcessAfterInitialization这2个方法,一个是在bean的初始化方法之前调用,一个是在bean初始化方法之后调用,它们的参数都是一样的,下面进行介绍
参数介绍
第一个参数 Object:表示我们配置的bean对象第二个参数 String:就是我们配置bean时指定的名称返回值 Object:这个就是我们对bean处理后要进行返回的bean,返回后,spring容器的中的bean就是我们这里返回的bean 使用 创建好之后要进行配置才能生效,这个很简单,只需要将我们创建的后置处理器加入到spring容器即可,就像正常的bean那样配置就行
注意事项
后置处理器会对所有的bean都生效,使用时需要注意,也就是所有bean创建前和创建后都会调用我们配置的后置处理器的对应方法
实例应用 我们创建一个People类,该类有一个gender属性,一个describe属性,要求就是当我们创建时bean时,如果gender是男,describe就是这是一个男生,否则describe就是这是一个女生。
首先创建People类
public class People { private String gender; private String describe; public String getGender() { return gender; } public void setGender(String gender) { this.gender = gender; } public String getDescribe() { return describe; } public void setDescribe(String describe) { this.describe = describe; } @Override public String toString() { return "
文章目录 前言一、多因素logistic回归分析1. 数据准备2. 回归分析 前言 logistic回归分析是医学统计分析过程中常用的一种影响因素分析的方法,最常用的是二元logistic回归分析,即以二分类数据为因变量的logistic回归分析。上次已经和大家分享了批量进行logistic回归分析的代码,接下来将分享多因素logistic回归分析的代码。
一、多因素logistic回归分析 多因素logistic回归分析一般的分析思路其实就是把单因素分析过程中发现的有意义的变量同时纳入logistic回归模型,除了纳入有意义的变量之外,还可以通过强制纳入其他变量构建不同的模型。
多因素回归分析还包括逐步回归分析,以后有时间会进行整理分析,本文仅介绍全部纳入的代码。
1. 数据准备 首先,我们构建一个数据集供我们进行分析,同时方便大家复制学习:
set.seed(1234)#设置随机种子,保证生成数据一致 log_data<- data.frame(Y = sample(0:1, 600, replace = T), sex=sample(1:2, 600, replace = T), edu=sample(1:4, 600, replace = T), BMI=rnorm(600, mean = 22, sd = 3), 白蛋白=rnorm(600, mean = 35, sd = 6), 随机血糖=rnorm(600, mean = 4.75, sd = 1.2)) Y为我们要研究的二分类因变量,sex、edu、BMI、白蛋白和随机血糖为自变量数据。
使用summary()函数查看一下数据特征:
> summary(log_data) Y sex edu BMI 白蛋白 随机血糖 Min. :0.0000 Min. :1.000 Min. :1.00 Min. :13.
目录
创建测试项目
创建xposed模块
新增默认带Empty Activity的Module
在Module下的build.gradle文件添加依赖包
在Module下的AndroidManifest.xml文件添加xposed相关meta标签,用于框架识别
添加hook类,继承IXposedHookLoadPackage实现hook方法
在模块下的src/assets/xposed_init(没有则新建)文件添加完整的hook类名
安装xposed模块
hook测试app 对于加壳的情况 第一次hook 第二次hook
其他示例
目标代码 hook模块
总结
参考 Xposed:https://github.com/rovo89/Xposed
Xposed Installer:[OFFICIAL] Xposed for Lollipop/Marshmallow/Nougat/Oreo [v90-beta3, 2018/01/29] | XDA Forums
api文档:Xposed Framework API
Maven包:https://mvnrepository.com/artifact/de.robv.android.xposed/api
注:安装原生xposed框架需root,若无法root可以考虑使用virtualXposed
https://github.com/android-hacker/VirtualXposed
创建测试项目 为了便于实践,我们直接创建一个名为test的Empty Activity项目即可。
接着在MainActivity.java中,新增一个Log方法,我们后面用xposed框架来hook这个方法。
package com.example.test; import androidx.appcompat.app.AppCompatActivity; import android.os.Bundle; import android.util.Log; import android.widget.TextView; import java.util.Random; public class MainActivity extends AppCompatActivity { private static final String TAG = "xposedText"; private TextView tv_hook; @Override protected void onCreate(Bundle savedInstanceState) { super.
文章目录 Python dict字典Python字典添加键值对Python字典修改键值对Python字典删除键值对判断字典中是否存在指定键值对 Python dict字典 由于字典属于可变序列,所以我们可以任意操作字典中的键值对(key-value)。Python 中,常见的字典操作有以下几种:
向现有字典中添加新的键值对。修改现有字典中的键值对。从现有字典中删除指定的键值对。判断现有字典中是否存在指定的键值对。 初学者要牢记,字典是由一个一个的 key-value 构成的,key 是找到数据的关键,Python 对字典的操作都是通过 key 来完成的。
Python字典添加键值对 为字典添加新的键值对很简单,直接给不存在的 key 赋值即可,具体语法格式如下:
dictname[key] = value 对各个部分的说明:
dictname 表示字典名称。key 表示新的键。value 表示新的值,只要是 Python 支持的数据类型都可以。 下面代码演示了在现有字典基础上添加新元素的过程:
a = {'数学':95} print(a) #添加新键值对 a['语文'] = 89 print(a) #再次添加新键值对 a['英语'] = 90 print(a) 运行结果:
{‘数学’: 95}
{‘数学’: 95, ‘语文’: 89}
{‘数学’: 95, ‘语文’: 89, ‘英语’: 90}
Python字典修改键值对 Python 字典中键(key)的名字不能被修改,我们只能修改值(value)。
字典中各元素的键必须是唯一的,因此,如果新添加元素的键与已存在元素的键相同,那么键所对应的值就会被新的值替换掉,以此达到修改元素值的目的。请看下面的代码:
a = {'数学': 95, '语文': 89, '英语': 90} print(a) a['语文'] = 100 print(a) 运行结果:
对于程序员来说,除了日常争论世界上最好的语言是哪一门以外,哪款 IDE 是最好的也是争议颇多,今天我们就来介绍 10 款最好的 Python 编程 IDE,总有一款适合你!
什么是 IDE? IDE 代表集成开发环境,它是一个 GUI(图形用户界面),程序员可以在其中编写代码并生成最终产品。IDE 基本上统一了软件开发和测试所需的所有基本工具,这反过来又帮助程序员最大化输出。一些 IDE 是通用的,也就是说它们可以支持多种语言,例如,Sublime Text、Atom、Visual Studio 等。同样特定语言的 IDE 支持特定语言,它们还可以帮助我们了解语法错误等信息,比如:用于 Python 的 Pycharm、用于 Java 的 Jcreator、用于 Ruby/Rails 的 RubyMine 等等
10 大 IDE 一个完备的 IDE 应该包括以下内容:
代码编辑器:提供代码编辑器来编写和操作源代码,代码编辑器可以是独立的应用程序,也可以集成到 IDE 中语法高亮:提供此功能以用不同的颜色和字体标记基本语言的语法自动补全代码:旨在最大限度地减少时间消耗,自动完成功能代码或建议程序员需要出现哪些变量、参数或代码位调试器:调试器是测试和调试源代码所需的工具编译器:编译器是将源代码从一种语言翻译成另一种语言的组件,编译器通常执行预处理、词法分析、代码优化和代码生成任务语言支持:IDE 可以是特定于语言的,也可以支持多种语言 PyCharm PyCharm 由捷克公司 JetBrains 开发,是一个特定于 Python 的 IDE,是一个跨平台的 IDE。因此,用户可以根据自己的需要下载任何 Windows、Mac 或 Linux 版本来使用。可以说,PyCharm 被认为是 Python 最好的 IDE 之一,并且是使用最广泛的
除了常见功能外,PyCharm 还提供了其他功能,例如:
专业的项目视图允许在文件之间快速切换与 Django、Flask 和 web2py 一起快速进行 Web 开发PyCharm 配备了 1000 多个插件,程序员也可以编写自己的插件来扩展其功能它提供两个版本供下载,免费的社区版和付费的专业版,一般情况下社区版的功能完全够用 Spyder 是 Pierre Raybaut 于 2009 年开发的开源、跨平台 IDE。主要为数据分析师和科学家设计,被认为是一个用 Python 编写的强大的科学开发 IDE
前言: 回想去年九月到现在,经过将近一年的学习,感觉自己还是有点莫名奇妙地过这个大学生活,自以为学会了很多东西,但是好像并不知道这些东西会带给我什么,有什么用.
我自然是不敢在教务网上评论这门课的,只能在这里浅谈几句.其实作为一个学生来说,我并不觉得这门课真正的教会了我什么,很多的东西也是全靠自己到处找博客,找经典书籍硬啃,一个学期的课程也就那么几个课时.老师真正能为我们做的不过只是告诉我们,有一个东西叫面向对象编程,很有用,也很好用,仅此而已.剩下的都还需要我们自己去摸索学习,现在想来好像很多计算机的大佬们也不过是如此学过来的吧.
敬告后人:
至于课设一类的东西吧,我感觉其实你要说它有多牛逼也牛逼不到哪里去,不过宇宙机这个专业吧,多写写多敲敲还是好的,不管是在实现中学到的东西,还是对自己已经学过的东西一个熟悉,都是有潜移默化的好处的,更别说在整个架构上面的思维得到的锻炼了,因此我认为还是有益的,至少是一个让自己学的东西能够得到实践的机会.课可以翘,代码不能不敲,基础不能不打牢,课设能做还是做做吧.或许正是一个课设里面遇到的问题带你打开了其他的大门呢?
当然如果你是SWJTU的学生并且这学期选了这门课的话,也可以直接拿源码修改过后提交,不过我依然强烈建议拿这份代码做一个参考,而并不是不加思考的食用.按常理来说的话这份代码值得修改的地方还有很多,包括并没有使用继承,多态等机制(纯粹因为我认为没必要),这些因素可能会导致这份代码并不能称得上是一个好的课设.
基于c++实现的一个图书管理系统 实则为面向对象的期末课程设计 介绍
一个期末作业,作为兴趣开源
安装教程
下载解压文件后直接用Clion打开即可使用
点我直接下载源码压缩包https://gitee.com/jellyfishkngiht/library-system/repository/archive/v1.0?format=zip
或者点我转到gitee仓库https://gitee.com/jellyfishkngiht/library-system
使用说明
程序菜单完善,无需说明
参与贡献
不可参与贡献,此版本为最终版,将不再对代码进行维护管理
关于项目的说明
文件目录
BaseInfo/FileWrite/Infos/System/CmakeLists.txtmain.cpp BaseInfo/
LibraryFunction.hFunctions.cppCmakeLists.txt FileWrite/
FileWrite.hFileWrite.cppCmakeLists.txt Infos/
alllabs.txtbooks.txtlibrarians.txtunhandledlabs.txtusers.txt System/
System.hSystem.cppCmakeLists.txt 主要的类有:
LibraryFuntion.h : Reader, Librarian, Lab, Book, Menu
FileWrite.h : MyFile
System.h : System
Infos/ 文件夹是用于文件操作的
类的关系大概是 System 类去操作 LibraryFunction.h 中的各种类,最后在 main.cpp 中调用 MyFile 类和 System 类
注: 本程序并未使用继承和多态机制,并且封装性不够好,如果是用于应付期末作业的话慎用(本人摆烂哥)
问题:替换dll文件后,自定义服务启动时报错:1053服务没有及时响应启动或控制请求
排查原因:可能是程序启动缺少某些dll文件
解决方案:1、使用depends依赖工具查看新增的dll文件是否缺少哪些dll文件,可以在c:\windows\system32中查找,找到后添加到程序所在的目录下后启动服务
2、若第1步无法解决,可尝试手动启动exe程序,查看报错,如图所示,添加缺失的文件再次启动服务即可解决问题
写在前面 在上一弹中,我们讲了振铃是如何产生的,以及如何去避免振铃的产生。这一弹我们要讲的这是运算放大电路中的相位补偿问题,振铃的产生就是由于相位的滞后导致的,我们这节讲的相位补偿同样也可以解决振铃的问题,上一节采用的是破坏反馈回路的低通环节来解决甚至避免振铃问题。而这一节我们采用相位 补偿方式解决振铃问题,这样想,既然我们没法避免低通环节的产生,我们就加入一个能够使相位超前的高通电路环节来对其进行补偿,因为高通滤波器具有相位超前的特性, 我们就利用他的这个特性来进行补偿,从而解决振铃问题。下面我们就来看看吧。
先来看看是如何进行补偿的 看下面这个简单电路的例子,
信号源频率1KHz,幅值5v,方波,示波器探头的寄生电容为54P
R1 1M R2 9 M为分压电阻。
看下这种情况下的输出波形,由于低通环节的存在(积分电路),导致输出波形圆头圆脑。
下面我们加入一个补偿环节来对电路进行补偿,这里我们在R2上并联一个电容,容值为6p,整好为54p的1/9,也即电阻比值的反比,至于为啥是这个比例,我们以后再作解释。今天记住就行。
这里先提前说下,针对当前的参数,补偿电容为6P时是处于完全补偿状态,小于6P则处于欠补偿状态,大于6P则处于过补偿状态。下面我们来看看电路仿真以及波形输出:
1、完全补偿
补偿电容6P
波形比较标准。
2、欠补偿
补偿电容2p
欠补偿,波形圆头圆脑。
3、过补偿
补偿电容10p
过补偿,波形尖头尖脑
所以在选择补偿电容时一定要选择正确的参数,否则你的补偿电路可能会得不偿失。
相位补偿解决振铃问题 采用上面相同的思路,我们同样也可以解决运放电路中振铃的问题。拿个电路出来:
信号频率10KHz,幅值1 v,反相端寄生电7 nf
上述电路是会产生振铃的:
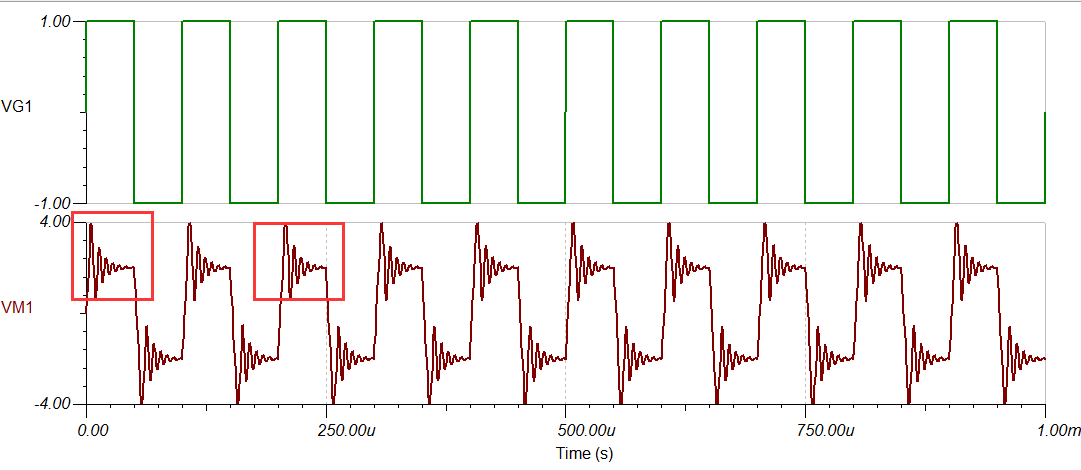
我们加入补偿环节:在反馈电阻R2上并联一个电容就可以达到补偿的作用,
说明: R2和C1构成了一个低通滤波环节,使相位滞后,儿而我们在R2上并联一个电容C2,C2和R1构成一个高通滤波器,使相位超前,已达到相位补偿的作用。看图:
看补偿后的输出波形:振铃基本消失。
完!!
直接上代码:
import win32con import ctypes ctypes.windll.user32.MessageBoxTimeoutW(0,'请选择(不理会,则10秒后自动关闭)\n','询问',win32con.MB_YESNO,0,10000) 解释:
Python实战中,有时需要弹出一个对话框,让用户选择,如果用户在指定的时间没有作出选择,则自动关闭,并返回一个默认值。
实现思路是使用WindowsAPI函数库中未公开的MessageBoxTimeoutW( 这个可以使用汉字作为提示文字)或MessageBoxTimA(这个只能使用英文作为提示文字)。第一个参数是窗口句柄,就是弹出的对话框属于哪个窗口,0表示桌面;第二个参数是提示文字;第三个参数是要显示的按钮,第四个参数是延时时间。
有些同学想在电脑上面录屏,但是不知道电脑怎么录屏。下面就和大家分享电脑录屏怎么录的具体方法。
1.win10自带的录屏工具
通过按快捷键Win + G,打开游戏录制工具栏,就可以开始使用win10自带的录屏工具。如果你是win7系统,可以使用QQ的录屏功能或者下载安装录屏软件。
2.QQ录屏功能
QQ比较常用基本每个电脑都有安装,如果对录屏要求不高,就可以直接使用QQ的录屏功能。QQ截图中其实有比较多的实用工具,其中就有一个录屏功能,按截图快捷键ctrl+alt+a,打开截图工具,选择录屏即可。
3.使用其他专业录屏软件
以上两个录屏方法都比较简单,适合一些不重要的临时录屏。如果你需要录制课件教程,游戏等,可以选择安装一些比较优秀的录屏软件。可以百度“办公人导航”,关键词“电脑录屏软件”。
通过上面的方法可以下载比较好用可以免费使用的电脑录屏软件。以上就是和大家关于电脑怎么录屏,电脑录屏怎么录的问题解答,希望对大家有所帮助。
题目:编写一个函数fun1,输入3个顶点坐标,求的面积。
代码示例:
#include<stdio.h> #include<math.h> double fun1(double x1,double y1,double x2,double y2,double x3,double y3) { double a,b,c,s; a=sqrt(pow((x1-x2),2)+pow((y1-y2),2)); b=sqrt(pow((x1-x3),2)+pow((y1-y3),2)); c=sqrt(pow((x3-x2),2)+pow((y3-y2),2)); if((a+b>c)&&(a+c>b)&&(b+c>a)) { s=(1.0/4)*sqrt((a+b+c)*(a+b-c)*(a+c-b)*(b+c-a)); return s; } else { printf("It is not a triangle!"); return -1.0; } } int main() { double x1,y1,x2,y2,x3,y3,s; scanf("%lf%lf%lf%lf%lf%lf",&x1,&y1,&x2,&y2,&x3,&y3); s=fun1(x1,y1,x2,y2,x3,y3); if(s==-1.0) printf("It is not a triangle!"); else printf("%lf\n",s); return 0; } 更多大学课业实验实训可关注公众号:Time木
回复相关关键词
学艺不精,若有错误还望指点
cmd / /k:运行结束后保留窗口,继续接收命令(keep)
/c:运行结束后直接关闭窗口(close),不建议单独使用,可在末尾用&连接pause
&:连接不同命令
Pause:暂停,运行结束后等待任意键输入…
Exit:退出,若用/c可不用此命令
Eg.
Cmd /k ··· :运行完命令继续接收命令
Cmd /k ···& pause :运行完命令等待任意键输入…,接收任意键继续接收命令
Cmd /k ···& pause & exit :运行完命令等待任意键输入…接收任意键后退出
Cmd /c ··· :结果窗口一闪而过
Cmd /c ···& pause :运行完命令等待任意键输入…接收任意键后退出
通过notepad"运行"按钮,经过命令行显示: 点击运行,然后输入以下命令,保存,设置快捷键,完成
gcc编译运行c:
cmd /k gcc "$(FULL_CURRENT_PATH)" -o "$(CURRENT_DIRECTORY)\$(NAME_PART).exe" & "$(CURRENT_DIRECTORY)\$(NAME_PART).exe" & PAUSE & EXIT
g++编译运行c/c+=:
cmd /k g++ "$(FULL_CURRENT_PATH)" -o "$(CURRENT_DIRECTORY)\$(NAME_PART).exe" & "$(CURRENT_DIRECTORY)\$(NAME_PART).exe" & PAUSE & EXIT
tcc编译运行c:
cmd/k tcc "$(FULL_CURRENT_PATH)" -o "$(CURRENT_DIRECTORY)\$(NAME_PART).exe" & "$(CURRENT_DIRECTORY)\$(NAME_PART).exe" & PAUSE & EXIT
一、VSCode常用的插件
目录
1.Chinese (Simplified) 2.Auto Rename Tag 3.One Dark Pro 颜色主题 4.格式化代码(vscode系统自带) 5.open in browser 浏览器预览页面 6. Live Server 实时预览(推荐) 7. vscode-icons 设置文件图标主题 8. Easy LESS 编译less文件
9. 会了吧 10.git history
11.GitLens — Git supercharged
12.Bracket Pair Colorizer
13.Path Intellisense
14.Auto Close Tag
15.Vetur
16.HTML CSS Support
1.Chinese (Simplified) vscode下载完毕是英文版的,先安装这个插件,改为中文版,所以是我们第一个安装的插件。 中文插件chinese
2.Auto Rename Tag 修改开始标签,结束标签跟着自动变化,比较好用。
auto rename tag
3.One Dark Pro 颜色主题 one dark pro
4.格式化代码(vscode系统自带) 现在格式化代码的插件非常多,比如Prettier等等。 刚开始学,不太建议安装插件,先自己手写规范的语法格式
但是html标签嵌套比较多,可能需要自动格式化比较好,所以我们可以利用vscode自动的功能格式化代码,暂且不用格式化插件,自动保存照样能格式化代码。
期末考试前面的最后一次离散数学编程作业,十分感慨。
一学期的离散数学学习,让我懂得了不能说是整个离散数学的体系吧,也可以说是一点也听不懂了,现在正值6月13号这么一个神圣的日子,我不禁感叹:我真的不想挂科。但是这门折磨的所谓的“专业课”也就到此为止了,或余实不合科研之路,只得目光短浅于两三前后端之琐事。故人各有志,非众生皆可忍导师压榨之苦、论文枯竭之苦,愚且鼠目寸光之辈哉,且浮于浅显之处乎!遂钟写此篇,抒己浅志,且造福于众生也。
代码如下:(望君付师作业时稍加改动,不至连坐之刑也)
#include "iostream" #include "vector" #include "algorithm" using namespace std; class Node { private: int degree; int color = -1; int number; static int maxColor; vector<int> connected; public: explicit Node(int degree = 0, int number = 0) : degree(degree), number(number) {} ~Node() = default; int getDegree() const; int getColor() const; int getNumber() const; void setDegree(const int& d); void setColor(const int& c); void setNumber(const int& n); void pushNode(const int& n); static void setMaxColor(const int& max); static int getMaxColor(); bool find(Node* node); bool operator>=(const Node& node) const; }; int Node::maxColor = -1; int Node::getDegree() const { return degree; } int Node::getNumber() const { return number; } int Node::getColor() const { return color; } void Node::setColor(const int &c) { color = c; } void Node::setNumber(const int &n) { number = n; } void Node::setDegree(const int &d) { degree = d; } void Node::pushNode(const int &n) { connected.
学习了冒泡的思想之后,自己写出来一个c语言冒泡排序程序,运行可以,因为是自己想的,所以和别的使用两次for的程序不一样,我使用的是while嵌套for,思路是:
因为要遍历数组n次(n为数组元素个数),所以外层用while遍历,然后内层是for的一次冒泡排序,其中j充当计数器的作用,也是跳出while的条件,部分代码如下:
while(j!=n) { for(i=0;i<n;i++) { if(i!=n-1) if(a[i]>a[i+1]) {temp=a[i]; a[i]=a[i+1]; a[i+1]=temp;} } j++; } 精华部分有了,那么由这个可以演变出自定义k次遍历后,就是很简单的代码了:
#include<stdio.h>
int main()
{
int n,k,i,j=0,temp;//n是数组个数,k是冒泡遍历多少次
scanf("%d",&n);
int a[n];
scanf("%d",&k);
for(i=0;i<n;i++)
{
scanf("%d",&a[i]);
}
while(j!=k)//精华部分
{
for(i=0;i<n;i++)
{
if(i!=n-1)
if(a[i]>a[i+1])
{temp=a[i];
a[i]=a[i+1];
a[i+1]=temp;}
}
j++;
}
for(i=0;i<n;i++)
{
if(i==n-1)
printf("%d",a[i]);
else
printf("%d ",a[i]);
}
return 0;
}
下载MySQL压缩包 去MySQL官网下载MySQL8数据库的压缩包
解压MySQL压缩包 下载完了是一个压缩包
如图:
解压缩一下:
其内部目录结构如下:
创建配置文件 在MySQL的根目录中新建配置文件:my.ini
配置信息如下:
[mysqld] #设置3306端口 port=3306 #设置mysql的安装目录,这个大家需要根据自己的安装目录来改一下 #值得一提的是,这个地方建议大家用\\表示一层目录,用\有时候会报错,也不知道为什么 basedir=D:\\ProgramFiles\\MySQL\\mysql-8.0.25 #设置mysql数据库的数据的存放目录 datadir=D:\\ProgramFiles\MySQL\\mysql-8.0.25\\data #允许最大连接数 max_connections=200 #允许连接失败的次数。 max_connect_errors=10 #服务端使用的字符集默认为utf8mb4 character-set-server=utf8mb4 #创建新表时将使用的默认存储引擎 default-storage-engine=INNODB #默认使用“mysql_native_password”插件认证 default_authentication_plugin=mysql_native_password [mysql] #设置mysql客户端默认字符集 default-character-set=utf8mb4 [client] #设置mysql客户端连接服务端时默认使用的端口 port=3306 default-character-set=utf8mb4 如图所示:
开始安装 第一步:用管理员身份打开命令提示符 按windows键,在开始菜单中输入cmd找到命令提示符,并用管理员身份运行
如果你的账户本身就是管理员,那么你可以直接按win+r快捷键,输入cmd,然后直接回车,调出命令提示符
如图
第二步:切换到你解压MySQL的根目录中 如图:
第三步:初始化数据库 输入命令:mysqld --initialize --console回车后开始初始化数据库,这个过程会花一点时间,初始化完成之后会出现如下界面:
如图:
异常情况 正常情况下,输入mysqld --initialize --console命令回车后就会开始初始化数据库,但有的小伙伴可能会遇到这种情况:
mysqld.exe - 系统错误 由于找不到MSVCP1.40.ddl,无法继续执行代码,重新安装程序可能会解决此问题。
如图:
原因 这是因为缺少c++运行库导致的,这种情况在windows10比较常见。
解决办法 用DirectXRepair修复工具修复后再次执行mysqld --initialize --console命令即可。我在这里给各位小伙伴提供了百度网盘的下载地址。大家就不用去网上慢慢找了。
百度网盘下载地址:https://pan.baidu.com/s/1BHvjRVgV134QshOffAER3w
提取码: 63p3 DirectXRepair修复工具的使用步骤: 一、解压缩DirectXRepair包 如图:
在word中利用mathtype的公式“右编号”功能可以很轻松的对所有公式的格式进行排版
但是如果不注意的话,会发现公式的编号并没有对齐到页面最右边
一般情况下,这是因为公式的制表位的原因
可参考如下解决方法:
word中mathtype7公式右编号右对齐解决方法,超实用!
讲的很清楚!
web自动化测试理论之selenium八大定位 一、ID定位 概念:通过元素的id属性来定位元素。
前置:所要定位的元素必须有id属性
方法:driver.find_element_by_id(id属性值)
""" 需求: 打开注册A.html页面,完成以下操作 1).使用id定位,输入用户名:admin 2).使用id定位,输入密码:123456 3).3秒后关闭浏览器窗口 """ # 导包 from time import sleep from selenium import webdriver # 创建浏览器驱动 driver = webdriver.Chrome() # 打开测试网址 driver.get('file:///C:/Users/Desktop/UITest/%E6%B3%A8%E5%86%8CA.html') # 定位元素,调用模拟操作方法 driver.find_element_by_id('userA').send_keys('admin') driver.find_element_by_id('passwordA').send_keys('123456') # 暂停3秒看效果 sleep(3) # 操作完毕关闭浏览器 driver.quit() 二、Name定位 概念:通过元素的name属性来定位元素。
前置:所要定位的元素必须有name属性。
方法:driver.find_element_by_name(name属性值)
特点:当前页面可以重复
由于name属性值可以重复,所以使⽤时需要查看是否为唯⼀
# 定位元素,调用模拟操作方法 driver.find_element_by_name('userA').send_keys('admin') driver.find_element_by_name('passwordA').send_keys('123456') 三、class_name 定位 概念:通过元素的class_name属性来定位元素。
前置:所要定位的元素必须有class类名属性。
方法:driver.find_element_by_class_name(class属性值)
特点: class属性值可以有多个值
说明:如果标签有多个class值,使⽤任何⼀个都可以。如:c1
<p> <label for="emailA">电子邮件A:</label> <input type="emailA" placeholder="电子邮箱A" class="c1 c2 c3"> </p> # 定位元素,调用模拟操作方法 driver.
morris遍历原理参考此处:Morris遍历_六甲横宝的博客-CSDN博客_morris遍历
下面给出用morris遍历实现二叉树的前中后序遍历代码:
前序:
vector<int> morrisPreOrder(TreeNode *root) { vector<int> res; TreeNode *cur = root, *mostRight = nullptr; while (cur) { mostRight = cur->left; if (mostRight) { //左子树不为空,cur会到达两次 while (mostRight->right&&mostRight->right != cur) { mostRight = mostRight->right; } if (mostRight->right == nullptr) { mostRight->right = cur; res.push_back(cur->val); //第一次到的时候打印 cur = cur->left; continue; } else { mostRight->right = nullptr; //第二次到的时候不打印 } } else { //左子树为空,cur只会到达一次 res.push_back(cur->val); } // cur没有左子树或其左子树最右节点的right指针指向cur,均要将cur右移 cur = cur->right; } return res; } 中序:
(1)top查看CPU占用情况,可以看到PID为17314的进程CPU占比为502。把CPU都吃完了,前端页面一直很卡
(2)定位具体线程:top -H -p PID 看下该进程下线程的情况,可见5201这几个吃了CPU
也可以:ps -mp 17314 -o THREAD,tid定位具体线程。下边拿5200或者5201线程来分析
(3)拿5201线程ps一下:ps -efL | grep 线程ID,定位到是canal的问题
(4)printf "%x\n" 线程ID: 将需要的线程ID转换为16进制格式
(5)jstack PID| grep 十六进制线程ID -A60: 打印进程ID的Java堆栈信息(A60 就是过滤到关键词之后(A:after)60行信息,不够可以自己再加)
打印的堆栈信息报死锁异常。上边又是报canal的进程吃的CPU,推断是不同环境Canal的任务之间导致死锁。我这里是停掉A服务的一些任务,B服务就正常了,因为B服务有些任务时从A导过来的。具体CPU吃紧情况,可以按照这个思路分析的,当然也可以使用一些堆栈跟踪工具。
Tomcat的目录结构 tomcat是什么目录结构及作用session持久化示例 tomcat是什么 Tomcat是Apache 软件基金会(Apache Software Foundation)的Jakarta 项目中的一个核心项目,由Apache、Sun 和其他一些公司及个人共同开发而成。
Tomcat 服务器是一个免费的开放源代码的Web 应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP 程序的首选。
Tomcat和IIS等Web服务器一样,具有处理HTML页面的功能,另外它还是一个Servlet和JSP容器,独立的Servlet容器是Tomcat的默认模式。不过,Tomcat处理静态HTML的能力不如Apache服务器。
除tomcat外,web应用服务器还有jetty,weblogic,websphere,undertow等。
注意:有时我们会将web叫做web服务器,实际上tomcat更准确的叫法是应用服务器。 web服务器主要是指专门来处理html,css,图片等静态资源的服务器,必要apache服务器。
目录结构及作用 tomcat目录结构的截图(tomcat-9.0.60):
作用
backup
eclipse第一次启动tomcat时,会在下面新建一个backup文件夹,但是出于安全方面考虑,系统默认不让用户新建文件夹(在tomcat文件夹右击,选择属性 --> 安全,选择当前系统用户,点击编辑,选择完全控制,就可以新建了)
bin
bin目录主要用来存放tomcat命令的目录,里面主要有两种类型的文件,一种是以.bat为扩展名的文件,一类是以.sh为扩展名的文件。其中.bat的文件是在windows平台的命令,而.sh则是在linux平台的文件。
该目录主要的文件有以下几个:
setclasspath 用于设置Java环境变量,如JAVA_HOME,JRE_HOME等
catalina该文件也是用来配置环境的,如CATALINA_HOME,及tomcat的安装路径,我们可以在此目录设置Java的启动参数,如最大最小堆空间大小;
例如:JAVA_OPTS=“$JAVA_OPTS -Xms256m -Xmx512m -Xmn128m -XX:PermSize=128m -XX:MaxPermSize=512m”
startup用来给启动tomcat,当双击startup后,tomcat启动,读取catalina脚本配置启动环境,catalina又会调用setclasspath脚本,用来设置jdk需要的环境变量,如果系统没有定义JAVA_HOME环境变量,则会报错退出
shutdown用于停止tomcat服务
conf
该目录主要用来存放tomcat的配置文件, 重要的配置文件如下:
server.xml 用于配置端口号,虚拟主机,默认加载项目,请求编码等等,是tomcat中最常使用的配置文件
web.xml 为所有的部署在该tomcat下的web应用通用的配置,与每个web应用的web.xml配合使用。
例如:
DefaultServlet,就算系统中没有配置任何的servlet,tomcat依然可以处理html,js,css等静态资源的请求,就是这个servelt起的作用;
JspServlet,当请求jsp页面时,则会用到这个servlet。
session过期时间配置session-timeout参数,也是在这个web.xml中配置的。
catalina.policy 这个是tomcat安全相关的配置文件,主要使用安全策略文件可以在tomcat启动是附上 -security
catalina.properties 安全配置,类加载设置,不需扫描的类,字符缓存等配置
context.xml 所有在tomcat中发布的应用都会使用的公用配置,例如:发布的web应用的描述文件的位置及名称,及session持久化配置等。session持久化示例请参考第三部分的示例
tomcat-users.xml
tomcat的角色(授权用户)配置文件,用于访问tomcat管理应用程序时的安全性设置,用server.xml中引用的默认的用户数据库域(UserDatabase Realm)使用它,所有的凭据都是默认被注释的
tomcat-users.xsd 定义了 tomcat-users.xml 所使用到的标签,即tomcat-user.xml 的结构定义文件
lib
所有部署在tomcat中的web应用公用的jar包
logs
用于保存tomcat运行时的日志数据
catalina.{yyyy-MM-dd}.log tomcat自己的运行日志localhost.
WIN10永久彻底关闭自动更新方法步骤: 一、禁用Windows Update服务二、在组策略里关闭Win10自动更新相关服务三、禁用任务计划里边的Win10自动更新四、在注册表中关闭Win10自动更新五、将网络连接设为计费模式六、若用户的Win10本身缺很多原本应该自带的东西,欢迎大家使用系统之家装机大师来重装原版的Win10系统。 最近有很多朋友问我Win10如何永久关闭自动更新,每次打开电脑都是一个大大的笑脸让我更新系统,但是又不能取消更新很是烦恼。在这里小编用五种方法教你永久关闭win10自动更新问题。 **五大方法 永久彻底关闭WIN10系统自动更新【已验证有效】 关注系统之家学习更多电脑知识呀!** 电脑的更新和手机的更新其实是一样的,就更新本身而言是一件好事,但是随着系统版本的更新,对硬件的要求就越高,我们的硬件不可能经常更新,所以很多人调侃:系统的更新就是解决系统过度流畅的“bug”。那用户的win10系统自动更新可谓是非常顽固,很多用户在网上试了各种关闭win10自动更新的方法,刚开始看着好像是关闭更新了,可没过多久系统就又开始自动更新了。今天系统之家就来教大家如何彻底关闭win10自动更新,该方法亲测有效。好了,话不多说,让我们进入正题。Win10系统下载_系统之家
Win10彻底关闭自动更新方法步骤:
由于win10自动更新非常顽固,所以我们要从多个地方下手才能永久关闭其自动更新,别怕麻烦,跟着下面的步骤一步步操作。
一、禁用Windows Update服务 1、同时按下键盘 Win + R,打开运行对话框,然后输入命令 services.msc ,点击下方的“确定”打开服务,如下图所示。
2、找到 Windows Update 这一项,并双击打开,如图所示。
3、双击打开它,点击“停止”,把启动类型选为“禁用”,最后点击应用,如下图。
4、接下再切换到“恢复”选项,将默认的“重新启动服务”改为“无操作”,然后点击“应用”“确定”。
二、在组策略里关闭Win10自动更新相关服务 1、同时按下Win + R 组合快捷键打开运行命令操作框,然后输入“gpedit.msc”,点击确定,如下图。
2、在组策略编辑器中,依次展开 计算机配置 -》 管理模板 -》 Windows组件 -》 Windows更新。
3、然后在右侧“配置自动更新”设置中,将其设置为“已禁用”并点击下方的“应用”然后“确定”,如图所示。
4、之后还需要再找到“删除使用所有Windows更新功能的访问权限”,选择已启用,完成设置后,点击“应用”“确定”,如图所示。
5.找到允许自动更新从metered 链接上自动下载更新,并设置为禁用。
三、禁用任务计划里边的Win10自动更新 1、同时按下 Win + R 组合快捷键打开““运行”窗口,然后输入“taskschd.msc”,并点击下方的“确定”打开任务计划程序,如图所示。
2、在任务计划程序的设置界面,依次展开 任务计划程序库 -》 Microsoft -》 Windows -》 WindowsUpdate,把里面的项目都设置为 [ 禁用 ] 就可以了。(我这里边只有一个任务,你的电脑里可能会有2个或者更多,全部禁用就行了)
四、在注册表中关闭Win10自动更新 1、同时按下 Win + R 组合快捷键,打开运行对话框,然后输入命名 regedit,然后点击下方的「 确定 」打开注册表,如下图所示。
2、在注册表设置中,找到并定位到 [HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\UsoSvc] (包括HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\WaaSMedicSvc,操作完全一致)。然后在右侧找到“Start”键。
html报告主要分为两个部分:baseboard与charts
一、Baseboard(基本报告情况)
1、Test and Report information(测试报告与信息)
2、APDEX (Application Performance Index)(应用性能信息)
3、Statistics(统计)
4、Error(请求异常)
二、Charts(详细报告)
Over time(每时运行时信息):
1、response time over time(响应时长):
2、Response Time Percentiles Over Time (successful responses)(90%、95%、99%线程在各个时间段的响应时间):跟聚合报告里面的90、95、99%差不多
3、Active threads over time(各个线程每时运行情况):线程多的时候看比较有意义
4、bytes throughout over time(每时接收与发送字节的情况)
5、latencies over time(每时请求的延迟时长):如图一开始延迟很高,后面有所下降
6、connect time over time(每时连接需要的时长):如图一开始请求并发高,连接需要的时间很高
Througput(吞吐量)
1、hits per second(每时发起的请求数)
2、codes per second(各个code每时响应数量)
3、teansactions per second(每时事物响应数目)
4、total transations per second(总每时事务请求曲线)
5、response time vs request(每时各个请求响应类型的平均响应时间)
6、latency vs request(各个请求类型的每时延迟时间)
Response time(响应时间)
1、Response time percentiles(响应时间百分比分布)
2、response time overview(响应时间条状对比图)
Packet Tracer安装包下载链接: 链接:https://pan.baidu.com/s/19BbCZzSxukKKdsdaqw7dHw 提取码:6666
(若果链接失效,可在评论区留言。)
安装步骤 1、解压缩文件,得到 cisco packet tracer8.0 安装包。
2、首先双击运行"PacketTracer800_Build212_64bit_setup-signed.exe"程序,接受安装许可协议。
3、可以按默认目录进行安装,也可以指定文件夹自行安装。选择好安装路径后,继续点“next”直到安装界面即可。
4、软件正在安装中,等待一会。
5、直到安装完成,取消勾选,先不要运行软件;
6、打开 Crack 文件夹,右击鼠标以管理员身份运行"Patch.exe"程序,点击 Patch进行激活。
注意:
(1)激活前要关闭杀毒软件,避免误以为不安全,导致激活不成功。(import !!!)
如果安装在默认C盘路径,直接进行激活即可。
(2)如果安装路径不是默认的C盘路径,点击Patch键后,点击 是,然后根据相应安装目录进入Cisco Packet Tracer 8.0\bin文件夹下,并选择“PacketTracer.exe”文件,点击确定,即可激活。
例如:
安装在D盘的路径 D:\ Cisco_jsjwl_sy_model\ Cisco Packet Tracer 8.0\ bin
7、激活成功后可看到相应提示。
01.01 基本工具 H265 视频确认工具
ffmpeg下载:
参考: Win10系统如何安装64位ffmpeg
从 https://github.com/BtbN/FFmpeg-Builds/releases 下载win10 版本的static 版本的 ffmpeg 发布版本。
解压后把 ffmpeg.exe 的目录 ffmpeg-n5.0-latest-win64-gpl-5.0\bin 加入 PATH 环境变量。
注意:
A:文件名含 shared 是动态库版本,为了测试方便,尽量使用静态库版本,就是不带 shared 的。
B:gpl版本支持h264/h265,lgpl版本不支持h264/h265。
cmd 或者 Windows Terminal 中运行 ffmpeg -version 可以查看版本信息。
01.02 ffmpeg录屏 :: 1. 查看FFmpeg版本是否支持dshow设备 ffmpeg -formats | findstr dshow :: 2 列举该计算机下所有视频捕捉设备(包括虚拟设备) ffmpeg -list_devices true -f dshow -i dummy :: 3 查看设备支持选项 ffmpeg -list_options true -f dshow -i video="Integrated Camera" :: 4 直接播放笔记本电脑摄像头数据 ffplay -f dshow video="
打印机是日常办公中必不可少的一个工具,不过想要使用打印机的话是需要连接电脑的,但有小伙伴反馈自己Win10系统的电脑在添加打印机的时候找不到对应的型号,那么遇到这种情况应该怎么办呢?下面就和小编一起来看看解决方法吧。
详细
打印机是日常办公中必不可少的一个工具,不过想要使用打印机的话是需要连接电脑的,但有小伙伴反馈自己Win10系统的电脑在添加打印机的时候找不到对应的型号,那么遇到这种情况应该怎么办呢?下面就和小编一起来看看解决方法吧。
Win10找不到打印机型号的解决方法
1、按下win键+R键,输入services.msc按下回车。
2、点击管理——服务——找到print spooler。
3、将启动类型改为自动最后点击确定就好啦。
4、如果还是搜不到打印机的话,我们打开浏览器搜索下载FlashPaper。
5、安装成功后,打开设备和打印机界面,点击添加打印机添加虚拟打印机。
6、选择端口为Flashpaper2printerport,打印机名称设置为macromedia flashpaper就好啦。
可参考
1、按下win键+R键,输入services.msc按下回车。
2、点击管理——服务——找到print spooler。
3、将启动类型改为自动最后点击确定就好啦。
4、如果还是搜不到打印机的话,我们打开浏览器搜索下载FlashPaper。
正在上传…重新上传取消
5、安装成功后,打开设备和打印机界面,点击添加打印机添加虚拟打印机。
6、选择端口为Flashpaper2printerport,打印机名称设置为macromedia flashpaper就好啦。
Ubuntu18.04 安装配置Nginx、Https、PHP 前言安装步骤安装 Nginx更新系统软件包安装验证Nginx命令 配置HTTPS创建证书目录上传证书修改Nginx设置,使其支持HTTPS验证 配置PHP环境为 PHP 8.1 添加 PPA安装PHP 8.1 FPM验证安装 PHP 8.1 扩展配置 PHP 8.1 Nginx配置PHP 8.1修改配置验证重启服务器测试 参考文档 前言 朋友趁着618入手一台轻量应用服务器,系统是Ubuntu18.04,需要搭建一个个人网站,本来想帮他装一个我最喜欢的LAMP(Linux + Apache + MySQL +PHP),但是灵机一动,不如尝试一下装个LNMP(Linux + Nginx + MySQL + PHP)试试。
安装步骤 安装 Nginx 更新系统软件包 执行 apt-get update以确保访问最新的软件包。
安装 最后的-y表示全部同意,不需要在后续的安装过程中再输入Y
sudo apt-get install nginx -y 验证 验证正在运行的 Nginx 服务器
sudo systemctl status nginx 若出现以下内容则表示服务已启用
nginx.service - A high performance web server and a reverse proxy server Loaded: loaded (/lib/systemd/system/nginx.
简介 OpenFeign 是Spring Cloud中的一个组件,经常用来在项目中进行Http调用其他服务的接口,在于对服务端接口的绑定。
使用方式是比较简单的,让我们来探究一下使用原理吧!
阅读条件:
要有Spring源码的基础使用过原生的FeignSpringBoot源码基础 源码解析入口:@EnableFeignClients
@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.TYPE) @Documented @Import(FeignClientsRegistrar.class) public @interface EnableFeignClients { String[] basePackages() default {}; Class<?>[] basePackageClasses() default {}; Class<?>[] defaultConfiguration() default {}; Class<?>[] clients() default {}; } 注解里面的参数配置,都可以在官网找到说明,这里就不介绍了。
点进去我们可以在注解上看到这样 一段代码:
@Import(FeignClientsRegistrar.class)
这个是往Spring容器里面注入一个类。
核心在于 FeignClientsRegistrar 实现了 ImportBeanDefinitionRegistrar。
ImportBeanDefinitionRegistrar是Spring中的一个扩展点,实现该接口的方法,我们可以动态的往容器里面注入其他类的信息,然后走Spring的生命周期,创建出Bean。
要说明的一点实现了ImportBeanDefinitionRegistrar的类,该实现类的执行时机在于Spring对配置类的解析阶段执行的,熟悉Spring源码的同学都知道,Spring是先扫描合格的配置类,从配置类中获取要创建Bean的类信息,注册成BeanDefinition简称bd,最后在统一进行实例化。
Spring在解析配置类的时候,会判断该类是否实现了ImportBeanDefinitionRegistrar,是的话就创建对象,执行接口方法,这样也就会执行我们写的自定义逻辑,往容器里面注入bd。
我们直接找到 FeignClientsRegistrar 实现的注入bd方法:
@Override public void registerBeanDefinitions(AnnotationMetadata metadata, BeanDefinitionRegistry registry) { // 对 @EnableFeignClients 解析 registerDefaultConfiguration(metadata, registry); // 对 @FeignClient 解析 registerFeignClients(metadata, registry); } 我们直接看对 @FeignClient 的解析。
目录
目录
1.K8S介绍
2.让数据持久化
3.K8S存储方案
4.K8S的一些组件和功能
5.你知道哪些K8S方面的资源
6.K8S对资源管理对象的监控
7.K8S监控使用什么 有哪些组件
8.Prometheus 的监控体系
9.pod健康状态的检查和探针的区别
10.集群内、外部的pod怎么访问
11.ingress数据链路怎么走向
12.pod重启策略
13.POD状态
14.POD里有哪些东西
不同node节点pod通讯的过程能讲一下嘛
15.简述Kubernetes 创建一个Pod的主要流程?
16.pod的能达到多少
17.node资源限制
18.用户访问服务的流程
19.k8s添加新的node节点
20.K8S集群网络 21.kube-proxy中使用ipvs与iptables的比较
22.压缩镜像
23.namespace怎么使用 namespace之间怎么协做
24.mq做过哪些运维工作
25.一般怎么部署mq
26.ELK日志收集是怎样的链路
27.日志有哪些操作
Calico插件你们了解过么 里面有哪些模式
1.K8S介绍 Kubernetes是一个轻便的和可扩展的开源平台,用于管理容器化应用和服务。通过Kubernetes能够进行应用的自动化部署和扩缩容。在Kubernetes中,会将组成应用的容器组合成一个逻辑单元以更易管理和发现。Kubernetes积累了作为Google生产环境运行工作负载15年的经验,并吸收了来自于社区的最佳想法和实践。Kubernetes经过这几年的快速发展,形成了一个大的生态环境,Google在2014年将Kubernetes作为开源项目。Kubernetes的关键特性包括:
自动化装箱:在不牺牲可用性的条件下,基于容器对资源的要求和约束自动部署容器。同时,为了提高利用率和节省更多资源,将关键和最佳工作量结合在一起。自愈能力:当容器失败时,会对容器进行重启;当所部署的Node节点有问题时,会对容器进行重新部署和重新调度;当容器未通过监控检查时,会关闭此容器;直到容器正常运行时,才会对外提供服务。水平扩容:通过简单的命令、用户界面或基于CPU的使用情况,能够对应用进行扩容和缩容。服务发现和负载均衡:开发者不需要使用额外的服务发现机制,就能够基于Kubernetes进行服务发现和负载均衡。自动发布和回滚:Kubernetes能够程序化的发布应用和相关的配置。如果发布有问题,Kubernetes将能够回归发生的变更。保密和配置管理:在不需要重新构建镜像的情况下,可以部署和更新保密和应用配置。存储编排:自动挂接存储系统,这些存储系统可以来自于本地、公共云提供商(例如:GCP和AWS)、网络存储(例如:NFS、iSCSI、Gluster、Ceph、Cinder和Floker等)。 2.让数据持久化 利用NFS-[pv/pvc]实现k8s持久化存储
上面创建了一个pv 挂在了所有的nginx日志目录是有问题的, nginx日志目录应该单独存储,单独存储nginx日志设置:可手动创建多个pvc进行挂在或者进行 volumeClaimTemplates: 自动创建pvc进行挂在。
3.K8S存储方案 pv与pvc
4.K8S的一些组件和功能 etcd:保存了整个集群的状态
APIServer:提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制
controller-manager:负责维护集群核心对象的状态,比如故障检测、自动扩展、滚动更新
scheduler:负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上
kubelet:负责维持容器的生命周期,同时也负责Volume和网络的管理
kube-proxy:负责为Server提供cluster内部的服务发现和负载均衡
5.你知道哪些K8S方面的资源 1、创建pod资源
2、ReplicationController资源
3、deployment资源
4、service资源
6.K8S对资源管理对象的监控 metrics-server是集群核心监控数据的聚合器,metrics-server提供了/apis/metrics.k8s.io接口,通过这个接口,用户就可以调用集群的资源使用情况。集群中的节点上的kubelet都内置了cAdvisor服务(专门用于采集集群节点上所有资源情况)。只是cAdvisor缺少了merics-server,merics-server能提供一个统一的api接口。该api接口通过使用k8s中的kube-aggregator代理后端来开启一个访问入口。这个代理程序是集群自动开启的。
Metrics-Server是集群核心监控数据的聚合器,用来替换之前的heapster。 容器相关的 Metrics 主要来自于 kubelet 内置的 cAdvisor 服务,有了Metrics-Server之后,用户就可以通过标准的 Kubernetes API 来访问到这些监控数据。Metrics API 只可以查询当前的度量数据,并不保存历史数据。Metrics API URI 为 /apis/metrics.
简介 TypeScript对我们来说可能有点儿陌生,我们可以先简单的了解下JavaScript,它是一种具有函数优先的轻量级,解释型或即时编译型的编程语言,是数据类型可以被忽略的语言,一个变量可以赋不同类型的值,俗称弱类型语言。TypeScript是一种强类型语言。
// JavaScript的demo案例 var a = "abc"; a = 123; console.log(`a: ${a}`); // a: 123 TypeScript的语言特性 与现存的JavaScript代码有非常高的兼容性。TypeScript是JavaScript的超集,意味着任何合法的JavaScript程序都是合法的TypeScript程序(很少有例外)。TypeScript是一种在编译期进行静态类型分析的强类型的程序语言。TypeScript中加入了基于类(Class)的对象、接口和模块,这些特性可以帮助我们以更好的方式构建代码,可以让代码更具可维护性与扩展性。成为跨平台的开发工具。微软使用Apache协议开源了TypeScript,并且它可以在所有主流的操作系统上安装和执行。 强类型程序语言:通过向JavaScript增加可选的静态类型声明来把JavaScript变成强类型程序语言。可选的静态类型声明可约束函数、变量、属性等程序实体,这样编译器和相应的开发工具在开发过程中可以提供更好的正确性验证和帮助功能;能让程序员对自己和团队其他开发人员在代码中清晰地表达他的意图;它的类型检测在编译期进行且没有运行时开销。
想要了解TypeScript的组件介绍及环境搭建,请查看这里
基本类型 基本类型有boolean、number、string、array、void和所有自定义的enum类型。所有这些类型在TypeScript中,都有一个唯一的顶层的Any Type类型的字类型,any关键字代表这种类型。
类型Demo描述booleanlet isDone: boolean = true;boolean类型只可能是两种值。它们分别是true和false。numberconst PI: number = 3.1415926;与JavaScript一样,所有的数字在TypeScript中都是浮点数。stringlet username: string = ‘summer’;
let password: string = “summer”;在代码中使用字符串是将它们放在单引号或者双引号中间。arrayconst list: number[] = [1, 2, 3];
const list : Array = [1, 2, 3];array类型的声明有两种写法。
第一种在数组元素的类型后面跟着[];
第二种是使用泛型数组类型Arrayenumenum TypeEnum {
Success= 0,
Error = 1,
Warning = 2
}
let type = TypeEnum.
1. 背景 插件体系是IDEA的精髓,插件市场里拥有无数开发者提交的插件,这让IDEA拥有了成长的能力。下面我通过一个例子,介绍插件创建、调试和发布的完整过程。
2. 开发步骤 2.1 创建工程 官方推荐2种方式来创建插件工程,一种是基于Github的模板代码,一种是基于Gradle手动配置。我推荐使用Github模板的方式,插件工程clone下来就可以直接执行,对新人比较友好。
2.2.1 模板代码
打开模板的Github地址:https://github.com/JetBrains/intellij-platform-plugin-template。
点击“Use this template”,将项目fork到自己的仓库里,或者直接下载模板代码。 2.2.2 Gradle方式
在new project的时候,选择Gradle->IntelliJ Platform Plugin
2.2 开发插件 IDEA里有一个Intention action(代码推测)功能,快捷键是shift+enter。我们尝试新增一种代码推测,在输入类名后,通过推测自动生成new语句。例如,输入“User”,生成“User user = new User();”。
2.2.1 编写代码(Kotlin)
要新增Intention action功能,就要实现IntentionAction接口,实际代码里是用PsiElementBaseIntentionAction这个抽象类,它已经继承了IntentionAction。功能代码如下,IntentionAction接口里的核心方法是isAvailable()和invoke()方法。isAvailable()是在敲下shift+enter时,判断当前action是否满足执行条件;invoke()是选择aciton后,需要执行的逻辑。
class NewObjectGenerator : PsiElementBaseIntentionAction() { override fun isAvailable(project: Project, editor: Editor, element: PsiElement): Boolean { // 格式User return element is PsiIdentifier && element.parent is PsiJavaCodeReferenceElement } @Throws(IncorrectOperationException::class) override fun invoke(project: Project, editor: Editor, element: PsiElement) { val typeName = element.