图形是呈现数据的一种直观方式,在用Matlab进行数据处理和计算后,我们一般都会以图形的形式将结果呈现出来。尤其在论文的撰写中,优雅的图形无疑会为文章加分。
1、绘制直方图 %% close all clear all clc %% 直方图的绘制 %直方图有两种图型:垂直直方图和水平直方图。而每种图型又有两种表现模式:累计式:分组式。 figure; z=[3,5,2,4,1;3,4,5,2,1;5,4,3,2,5]; % 各因素的相对贡献份额 colormap(cool);% 控制图的用色 subplot(2,3,1); bar(z);%二维分组式直方图,默认的为'group' title('2D default'); subplot(2,3,2); bar3(z);%三维的分组式直方图 title('3D default'); subplot(2,3,3); barh(z,1);%分组式水平直方图,宽度设置为1 title('vert width=1'); subplot(2,3,4); bar(z,'stack');%累计式直方图,例如:1,1+2,1+2+3构成了第一个bar title('stack') subplot(2,3,5); bar3h(z,0.5,'stacked');%三维累计式水平直方图 title('vert width=1 stack'); subplot(2,3,6); bar3(z,0.8,'grouped');%对相关数据的颜色进行分组,默认的位'group' title('width=0.8 grouped'); 2、绘制进阶柱状图 %% close all clear all clc %% =========柱状图的进阶========== figure; y=[300 311;390 425; 312 321; 250 185; 550 535; 420 432; 410 520;]; subplot(1,3,1); b=bar(y); grid on; set(gca,'XTickLabel',{'0','1','2','3','4','5','6'}) legend('算法1','算法2'); xlabel('x axis'); ylabel('y axis'); %使仅有的一组柱状图呈现不同颜色,默认的位相同颜色 data = [1.
当我们的代码中需要一个小图标的时候没必要去iconfont进行下载图标使用
要是下载的png格式那么容量还很大 远不如svg
直接自己代码写
记住svg的坐标朝向和数学坐标轴不一样
实现下图添加的小图标
<svg width="20px" height="20px" style="border: 1px solid red"> <!-- x1 y1 线段的起始坐标 x2 y2线段的终点坐标 stroke-width 线段的宽度 stroke="线的颜色" --> <line x1="0" y1="10" x2="20" y2="10" stroke-width="1" stroke="red"></line> <line x1="10" y1="0" x2="10" y2="20" stroke-width="1" stroke="red"></line> </svg> 注意颜色
stroke="red" 是直接应用为红色 stroke="currentColor" 是找的父级的元素上的color来使用 <div class="test"> <svg width="20px" height="20px" style="border: 1px solid red; color: blue"> //currentColor指向的是父级的颜色此时为svg的color :blue (currentColor父级的父级的颜色对他没影响) // 如果currentColor父级没有颜色color那么在继续往上找 <line x1="0" y1="10" x2="20" y2="10" stroke-width="1" stroke="currentColor" ></line> <line x1="10" y1="
组件注册 局部组件
创建一个组件.vue引入:import Mycomp from ‘./components/Mycomp.vue’注册组件
export default {
name: ‘App’,
components: {
Mycomp
}
}使用组件
组件组成
template 视图script 逻辑style 样式 全局组件
注册全局组件 在Vue对象身上有个Vue.component() 注册全局组件 在所有的组件中 不需要引入 可以直接使用
语法:
Vue.component(‘my-component-name’, {
// … 选项 …
})
代码演示
// import Vue from 'vue'//运行时:vue.runtime.js import Vue from 'vue/dist/vue' /注册全局组件 // Vue.component('组件名称',{内容配置}) Vue.component('my-comp',{ //视图 template :template作为属性使用 必须vue.js (完整版的vue.js) 默认引入-运行时-vue.runtime.js template:'<div> <h2>我是一个全局组件</h2> <p>{{ msg }}</p></div>', //数据 data(){ return { msg:'hello vue全局组件' } }, //方法 methods:{ } }) 全局组件–可以挂载创建好的局部组件 注册全局
使用指令:conda update -n base conda,更新conda时,提示无写入权限。
EnvironmentNotWritableError: The current user does not have write permissions to the target environment.
environment location: C:\ProgramData\Anaconda3
EnvironmentNotWritableError: The current user does not have write permissions to the target environment. environment location: C:\ProgramData\Anaconda3 …
在开始-应用程序中,右键点击”Anaconda Prompt (Anaconda3)”,选择“以管理员身份运行”。即以管理员身份运行Anaconda Prompt。
再次运行指令:conda update -n base conda。
conda更新成功。
查看Anaconda已配置环境的路径,并在PyCharm中更新编译环境 Anaconda配置好环境(以neroic为例)后,在PyCharm中更新编译环境。
选中新建的环境neroic,点击环境的右侧类似播放符号的绿色按钮,弹出菜单项,选择“Open Terminal”。
弹出cmd对话框,自动执行指令conda.bat activate "C:\Users\Admin.conda\envs\neroic"
C:\Users\Admin.conda\envs\neroic,即为配置环境的路径。
在文件浏览器中,访问该路径,包含有安装完成的相关库。里边有编译器文件python.exe
在PyCharm右底部,点击编译器Python 3.*,弹出对话框中选择Add New Interpreter。
在对话框“Add Python Interpreter”中,选择Environment的已有项"Existing",点击右侧**按钮"…“**,在弹出的对话框中,展开至配置环境Neroic的路径"C:\Users\Admin.conda\envs\neroic”,选择python.exe文件。
目录
前言
一、基本要求
二、流程图
三、代码
1.类的创建 2.录入图书信息
3.删除图书信息
4.插入图书信息
5.查找图书信息
6.整体代码
总结
前言 先来一张效果图
一、基本要求 图书信息管理系统能实现以下功能:系统以菜单方式工作,图书信息录入功能(图书信息用文件保存) ;图书信息包括:登录号、书名、作者名、分类号、出版单位、出版时间、 价格;图书信息浏览功能(输出所有图书信息);查询和排序功能:按书名查询(显示所有同名的书),按作者名查询(所有该作者的书); 图书信息的删除,插入与修改。输入其他任意字符(错误输入)会显示其错误输入的输出结果。
二、流程图 界面显示菜单,通过用户的输入,switch进行判断调用相应的方法,显示相应的信息,结束这个功能后,界面显示询问:“继续吗?”,用户输入,若是取消,则退出系统;若是确定,则刷新页面,显示菜单。
三、代码 1.类的创建 一共创建了两个类。book类存放图书的各种信息,library类存放每本图书的对象,单链表指针(即library类的对象的地址)和各种功能。
class book { public: char name[100]; char num[100]; char tel[100]; char name1[100]; char time[100]; char cla[100]; char adress[100]; }; class library { public: book data;//对象 library *next;//单链表指针 void londecreat(library L, int n);//录入信息 void display();//显示信息 void sort();//排序信息 void findname(char* arr);//查找作者名 void findbook(char* arr);//查找图书名 void delete1(library &L, char* arr);//删除信息 void modify(library &L, char* arr, char* arr1, char* arr2, char* arr3, char* arr4, char* arr5, char* arr6, char* arr7);//修改信息 void insert(library &L, char* arr, char* arr2, char* arr3, char* arr4, char* arr5, char* arr6,char* arr7,char* arr8);//插入信息 }; 2.
一个混迹于Github、Stack Overflow、开源中国、CSDN、博客园、稀土掘金、51CTO等 的野生程序员。
目标:分享更多的知识,充实自己,帮助他人
GitHub公共仓库:https://github.com/zhengyuzh
以github为主:
1、分享前端+后端基础知识
2、前后端框架知识+框架使用分析
3、热门前端+后端面试题(实时更新)
4、开源项目(主要包含大学课程设计)
文章目录 1、默认主题2、修改2.1 打开终端2.2 选择配置文件首选项2.3 取消默认、自定义颜色2.4 效果展示 3、后语 1、默认主题 是这种白色的、我是看不习惯、总感觉少点啥、看文本也不方便、白花花的一片
2、修改 2.1 打开终端 鼠标在桌面右键、打开终端、选择编辑
2.2 选择配置文件首选项 2.3 取消默认、自定义颜色 2.4 效果展示 3、后语 学无止境。。。。。。
系列文章目录 DIY NAS服务器之OMV 5.6入坑指南(一)-openmediavalut 5.6安装
DIY NAS服务器之OMV 5.6入坑指南(二)- 安装omv-extras插件
DIY NAS服务器之OMV 5.6入坑指南(三)- 切换系统源
DIY NAS服务器之OMV 5.6入坑指南(四) -安装docker和Portainer
DIY NAS服务器之OMV 5.6入坑指南(五) -数据同步及管理
目录
系列文章目录
一、DIY NAS服务器
装机清单:
二、NAS系统选择
三、安装OMV 5.6
(1)下载OMV 系统文件
(2)制作U盘启动盘(U盘安装盘)
(3)安装OMV
这里写几个踩过的坑:
一、DIY NAS服务器 百度网盘里攒了一堆电影、电视剧,想下载到电脑里,买了个4T硬盘,然后发现不够用,然后又买了个还是不够用,然后自己又不想开电脑看电视电影,平时看电视电影都是在ipad上看的,台式电脑800年难得开一台,觉得开机关机比较费劲。
很早就听过家用(或个人)NAS储存了。在某东、某宝看了群晖、威联通的成品NAS服务器,发现盘位小的自己又看不上,盘位多的又太贵,对一个会DIY电脑的IT码农来说,买(主)成(要)品(是)的(穷)性(流)价(下)比(了)确(没)实(钱)太(的)低(泪)了(水)。
网上也有很多组装NAS服务器的教程和资料,某鱼上面也有很多用矿渣DIY的成品、半成品的NAS服务器,翻了很久,也看了很久,都不是我想要的,然后看了张大妈(smzdm)上@阿文菌的《文菌装NAS 篇一:手把手教您组装一台2021年全能NAS,ALL IN ONE 配置清单,可抄作业》,决定以他这个配置清单为模板,自己攒台NAS服务器。
装机清单: 序号
项目
型号
备注
其他
1
CPU
i3-10105
带核显
2
主板
华硕 TUF GAMING B460M PRO
M-ATX板,24.5*24.5
本来是要买TUF GAMING B460M PLUS,买回来才发现是PRO,这2个好像都是重炮手,坑爹。算是买翻车了吧
3
电源
航嘉300W 白牌80 PLUS 电源
系列文章目录 DIY NAS服务器之OMV 5.6入坑指南(一)-openmediavalut 5.6安装
DIY NAS服务器之OMV 5.6入坑指南(二)- 安装omv-extras插件
DIY NAS服务器之OMV 5.6入坑指南(三)- 切换系统源
DIY NAS服务器之OMV 5.6入坑指南(四) -安装docker和Portainer
DIY NAS服务器之OMV 5.6入坑指南(五) -数据同步及管理
目录
系列文章目录
前言
开启社区插件omv-extras
前言 前面我们已经安装好了OMV5.6了。
接下来就是建设我们的OMV系统了。
开启社区插件omv-extras 首先第一步,我们开启社区插件omv-extras:
通过如下url把插件安装文件 下载到电脑本地,通过OMV web管理页面的插件菜单通过上传的方式安装:
http://omv-extras.org/openmediavault-omvextrasorg_latest_all5.deb
上传成功后,在插件菜单中可以找到刚刚上传的社区插件,选中,然后安装即可:
如下是通过命中的方式安装社区插件的方法,比较折腾:
1、通过SSH方式登陆到OMV
2、切换到root用户
sudo su
3、执行如下命令:
wget -O - https://github.com/OpenMediaVault-Plugin-Developers/packages/raw/master/install | bash
如下提示如下错误:
wget: 无法解析主机地址 “github.com”
一般是DNS有问题,可以使用如下方式设置一下:
方法一:使用谷歌提供的DNS服务:
echo 'nameserver 8.8.8.8'>>/etc/resolv.conf
方法二:使用阿里巴巴提供的DNS域名解析
echo 'nameserver 223.5.5.5'>>/etc/resolv.conf
或
echo 'nameserver 223.6.6.6'>>/etc/resolv.conf
设置完DNS域名解析服务后,重新执行开启社区插件的命令。
如果提示如下错误:
无法建立 SSL 连接。
系列文章目录 DIY NAS服务器之OMV 5.6入坑指南(一)-openmediavalut 5.6安装
DIY NAS服务器之OMV 5.6入坑指南(二)- 安装omv-extras插件
DIY NAS服务器之OMV 5.6入坑指南(三)- 切换系统源
DIY NAS服务器之OMV 5.6入坑指南(四) -安装docker和Portainer
目录
系列文章目录
前言
一、LVM 逻辑卷管理器
二、个人选择
前言 本节主要为关于NAS服务器 储存管理方式的选择和思考。
一、LVM 逻辑卷管理器 LVM 逻辑卷管理器 可以理解成存储池。方便扩充和管理磁盘空间。
关于LVM 逻辑卷管理器更多介绍可以参考:https://tvtv.fun/pc-to-nas/6th.html
二、个人选择 关于NAS储存磁盘空间的管理,可根据个人实际需求和喜好决定。
个人最终决定不安装LVM 逻辑卷管理器 及磁盘阵列,直接使用磁盘,采用软件对重要数据进行备份。
图片自动同步工具:
Resilio Sync
同类应用还有Syncthing
nextcloud文件同步功能
抓包测试:
将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,也用来检查网络安全。抓包也经常被用来进行数据截取等。
抓包工具介绍:
Chrome/Firefox 开发者工具: 浏览器内置,方便易用Fiddler/Charles: 基于代理的抓包,功能强大,可以手机抓包,模拟弱网,拦截请求,定制响应 Fiddler: 免费,只支持WinCharles: 收费,支持Win/Linux/Mac wireshark/tcpdumps:给予网卡层的抓包,数据量大,可以抓取tcp/udp等多种协议的数据包(需要做好过滤) wireshark: 支持Win/Linux/Mactcpdumps: Linux抓包命令,功能强大,常用作服务端抓包 原理:
模拟代理服务器
客户端-->代理服务器-->服务端
服务器-->代理服务器-->客户端
主要用途:
1、断请求,断响应
2、定位bug
3、模拟弱网
4、抓取请求,转换成jmx文件进行压测
常见使用场景:
1、移动端验证 :协助定位bug、模拟弱网,进行弱网测试
2、断响应:修改返回结果,达到验证目的
3、mock local :修改返回数据,达到验证目的(常用来修改大量数据)
重点是给大家提供一个思路,在某些情况下,可以通过抓包工具修改返回参数以达到验证目的
1、安装&破解(推荐使用稳定版本:v4.1.4)
官方下载地址:Download a Free Trial of Charles • Charles Web Debugging Proxy
破解方式:
help-->register charles
* https://zhile.io
* 48891cf209c6d32bf4
关闭防火墙!!!
2、抓取http请求
** 设置charles允许代理 proxy-->proxy setting -->勾选enable....
HTTP与HTTPS
HTTP协议传输的数据都是未加密的,HTTPS协议是由HTTP+SSL协议构建的可进行加密传输、身份认证的网络协议,要比HTTP协议安全。
HTTPS和HTTP的区别
HTTPS协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
HTTP是超文本传输协议,信息是明文传输,HTTPS则是具有安全性的SSL加密传输协议。
HTTP和HTTPS使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
HTTP的连接很简单,是无状态的;HTTPS协议是由HTTP+SSL协议构建的可进行加密传输、身份认证的网络协议,比HTTP协议安全。
3、抓取https请求
*安装CA证书
安装证书到电脑,并且信任证书:
help-->ssl setting-->install charles .
员工管理系统的设计与实现
摘 要
由于数据库和数据仓库技术的快速发展,企业员工管理系统建设越来越向模块化、智能化、自我服务和管理科学化的方向发展。员工管理系统对处理对象和服务对象,自身的系统结构,处理能力,都将适应技术发展的要求发生重大的变化。企业员工管理管理系统除了具有共享系统的全部功能以外,能通过对数据的分析对决策做出解释是其主要的新特点。其体系结构,将由专用的服务器/客户方式向广域网发展,使更多的系统间能够互相交流数据,带动整个行业、领域知识和效率的极大提升。
员工管理管理系统主要功能模块包括部门管理、员工考勤、员工加班、员工工资、疫苗接种、员工请假、通知公告等,采取面对对象的开发模式进行软件的开发和硬体的架设,能很好的满足实际使用的需求,完善了对应的软体架设以及程序编码的工作,采取Mysql作为后台数据的主要存储单元,采用springboot框架、Java技术、Ajax技术进行业务系统的编码及其开发,实现了本系统的全部功能。本次报告,首先分析了研究的背景、作用、意义,为研究工作的合理性打下了基础。针对员工管理管理系统的各项需求以及技术问题进行分析,证明了系统的必要性和技术可行性,然后对设计系统需要使用的技术软件以及设计思想做了基本的介绍,最后来实现员工管理管理系统的部署与运行。
关键词:员工管理;springboot框架;MySQL数据库
Design and implementation of employee management system
system
Abstract
Due to the rapid development of database and data warehouse technology, the construction of enterprise employee management system is becoming more and more modular, intelligent, self-service and scientific management. The employee management system will make significant changes to the processing objects and service objects, its own system structure and processing capacity to meet the requirements of technological development.
以下命令均在/home目录下操作cd /home #进入/home目录
1、把/home目录下面的data目录压缩为data.zip
zip -r data.zip data #压缩data目录
2、把/home目录下面的data.zip解压到databak目录里面
unzip data.zip -d databak
3、把/home目录下面的abc文件夹和123.txt压缩成为abc123.zip
zip -r abc123.zip abc 123.txt
4、把/home目录下面的www.zip直接解压到/home目录里面
unzip www.zip
5、把/home目录下面的abc12.zip、abc23.zip、abc34.zip同时解压到/home目录里面
unzip abc*.zip
6、查看把/home目录下面的www.zip里面的内容
unzip -v www.zip
7、验证/home目录下面的www.zip是否完整
unzip -t www.zip
1 什么是晶振 晶振一般指石英晶体振荡器,也叫晶体振荡器 晶体振荡器是指从一块石英晶体上按照一定的方位角切下来的薄片(晶片),是时钟电路中最重要的部件
2 晶振的作用 提供基本的时钟信号:通常情况下,一个系统都会共用一个晶振,这样主要是为了方便每个部分能够保持同步一致。比如有些通讯系统的基频以及射频使用不同的晶振,通过电子来调整频率保证同步
提供系统所需时钟频率:晶振通常与锁相环电路配合使用,以提供系统所需的时钟频率。如果不同子系统需要不同频率的时钟信号,可以用与同一个晶振相连的不同锁相环来提供
3 晶振的原理 3.1 压电效应 若在石英晶体的两个电极上加上一电场,晶片就会产生机械变形。反之,若在晶片的两侧施加机械压力,则在晶片相应的方向上将产生电场,这种物理现象称为压电效应 晶振是利用石英晶体的压电效应制成的一种谐振器件,在一般情况下,晶片机械振动的振幅和交变电场的振幅非常微小,但当外加交变电压的频率为某一特定值时,振幅明显加大,比其他频率下的振幅大得多,这种现象称为压电谐振
4 晶振的分类 4.1 按材质分类 4.1.1 石英晶振 石英晶振就是用石英材料做成的石英晶体谐振器,俗称晶振。尽管石英晶振的应用已有几十年的历史,但因其具有频率稳定度高这一特点,故在电子技术领域中一直占有重要的地位
特点:
起振时间长,通电后较长时间才会起振,毫秒级
压电体构成,无内置电容
精度高
4.1.2 陶瓷晶振 陶瓷晶振是根据他内部的芯片采用的“压电陶瓷芯片材料”而得名的
特点:
起振时间短,通电立马起振,纳秒级
有压电体和内置电容构成,
精度低
4.2 按属性分类 这里的“源”是指 振荡器oscillator 4.2.1 无源晶振 无源晶振是有2个引脚的无极性元件,需要借助于时钟电路才能产生振荡信号,自身无法振荡起来;
无源晶振需要用DSP片内的振荡器,在datasheet上有建议的连接方法。无源晶振没有电压的问题,信号电平是可变的,也就是说是根据起振电路来决定的,同样的晶振可以适用于多种电压,可用于多种不同时钟信号电压要求的DSP
无源晶振信号质量较差,通常需要精确匹配外围电路(用于信号匹配的电容、电感、电阻等),如下图:
这两个电容一般称为“匹配电容”或者“负载电容”、“谐振电容”;晶振电路中加这两个电容是为了满足谐振条件。一般外接电容,是为了使晶振两端的等效电容等于或接近负载电容。只有连接合适的电容才能满足晶振的起振要求,晶振才能正常工作。
负载电容的值由如下公式计算:
其中CL为晶振的负载电容值,可通过查询晶振的数据手册获得,CS表示PCB板的寄生电容,一般为3~5pF;一般情况下,增大负载电容的值会使振荡频率下降,减小负载电容的值,会使振荡频率上升
4.2.2 有源晶振 有源晶振有4只引脚,是一个完整的振荡器,其中除了石英晶体外,还有晶体管和阻容元件
有源晶振通常的用法:一脚悬空,二脚接地,三脚接输出,四脚接电压。有源晶振不需要CPU的内部振荡器,连接方式相对简单(主要是做好电源滤波,通常使用一个电容和电感构成的PI型滤波网络,输出端用一个小阻值的电阻过滤信号即可),不需要复杂的配置电路。相对于无源晶体,有源晶振的缺陷是其信号电平是固定的,需要选择好合适输出电平,灵活性较差
声明:本篇文章主要转载自:你还在用 findViewById 吗?
官方API findViewById TextView tvCenter = findViewById(R.id.tv_center); tvCenter.setText("Text Change"); 开源库ButterKnife 虽然方式一简单又好用,但是当控件很多的时候,就会出现一大堆的findViewById。
比如这样:
TextView tv1; TextView tv2; TextView tv3; TextView tv4; TextView tv5; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); tv1 = findViewById(R.id.tv1); tv2 = findViewById(R.id.tv2); tv3 = findViewById(R.id.tv3); tv4 = findViewById(R.id.tv4); tv5 = findViewById(R.id.tv5); } 而使用开源库ButterKnife,就很清爽。
关于ButterKnife绑定控件id,看这篇:ButterKnife
DataBinding 首先需要对 module 所在的 build.gradle 做更改,修改配置如下:
android { ... dataBinding { enabled = true } } 接着在布局外面套一层 layout,如下:
<?xml version="
一、什么是ButterKnife? 通俗来讲:
就是一个替代findViewById()的第三方库。
不用ButterKnife库,就要写很多的findViewById()来绑定控件,用ButterKnife就可以省去这些步骤。
并且使用ButterKnife对性能基本没有损失。
Github地址:https://github.com/JakeWharton/butterknife
二、使用方式 首先,添加依赖:
implementation 'com.jakewharton:butterknife:10.2.3' annotationProcessor 'com.jakewharton:butterknife-compiler:10.2.3' 使用BindView注解,绑定控件:
@BindView(R.id.tv) TextView tv; 然后在onCreat里面写:
ButterKnife.bind(this); 这里的this是你的控件要绑定的Activity,比如这的this,就是指MainActivity。写成MainActivity.this效果是一样的。
下面是完整代码:
三、其他 ButterKnife库还有很多其他的用法,例如:绑定控件id、Adapter中ViewHolder使用、绑定Button点击事件等等。
但是个人感觉最有用的还是上面的这个,其它功能,有需要请参考以下文章:
ButterKnife(黄油刀)基本使用与源码解析
ButterKnife使用方法详解
查看 k8s版本
使用kubectl version 命令,输出的信息会显示client和server的版本信息,client代表kubectl版本信息,server代表的是master节点的k8s版本信息
kubectl version kubelet --version kube-apiserver --version 等
升级准备 1.23.1升级到1.23.5
下载升级包
k8s_version=v1.23.5
wget https://dl.k8s.io/${k8s_version}/kubernetes.tar.gz
wget https://dl.k8s.io/${k8s_version}/kubernetes-client-linux-amd64.tar.gz
wget https://dl.k8s.io/${k8s_version}/kubernetes-server-linux-amd64.tar.gz
wget https://dl.k8s.io/${k8s_version}/kubernetes-node-linux-amd64.tar.gz
解压
tar xf kubernetes-1.23.5-client-darwin-amd64.tar.gz -C /usr/local/src
tar xf kubernetes-1.23.5-node-linux-amd64.tar.gz -C /usr/local/src
tar xf kubernetes-1.23.5-server-linux-amd64.tar.gz -C /usr/local/src
tar xf kubernetes-1.23.5.tar.gz -C /usr/local/src
复制升级文件到安装位置
cd /usr/local/src/kubernetes/server/bin/ #/usr/local/src/ 该地址为刚才指定解压地址
修改负载均衡规则 在所有节点执行
vim /etc/kube-lb/conf/kube-lb.conf #注释掉你需要升级的 master节点 如下图 重启 lb
systemctl restart kube-lb.service 停服务
master:
systemctl stop kube-apiserver kube-controller-manager kube-scheduler kube-proxy kubelet
springboot常用注解: https://github.com/mxg133/learnforSpringBoot
注解解释@SpringBootApplication来标注一个主程序类,说明这是一个springboot应用。@RequestMapping(“/hello”)接收来自于浏览器的hello请求,给出外界访问方法的路径,或者说触发路径 ,触发条件。@RequestBody@RequestBody除了把return的结果变成JSON对象返回,还可以把前端传输过来的json数据自动装配成后端可操作的map对象或自定义对象。@ResponseBody用@ResponseBody标记Controller类中的方法。把return的结果变成JSON对象返回,把类的方法返回的数据写给浏览器。(如果没有这个注解,这个方法只能返回要跳转的路径即跳转的html/JSP页面。有这个注解,可以不跳转页面,只返回JSON数据)。@Controller@Controller标识的类,该类代表控制器类(控制层/表现层)。@RestController是==@Controller和@ResponseBody==的结合。@Repository作用于数据访问层。@Service作用于业务逻辑层。@SpringBootConfigurationSpringBoot的配置类,标注在某个类上,表明这是一个SpringBoot的配置类。@EnableAutoConfiguration开启自动配置。@AutoConfigurationPackage自动配置包,将主配置类(@SpringBootApplication标注的类)的所在包及所有子包里的所有组件扫描到spring容器里。@Import()给容器导入组件。@ConfigurationProperties(prefix=“person”)将配置文件中配置的每一个属性,映射到这个组件中,告诉springboot将本类中的所有属性和配置文件中相关的配置进行绑定;prefix前缀,将配置文件中的"person"下的属性映射进来。@Component把该组件注入springboot容器。作用于实体类或者工具类。@PropertySource({“classpath:xxx.properties”})加载指定的properties配置文件。@Configuration指明当前类是一个配置类,就是用来替代之前的spring配置文件,可以和@Bean搭配使用。@EnableWebMvc加上这个注解,将使所有SpringMVC的自动配置失效,使用自己的配置。@Async告诉Spring这是一个异步方法@RequestMapping@RequestMapping可以指定GET、POST请求方式@GetMapping@GetMapping等价于@RequestMapping的GET请求方式@ImportResourcespringboot默认使用Java配置,但也可以使用xml配置,只需通过该注解引入一个xml配置。 @PathVariable
@PathVariable绑定URI模板变量值
@PathVariable是用来获得请求url中的动态参数的
@PathVariable用于将请求URL中的模板变量映射到功能处理方法的参数上。//配置url和方法的一个关系
@RequestMapping(“item/{itemId}”)
@RequestMapping 来映射请求,也就是通过它来指定控制器可以处理哪些URL请求,类似于struts的action请求。
@responsebody 表示该方法的返回结果直接写入HTTP responseBody中一般在异步获取数据时使用,在使用@RequestMapping后,返回值通常解析为跳转路径,加上@responsebody后返回结果不会被解析为跳转路径,而是直接写入HTTP responseBody中。比如异步获取json数据,加上@responsebody后,会直接返回json数据。
@Pathvariable 注解绑定它传过来的值到方法的参数上用于将请求URL中的模板变量映射到功能处理方法的参数上,即取出uri模板中的变量作为参数
@RequestMapping("/zyh/{type}") public String zyh(@PathVariable(value = "type") int type) throws UnsupportedEncodingException { String url = "http://wx.diyfintech.com/zyhMain/" + type; if (type != 1 && type != 2) { throw new IllegalArgumentException("参数错误"); } String encodeUrl = URLEncoder.encode(url, "utf-8"); String redirectUrl = MessageFormat.format(OAUTH_URL, WxConfig.zyhAppId, encodeUrl, "snsapi_userinfo", UUID.randomUUID().toString().replace("-", "")); return "redirect:" + redirectUrl;m } 在SpringMVC后台控制层获取参数的方式主要有两种:
一种是request.getParameter(“name”),另外一种是用注解@RequestParam直接获取
这里主要讲这个注解 @RequestParam
本篇文章包含的内容 一、输入捕获1.1 输入捕获简介1.2 输入捕获通道的工作原理1.3 输入捕获的主从触发模式1.4 输入捕获和PWMI结构 二、频率的测量方法2.1 测频法2.2 测周法2.3 测频法和测周法的误差分析 三、输入捕获测量PWM波形的频率和占空比3.1 输入捕获相关库函数3.2 输入捕获IC测量频率3.3 PWMI模式同时测量频率和占空比3.4 测周法测量频率性能评估 本次课程采用单片机型号为STM32F103C8T6。
课程链接:江科大自化协 STM32入门教程
往期笔记链接:
STM32学习笔记(一)丨建立工程丨GPIO 通用输入输出
STM32学习笔记(二)丨STM32程序调试丨OLED的使用
STM32学习笔记(三)丨中断系统丨EXTI外部中断
STM32学习笔记(四)丨TIM定时器及其应用(定时中断、内外时钟源选择)
STM32学习笔记(五)丨TIM定时器及其应用(输出比较丨PWM驱动呼吸灯、舵机、直流电机)
如果上一篇笔记的内容为史诗级副本,本篇文章的内容我愿称之为传说级副本(三)。
一、输入捕获 1.1 输入捕获简介 输入捕获,即Input Capture,英文缩写为IC。输入捕获模式下,当通道输入引脚出现指定电平跳变(可以定义为上升沿、下降沿)时,当前CNT的值将被锁存到CCR中(这就是“捕获”的含义),可用于测量PWM波形的频率、占空比、脉冲间隔、电平持续时间等参数。在这里,“脉冲间隔、电平持续时间”和“频率、占空比”是互相对应的关系。每个高级定时器和通用定时器都拥有4各输入捕获通道,且二者没有区别。
输入捕获模块可以配置为PWMI(PWM输入)模式和主从触发模式。PWMI模式是专门用来同时测量PWM波形的频率和占空比的。主从触发模式可以实现对频率或占空比的硬件的全自动测量,不占用软件资源,可以极大地减轻CPU的压力。
在定时器中,输入捕获和输出比较共用同一个引脚和同一个CCR,故在使用时,对同一个TIM定时器而言,输入捕获和输出比较功能只能使用一个,不能同时使用。
1.2 输入捕获通道的工作原理 接下来分析输入捕获通道的工作原理。输入信号首先进入输入滤波器和边沿检测器。这个滤波器和定时器的外部时钟模式2的输入滤波原理类似,它可以避免一些高频的毛刺信号造成误触发。在博主的文章STM32学习笔记(四)丨TIM定时器及其应用(定时中断、内外时钟源选择)中有较为详细的说明:
在定时器的外部信号输入引脚一般都有一个滤波器来消除信号的抖动干扰,它的工作原理是:在一个固定的时钟频率 f f f下进行采样,如果连续 N N N个采样点都是相同的电平,就代表输入信号稳定了,就将采样值输出到下一级电路;如果 N N N个采样点不全都相同,就说明信号有抖动,这时保持上一次的输出,或直接输出低电平。 这样就能保证输出信号在一定程度上的滤波。这里的采样频率 f f f和采样点数 N N N都是滤波器的参数,频率越低,采样点数越多,滤波效果就越好,不过相应的信号延迟就越大。
在实际应用时,通过改变TIMx_CCMR1寄存器的IC1F位就可以配置不同的滤波频率。
边沿检测部分和外部中断类似,可以选择高电平触发,或者低电平触发。当触发指定的电平时,边沿检测电路就会触发后续的电路执行动作。
在CH1,CH2,CH3之间跨接了一个异或门,它实际上是为三相无刷电机服务的。无刷电机拥有三个霍尔传感器检测转子的位置,可以根据转子的位置进行换相,通过将异或门的三个输入端与三个霍尔传感器相连接,此时的定时器就称为无刷电机的接口定时器,取驱动换相电路工作。这部分内容暂时不涉及,仅作了解即可。
CH3、CH4的输入滤波和边沿检测电路的结构与CH1、CH2类似。图中用一个方框代表了输入滤波和边沿检测,但实际上这里有两套相同的电路结构。CH1通道的一个输入滤波和边沿检测接到TI1FP1(Timer Input 1 Filter Polarity 1,可连接到IC1),另一个输入滤波和边沿检测接到TI1FP2(Timer Input 1 Filter Polarity 2,可连接到IC2);同样,CH2通道的一个输入滤波和边沿检测接到TI2FP1(可连接到IC1),另一个输入滤波和边沿检测接到TI1FP2(可连接到IC2)。这样“交叉连接”的目的主要有以下两点:
大家好,我是早九晚十二,目前是做运维相关的工作。写博客是为了积累,希望大家一起进步!
我的主页:早九晚十二
在重启docker服务时,常常会拖家带口一大堆废弃的容器一起启动,如何改正这种现象呢?
服务启动【容器跟随启动】 要想做到docker启动,容器跟随启动可添加以下参数实现
docker run –restart=always 如果容器已经启动,也可以实时设置
docker update –restart=always <CONTAINER ID> 服务启动【容器不跟随启动】 对容器关闭自启命令如下
docker update --restart=no <CONTAINER ID> 批量关闭自启
docker update --restart=no $(docker ps -a -q) docker-compose自启配置 在docker-compose.yaml对应的容器配置添加如下参数
之后重启即可
docker-compose down docker-compose up -d
在日常生活当中,电脑录屏的使用场景也变得越来越多了起来,网课录制,微课录制,直播录制,会议录制等等。那么问题来了,电脑怎么录制屏幕视频呢?今天小编就向大家分享3个电脑录制屏幕视频的方法,一键就能搞定,快来看看吧。
电脑录制屏幕视频方法1:Xbox Game Bar 很多小伙伴不知道电脑怎么录制屏幕视频,其实小伙伴使用的电脑如果是Windows系统的话,可以使用Windows自带的录屏软件,就是Xbox Game Bar进行录制。
录制的方法很简单,只需要使用快捷键“win+g”唤出Xbox Game Bar,接着点击上面的实心白色小圆圈,即可开始录制,一键录制,十分方便!
电脑录制屏幕视频方法2:QQ录屏 QQ录屏也是电脑录制屏幕视频的方法之一,还在苦恼电脑怎么录制屏幕视频的小伙伴,可以尝试使用QQ录屏哦!
操作方法上,需要在键盘上同时按下快捷键“Ctrl+Alt+S”,选择录制的区域,点击开始录制就可以了。录制操作简单,界面简洁清爽,还不需要下载额外的软件就可以录制,十分好用。
电脑录制屏幕视频方法3:数据蛙录屏软件 上面向小伙伴介绍了Xbox Game Bar和QQ录屏的方法,但是Xbox Game Bar不能录制电脑桌面,QQ录屏又不能录制摄像头,除了这2种方法以外,电脑怎么录制屏幕视频?
其实我们可以使用数据蛙录屏软件来录制电脑屏幕视频,这是一款专业免费好用的录屏软件。它的界面清爽简洁,没有任何广告,体积很小,功能却很强大。
内置了丰富的录屏模式,没接触过的小白也能一键轻松录制,并且整体的录制过程十分流畅,能够录制高清无水印的视频。
最关键的是,它的录制时免费录制的,不像其他的录屏软件,动则仅能录制一两分钟,它是不限制录制时长,哪怕一整天都能进行录制。
录制步骤:
步骤1:进入软件主界面后,选择自己需要的录制模式,这里小编选择了【视频录制】的录制模式,作为演示的具体展示。
步骤2:进入【视频录制】的基础设置界面后,选择录制的区域,排除的窗口,接着调整摄像头、扬声器和麦克风,最后点击REC,开始录制。
步骤3:录制结束后,点击右下方【完成】,对录制的视频进行保存。
以上就是小编分享的关于电脑怎么录制屏幕视频的全部内容了。怎么样,是不是觉得非常的简单呢?电脑录制屏幕视频,小伙伴可以根据自己喜欢的,选择适合自己的录制方法哦!小编的话,更喜欢使用数据蛙录屏软件,录制简单方便,录制出来的视频流畅不卡顿,音画同步,特别的棒!
骨架屏是为了展示一个页面骨架而不含有实际的页面内容,从渲染效率上来讲,骨架屏它并不能使首屏渲染加快。由于骨架屏的一些使用又向用户渲染了额外的一些内容,这些内容是额外添加的、本来是不需要渲染的,它反而从整体上加长了首屏渲染的一个时长。
为了避免白屏现象的一个出现,可以这样优化:开发者可以在这个数据完成加载之前使用骨架屏和Loading提示,在这个数据完成之后将骨架屏和Loading做不渲染的一个处理,再展示真正的一个页面内容。
一般具体的做法是这样:
在数据源对象中设定一个loading提示变量值并将初始值设置为true;数据加载完成以后再将loading变量通过setData方法设置为false;在WXML这个页面里面通过loading变量切换骨架屏内容以及Loading提示还有真正页面内容的一个显示。 生成骨架屏的方法: 1、点击生成骨架屏,小程序会自动生成两个文件(骨架屏);
2、按照文件提示,京创建好的文件引入对应文件中;
3、在接口调用完成之后将loading设置为false,使骨架屏不显示;
效果如下:
补充:有时候可能会出现实际的页面和骨架屏发生重影的现象,可以在实际页面的view标签上加一个wx:else的条件,使骨架屏和世界页面不会同时出现。
在使用骨架屏时有三点需要注意:
第一点在data数据对象中默认设置loading等于true;第二点就是不要直接修改生成的骨架屏的一个代码;第三点就是不要过度去使用骨架屏:一般只给主页去添加骨架屏效果,因为骨架屏是小程序提供的一种优化用户体验的一个机制,但其实任何的一个渲染都有消耗,骨架屏也是。
前言: 锁,作为线程间/进程间系统资源,在应对“多线程” 访问相同 “资源” 场景时,扮演重要角色。用得好,可以有效地为系统解耦各个模块;但是如果用的不好,一来可能造成系统效率低下( 某条并不重要的流水线长期占据资源锁,另外重要的流水线始终无法获得访问资源的权利 ),二来可能导致系统死锁。
自旋锁: 自旋锁一般用在内核中,其逻辑行为是:“使用cpu反复执行获取锁的动作,直到获取到锁为止”。这里有几个要点:
1)自旋锁如果未获取到锁,则会立刻再次尝试
2)自旋锁的尝试是同步行为,是会占用cpu的
因此,如果机器是单cpu的,而运行在次cpu上的线程进行了一次自旋锁获取,那么毫无疑问,此线程将独占此cpu,如果自旋处理流程中没有任何能够 让出 时间片的动作,此cpu利用率将飙升至 100%
代码模型: while (抢锁(lock) == 没抢到) { //做些什么,比如计数 //当计数到某个值以后,直接跳出循环 } 小结:
1.自旋锁会占用CPU,让其处于忙等状态,同时,还会“阻塞中断”,这很有用,某些相当关键的代码,如果加上自旋锁,那么可以 有效的屏蔽中断的干扰,不过这种场景在用户环境不常见,多出现在内核编程中
2.lock和trylock返回0就表示加锁成功,否则失败
互斥量: 互斥量Mutex的逻辑行为是:“尝试获取互斥量,如果被别的 线程 占用,则当前线程进入休眠状态,直到操作系统帮自己解除休眠”。要点如下:
1)获取互斥量失败时,当前线程会被投入睡眠
2)睡眠的唤醒有操作系统完成,即当前线程表现为阻塞状态(需要 区别 阻塞 和 忙等,线程阻塞不占cpu,线程忙等会再用cpu)。
posix关联接口:
PTHREAD_MUTEX_INITIALIZER : 互斥量的初始值,定义互斥量的时候,可以使用这个只作为初始值。 pthread_mutex_init : 初始化互斥量 对入参的pthread_mutex_t变量进行初始化,猜测具体的动作是注册到内核的监视列表中。 pthread_mutex_destroy :销毁互斥量 对入参的pthread_mutex_t变量进行销毁,猜测底层动作是将互斥量从内核监视列表中去注册。 pthread_mutex_lock : 阻塞锁互斥量 锁住互斥量,如果互斥量没有被其他线程锁住,那么当前线程获得锁,继续往下执行。如果被其他线程锁住,那么当前线程投入睡眠,等待操作系统唤醒自己。唤醒的同时,会把锁交给当前线程。 pthread_mutex_trylock : 尝试锁互斥量 尝试锁互斥量,如果尝试成功,则获得互斥量,同时返回 0 ,否则 非0 以表示错误信息 pthread_mutex_timedlock : 超时阻塞锁互斥量 相对于pthread_mutex_lock,此函数不会一直睡眠下去,当入参中的超时时间到达以后,操作系统会唤醒当前线程,如果在超时时间内获得了互斥量,函数返回0,否则非0,另外返回值有一种情况可以表示是超时返回。 pthread_mutex_unlock : 释放互斥量 释放当前线程持有的互斥量。 条件变量: 条件变量的出现是为了满足特殊的使用场景,其实即便使用互斥量也是可以完成这种场景的实现,只不过代码会更复杂,而且会更吃CPU。
title: Node.js 多版本安装及 NPM 镜像配置
date: 2022-03-10 20:23:09
tags:
NPMNode.js前端
categories:开发工具及环境
cover: https://cover.png
feature: false 1. 安装多版本 Node.js 1.1 下载 首先去官网下载需要的 Node.js 版本,点击其他下载可以下载其他版本的 Node.js
1.2 安装 下载完成后先安装低版本的 Node.js,点击 Next
接受,Next
可以按需修改安装路径,Next
Next
Next
最后安装完成。会自动添加环境变量,可以打开环境变量查看,假如没有可以手动添加,这里我已经添加了两个
通过命令行输入 node -v 可以查看 Node.js 版本
安装完后更改 Node.js 的安装目录名字,然后再进行上面的操作安装另一个版本,安装完成后再将名字改回来
1.3 更换版本 通过命令 where node 可以查看本机中所有 Node.js 的版本
更换版本时,只需要在环境变量中将需要的 Node.js 版本移到其他版本前面。
2. 更换 NPM 镜像 Node.js 自带了一个包管理器 NPM,但是默认是去国外的服务器地址下载依赖,速度可能会很慢,可以替换为镜像地址,提高下载速度
打开命令行,输入命令,更换为淘宝镜像
npm config set registry https://registry.npmmirror.com 然后重新打开命令行,可以通过命令查看镜像是否更改
npm config get registry 3.
摘要
心理测试在我国兴起还是近几年的事,由于对心理健康认识不足,观念陈旧,一些人虽然有心理问题或有心理疾病症状,但却想不到或不敢去心理测试。因为他们中有些人是不知道自己的这些问题是应该找心理医生呢还是找生理医生,而另一些人认为看心理医生不光彩,怕人耻笑,不愿去咨询,导致一般性心理问题积累成心理疾病,而痛苦不堪,甚至造成恶性事件、自卑、敏感、多疑带来心理困惑,和情绪紧张的时候,无法进入学习状态的时候。
本论文主要论述了如何使用PHP语言开发一个心理学交流学习网站,本系统将严格按照软件开发流程进行各个阶段的工作,采用B/S架构,面向对象编程思想进行项目开发。在引言中,作者将论述心理学交流学习网站的当前背景以及系统开发的目的,后续章节将严格按照软件开发流程,对系统进行各个阶段分析设计。
心理学交流学习网站的主要使用者分为管理员和用户与专家,实现功能包括管理员:首页、公告内容(轮播图、公告栏)系统用户(管理员、注册用户)内容模块(心理科普、科普分类、心理测试)模块管理(热文资讯、课程分类、精品课程、测试分析),用户;首页、公告栏、心理科普、热文资讯、精品课程、我的管理等功能。由于本网站的功能模块设计比较全面,所以使得整个心理学交流学习网站信息管理的过程得以实现。
本系统的使用可以实现本心理学交流学习网站管理的信息化,可以方便管理员进行更加方便快捷的管理,可以提高心理学交流学习网站的管理效率。
关键词:PHP语言;MYSQL数据库;心理学交流学习网站
Abstract
The rise of psychological testing in China is still in recent years. Due to the lack of understanding of mental health and outdated concepts, although some people have psychological problems or symptoms of psychological diseases, they can't think of or dare not go to psychological testing. Because some of them don't know whether they should find a psychologist or a physiologist for these problems, while others think it's disgraceful to see a psychologist, afraid of ridicule and unwilling to consult, which leads to the accumulation of general psychological problems into psychological diseases and unbearable pain, and even malignant events, low self-esteem, sensitivity and paranoia, resulting in psychological confusion, And emotional tension, unable to enter the learning state.
echart修改一些配置项,经常会用到经常忘记,这里记录一下!
1.修改横纵坐标的颜色 看代码:
const option = { tooltip: { trigger: 'axis', axisPointer: { type: 'shadow', }, }, grid: { // show:true, left: "5%", top: "10%", right: "2%", bottom: "8%", borderWidth: 1, }, legend: { data: ['项目总数', '在建项目数', '开工项目数'], textStyle: { color: 'rgb(255,255,255,0.9)', }, }, xAxis: [ { type: 'category', axisTick: { show: false }, data: [ '成都新经济', '成都科学城', '龙潭工业机器', '成都新谷', '白鹭湾新经济', '龙泉汽车城', '成都医学城', '天府牧山数字', ], axisLine: { lineStyle: { color: '#fff', }, }, }, ], yAxis: [ { type: 'value', axisLine: { lineStyle: { color: '#fff', }, }, }, ], }; 2.
Redis五大基本数据类型 1.Redis通用命令 常用命令
#Redis的键key操作 keys * 表示查看当前库所有key 【注意是:可以使用通配符】 exists <key> 表示判断某个key是否存在,存在返回1,否则返回0 type <key> 表示判断key类型 del <key> 表示删除指定key数据,表示就是直接删除除掉,如果删除成功返回1,否则返回0 unlink <key> 根据value选择非阻塞删除,仅将key从keyspace元数据中 删除,真正删除会在后续异步操作,表示不是立即删除 expire <key> 秒数 :表示给指定key设置过期时间 ttl <key> 查看还多少秒过期,-1表示永过期,-2表示已经过期 2.String类型 简介:String是Redis最基本的类型,是一个key对应一个value类型,String类型是二进制安全的,说明Redis中的String类型可以包含任何数据,比如jpg图片或者序列化的对象,一个Redis中字符串value是最多可以是512M
常用命令
#添加数据指令 set <key><value> 添加键值对【一次只能添加一个值】 NX表示数据库中key不存在时,可以将k-v添加到数据库中 XX表示数据库中key存在时,可以将k-v添加数据库中,与NX参数互斥 EX表示key超时秒数 PX表示key超时毫秒数,与EX互斥 append <key><value> 表示将给定的value追加到原值的未尾 setnx <key><value> 表示只有在key不存在时,设置key的值 mset <key1><value1><key2><value2>... 表示同时设置一个或多个k-v键值对 msetnx <key1><value1><key2><value2>... 表示同时设置一个或多个k-v键值,注意是当设置的key中必须都不能存在,如果存在一个则全部失败 setex <key> <过期时间> <value> 表示设置键值的同时,设置过期时间,单位为秒 #获取值 get <key> 表示查询对应键值 mget <key1><key2>... 表示查询多个值 strlen <key> 表示获取得值的长度 getrange <key> <起始位置><结束位置> 获取值的范围,类似于JAVA中的substring包含前后 #替换值 setrange <key><起始位置><value> 用value覆盖<key>所储存的字符串值,从<起始位置>开始(索引从0开始) getset <key><value> 以新换旧值,设置新值同时获取旧值 #对数字值操作,就是只能对纯数字操作 incr <key> 将key中储存的数字值增1,只能对数字值操作,如果为空,新增值为1 decr <key> 将key中存储的数字值减1,只能对数字值操作,如果为空,新增值-1 incrby|decrby <key> <步长> 将key中存储的数字值增减,自定义步长 3.
您好,我是湘王,这是我的CSDN博客,欢迎您来,欢迎您再来~
除了反向代理,Nginx另一个主要的功能就是「负载均衡」。
所谓负载均衡,就是将请求分摊到多个服务器上执行,从而减轻单台服务器的访问压力。负载均衡一般都需要同时配置反向代理,通过反向代理跳转到指定的服务器上。
Nginx目前支持自带三种负载均衡策略,还有两种常用的第三方策略。
先准备好环境:
1、先安装三台Linux虚拟机,每台虚拟机上安装好JDK环境(不想装虚拟机,docker也可以)
2、开发一个最简单的SpringBoot应用
3、分别部署到其中两台服务器上,一台叫server01,一台叫server02
4、另一台服务器安装Nginx,做负载均衡,叫做server03
在application.properties文件中增加:server.port=8080
修改启动类,排除数据源的自动加载:
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
增加Controller类:
打包应用,并上传到server02,启动应用
java -jar nginx-0.0.1-SNAPSHOT.jar
修改Controller类
打包应用,并上传到server03,启动应用
java -jar nginx-0.0.1-SNAPSHOT.jar
访问server01和server02(或者docker)的地址:
http://172.16.185.130:8080/test?username=test1
http://172.16.185.131:8080/test?username=test1
使用Nginx的默认方式,也就是轮询:每个请求按顺序轮流地分配到不同的后端服务器。如果某些后端服务器宕机或离线,也能自动剔除。
修改配置:
重新加载Nginx:
cd /usr/local/nginx/sbin/
./nginx -s reload
访问server03的地址:http://172.16.185.136/test?username=test1
结果是:
第n次访问会返回「server02」
第n+1次访问会返回「server03」
或者相反。
说明配置已生效。
现在给轮询增加一下权重,避免平均主义:每个请求指定轮询几率,weight和访问比率成正比。这可以用于后端服务器性能不均的情况,如果某些后端服务器宕机或离线,也能自动剔除。
修改配置,增加weight关键字:
重新加载Nginx:
cd /usr/local/nginx/sbin/
./nginx -s reload
再访问server03:http://172.16.185.136/test?username=test1
连续访问多次的结果:
多数访问会返回「server02」
少数访问会返回「server03」
大概就是三七开,说明配置已生效。
轮询和权重的方式只能满足无状态的或者幂等的业务应用。但很多时候业务需要满足一个客户只能访问一个服务器的条件因此,这种情况就需要采用iphash方式来分配后端服务器。
修改配置,增加ip_hash关键字:
重新加载Nginx:
cd /usr/local/nginx/sbin/
./nginx -s reload
再次访问server03:http://172.16.185.136/test?username=test1
连续访问多次的结果:如果每次访问都只返回了「server01」或者「server02」,则说明配置已生效。
除了轮询、权重和iphash,另外还可以通过第三方插件来设置负载均衡的方式:
如果需要按后端服务器的响应时间来分配请求的话,可以使用第三方插件fair。
1、下载地址:https://github.com/gnosek/nginx-upstream-fair
(或者https://www.nginx.com/resources/wiki/modules/index.html)
2、下载后解压到/home/work/upstream-fair/
问: 我正在尝试为我们使用的 Docker 容器构建备份和恢复解决方案。
我有我创建的 Docker 基础映像 ubuntu:base,并且不希望每次都使用 Docker 文件重新构建它以向其中添加文件。
我想创建一个从主机运行的脚本,并使用 ubuntu:base Docker 映像创建一个新容器,然后将文件复制到该容器中。
如何将文件从主机复制到容器?
答1: HuntsBot周刊–不定时分享成功产品案例,学习他们如何成功建立自己的副业–huntsbot.com
cp 命令可用于复制文件。
可以将一个特定文件复制到容器中,例如:
docker cp foo.txt container_id:/foo.txt 可以从容器中复制一个特定文件,例如:
docker cp container_id:/foo.txt foo.txt 为了强调,container_id 是 容器 ID,不是 图像 ID。 (使用 docker ps 查看包含 container_id 的列表。)
可以使用以下方法将文件夹 src 包含的多个文件复制到 target 文件夹中:
docker cp src/. container_id:/target docker cp container_id:/src/. target 参考:Docker CLI docs for cp
在 1.8 之前的 Docker 版本中,只能将文件从容器复制到主机。不是从主机到容器。
huntsbot.com全球7大洲远程工作机会,探索不一样的工作方式
另请注意,这可以在主机 vm 或主操作系统上,并且可以在主机到容器或 vm 到主机(或主操作系统)上工作
通过Python爬虫获取【小说网站】数据,保姆级教学 目录
通过Python爬虫获取【小说网站】数据,保姆级教学
前言
示例环境
爬取目标
爬取代码
核心技术点:
爬取结果
前言 所有的前置环境以及需要学习的基础我都放置在【Python基础(适合初学-完整教程-学习时间一周左右-节约您的时间)】中,学完基础咱们再配置一下Python爬虫的基础环境【看完这个,还不会【Python爬虫环境】,请你吃瓜】,搞定了基础和环境,我们就可以相对的随心所欲的获取想要的数据了,所有的代码都是我一点点写的,都细心的测试过,如果某个博客爬取的内容失效,私聊我即可,留言太多了,很难看得到,本系列的文章意在于帮助大家节约工作时间,希望能给大家带来一定的价值。
示例环境 系统环境:win11
开发工具:PyCharm Community Edition 2022.3.1
Python版本:Python 3.9.6
资源地址:链接:https://pan.baidu.com/s/1UZA8AAbygpP7Dv0dYFTFFA 提取码:7m3e
MySQL:5.7,url=【rm-bp1zq3879r28p726lco.mysql.rds.aliyuncs.com】,user=【qwe8403000】,pwd=【Qwe8403000】,库比较多,自己建好自己的,别跟别人冲突。
爬取目标 小说,小说网-纵横中文网|最热门的免费小说网
https://book.zongheng.com/
输入对应的网址即可下载:
爬取代码 核心技术点: 1、双重集合单循环遍历
for item1, item2 in zip(href, text): a_href_list = ["", ""] a_href_list[0] = item1 a_href_list[1] = item2 a_href_arr.append(a_href_list) 2、parsel的css选择器语法
注意点:这里的注意点依然是时间的随机上,如果你有IP代理的话就无所谓了。
import requests import parsel import uuid import time import random import os baseUrl = "http://www.zongheng.com/" bookId = "https://book.zongheng.com/book/1228049.html" bookIdDir = bookId.replace("book/", "
代码来源: https://github.com/ymcidence/TBH
环境配置:
极客云平台云主机
正常运行
论文解读 to be continued…
1. 前言
2. git log
3. git reflog
4. 翻页、查看下一行、退出查看
1. 前言
git log 命令主要用于查看提交记录
日常开发中,我们会经常使用 git log 查看提交记录,配合 git status 确认当前代码是不是最新的
git log 有很多的参数选项,我们可以根据自己的需求使用不同的参数,使其输出我们想要的效果
2. git log
基本用法
git log only one line,该参数用于简化 git log 的默认输出。只显示 commit id 和备注信息
git log --pretty=oneline 更为简洁的提交历史列表,只显示 commit id 的前 7 位和备注信息
git log --oneline 查看某个人的提交记录 (等号和空格都行)
git log --author lianggit log --author=liang 查看最近 n 次的提交记录
# 查看最近1次提交记录git log -1# 查看最近2次提交记录git log -2 查看文件的变动信息
文章目录 Pandoc 简介Pandoc 安装pandoc-latex-template字体安装Powershell 脚本Ubuntu PandocMarkdown 合并 Pandoc 简介 Pandoc, 免费的文档转换器, 支持常见的各种文件格式的相互转换, 如Markdown, HTML, EPUB, LaTeX, docx, RTF, PDF 等.
本篇以Windows下的多Markdown转单PDF为例, 最后也会介绍Ubuntu下的使用方法.
Pandoc 安装 Windows下的安装:
Pandoc: 直接到 Installing pandoc 下载安装.MiKTeX: 直接到 Getting MiKTeX 下载安装, Pandoc默认使用 LaTeX 创建PDF, Windows上安装MiKTeX就包含了LaTeX. 安装完后, 打开 MiKTeX Console 检查MiKTeX及宏包的更新(第一次运行Pandoc转出PDF时, 可能会提示安装缺失的宏包) 安装完后, 检查和添加Pandoc和MiKTeX的环境变量
环境变量添加完, 首次需要在Powershell中刷新下环境, 让Powershell能找到MiKTeX一堆宏包exe文件的路径
$env:Path = [System.Environment]::GetEnvironmentVariable("Path","Machine") + ";" + [System.Environment]::GetEnvironmentVariable("Path","User") pandoc-latex-template 如果用默认参数, pandoc xxx.md --pdf-engine=xelatex -o yyy.pdf 生成PDF, 会发现各种小问题, 如代码块未和正文明显区分, 代码块中的单行过长会超出文档边界等.
类似PPT套模版, Pandoc生成好看的PDF也需要一套好用的模版, 如这个star数超多的 pandoc-latex-template, 即大名鼎鼎的eisvogel.
修改磁盘numa_node的方法 最近在搞集成的工作,碰到需要修改磁盘numa_node值的问题,如下是一些基础方法,供初学者使用
有两种修改磁盘numa_node的方法
临时修改磁盘numa_node nvme?:?是对应的磁盘号,例如:nvme0、nvme1、nvme2
#更改磁盘numa_node(用这种方式重启会还原) #修改numa_node 的值 vi /sys/class/nvme/nvme?/device/numa_node 如下就是对应的nvme0、nvme1、nvme2、nvme3
# nvme0的numa_node 的值 cat /sys/class/nvme/nvme0/device/numa_node 永久修改磁盘numa_node 以修改nvme0 的numa_node为例
# 修改nvme0的numa_node 的值,将0刷入rc.local文件 # 写入rc.local,重启机器后,会自动修改numa_node echo 'echo "0" > /sys/class/nvme/nvme0/device/numa_node ' |tee -a /etc/rc.d/rc.local 如果无rc.local文件的操作权限,则需要先赋权,或更换为root账号权限
# 先更改文件权限 chmod 777 /etc/rc.d/rc.local # 或者root权限 sudo -i 执行成功后,查看rc.local内容
修改网卡numa_node的方法 最近在搞集成的工作,碰到需要修改网卡numa_node值的问题,如下是一些基础方法,供初学者使用
有两种修改网卡numa_node的方法
1. 临时修改网卡numa_node
eth?:?是对应的网卡号,例如:eth0、eth1、eth2
#更改网卡numa_node(用这种方式重启会还原) #修改numa_node 的值 vi /sys/class/net/eth?/device/numa_node 这里只是一个例子,ens3是服务器的一个网口,这个需要根据实际的来
# 网口ens3的numa_node 的值 cat /sys/class/net/ens3/device/numa_node 永久修改网卡numa_node
以修改eth0 的numa_node为例 # 修改eth0的numa_node 的值,将1刷入rc.local文件 # 写入rc.local,重启机器后,会自动修改numa_node echo 'echo "1" > /sys/class/net/eth0/device/numa_node ' |tee -a /etc/rc.d/rc.local 如果无rc.local文件的操作权限,则需要先赋权,或更换为root账号权限
# 先更改文件权限 chmod 777 /etc/rc.d/rc.local # 或者root权限 sudo -i 执行成功后,查看rc.local内容
cat /etc/rc.d/rc.local # 展示结果如下 touch /var/lock/subsys/local echo "1" > /sys/class/net/eth0/device/numa_node
这个错误消息表明在安装 CUDA 时,系统无法验证 GCC 的版本。要解决这个问题,需要安装适当版本的 GCC。可以查看 /var/log/cuda-installer.log 文件以了解详细信息。
将二分法查找按照面向对象的思想重写 要求:输入一个整数列表,进行二分法查找
class Half_Find(): def __init__(self, list1, num1): self.list1 = list1 self.num1 = num1 def h_find(self): if len(self.list1) == 0 or len(self.num1) == 0: return '数据不能为空' self.num1 = int(self.num1) self.list1 = list(self.list1) # 转为字符串列表 self.list1 = [int(self.list1[i]) for i in range(len(self.list1))] # 遍历字符串列表的每个元素,强制转为int self.list1.sort() # 排序 i = 0 j = len(self.list1) - 1 while i <= j: mid = (i + j) // 2 # 计算中间元素索引 if self.list1[mid] == self.
LoadingDialogUtils:
package yuduobaopromotionaledition.com.dialog; import android.app.Activity; import android.view.LayoutInflater; import android.view.View; import android.view.WindowManager; import java.lang.ref.WeakReference; import androidx.appcompat.app.AlertDialog; import yuduobaopromotionaledition.com.R; public class LoadingDialogUtils { private static AlertDialog loadingDialog; private static WeakReference<Activity> reference; private static void init(Activity act) { init(act, -1); } private static void init(Activity activity, int res) { if (loadingDialog == null || reference == null || reference.get() == null || reference.get().isFinishing()) { reference = new WeakReference<>(activity); loadingDialog = new AlertDialog.Builder(reference.get()).create(); if (res > 0) { View view = LayoutInflater.
中兴服务器迈络思NS312网卡down掉网口物理指示灯不熄灭解决方法–NS312型号ConnectX-4 Lx 中兴服务器做网卡倒卡测试时,出现如下问题:
中兴服务器迈络思网卡,卡片NS312,型号ConnectX-4 Lx,万兆网卡在执行ifdown或ip link set up ens2等down掉网口的命令时,并不会物理down物理网口,down掉后,物理网口指示灯依然是亮的。这样的话在网卡绑定bond时,用的是model2的话,就无法通过倒卡测试。会给后期运维带来麻烦。
倒卡测试:
网卡绑定bond,如:bond1绑定的是eth0 eth1 eth2 eth3 四个网口,当排列组合down掉其中三个时,bond1要能够正常工作。
注意:
model4模式的bond不会有该问题,可以通过修改交换机的 最短时间间隔设置(交换机lacp绑定端口,启用 lacp timeout short 设置间隔时间),中兴服务器默认设置的是30秒。
为了解决model2模式的bond,无法通过倒卡测试问题,则通过物理down掉网口的方式实现。
服务器物理网口指示灯亮与熄灭是网卡固件决定,用ifconfig ethx down(协议层down)时,如果还需要关闭网口ethx的发光(物理down),需要做如下设置
步骤如下:
下载麦洛斯网卡MFT工具
麦洛斯网卡MFT工具下载路径
https://network.nvidia.com/products/adapter-software/firmware-tools/
MFT工具上传及安装
a. 将工具包mft-4.22.1-11-x86_64-rpm.tgz,上传到服务器Linux操作系统指定的目录下。
例如上传到 /home/mft 目录下。
-- 创建 mft目录 mkdir -p /home/mft b. 使用root用户解压MFT工具压缩包。
# 进入上传rpm包的目录 cd /home/mft # 解压MFT工具包 tar -zxvf mft-4.22.1-11-x86_64-rpm.tgz c. 安装MFT工具。
# 进入工具目录 cd mft-4.22.1-11-x86_64-rpm/ # 执行安装脚本。 (注:如果是非root用户,执行安装前需要先授权,命令:chmod +x *) ./install.sh --oem 如果在安装的时候,提示安装不了,则需要先在服务器安装提示缺失的应用。如下在安装 mft-4.22.1-11-x86_64-rpm时要先安装rpm-build。
# 安装 rpm-build yum -y install rpm-build 如果你的机器没有配置yum源,那么需要自己去配置一个,如果实在是配不了,也没有本地yum源包,那么就去下载一个安装吧。
2.YOLOv5简介
2.1 YOLOv5算法简介
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其 速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
2.2 YOLOv5网络架构
上图展示了YOLOv5目标检测算法的整体框图。对于一个目标检测算法而言,我们通常可以将其划 分为4个通用的模块,具体包括:输入端、基准网络、 Neck网络与Head输出端,对应于上图中的4个红 色模块。 YOLOv5算法具有4个版本,具体包括: YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四种,本 文重点讲解YOLOv5s,其它的版本都在该版本的基础上对网络进行加深与加宽。
输入端: 输入端表示输入的图片。该网络的输入图像大小为608*608,该阶段通常包含一个图像预处理阶段,即将输入图像缩放到网络的输入大小,并进行归一化等操作。
在网络训练阶段, YOLOv5使用Mosaic数据增强操作提升模型的训练速度和网络的精度;并提出了一种自适应锚框计算与自适应图片缩放方法。
基准网络: 基准网络通常是一些性能优异的分类器种的网络,该模块用来提取一些通用的特征表示。 Y
OLOv5中不仅使用了CSPDarknet53结构,而且使用了Focus结构作为基准网络。
Neck网络: Neck网络通常位于基准网络和头网络的中间位置,利用它可以进一步提升特征的多样性及鲁棒性。虽然YOLOv5同样用到了SPP模块、 FPN+PAN模块,但是实现的细节有些不同。 Head输出层: Head用来完成目标检测结果的输出。针对不同的检测算法,输出端的分支个数不尽相同,通常包含一个分类分支和一个回归分支。 YOLOv4利用GIOU_Loss来代替Smooth L1 Loss函数,从而进一步提升算法的检测精度。
2.3 YOLOv5算法详解
2.3.1 YOLOv5基础组件
CBL :CBL模块由Conv+BN+Leaky_relu激活函数组成,如上图中的模块1所示。
Res unit:借鉴ResNet网络中的残差结构,用来构建深层网络, CBM是残差模块中的子模块,如 上图中的模块2所示。 CSP1_X :借鉴CSPNet网络结构,该模块由CBL模块、 Res unint模块以及卷积层、 Concate组成而 成,如上图中的模块3所示。 CSP2_X :借鉴CSPNet网络结构,该模块由卷积层和X个Res unint模块Concate组成而成,如上图 中的模块4所示。
Focus :如上图中的模块5所示, Focus结构首先将多个slice结果Concat起来,然后将其送入CBL 模块中。
SPP :采用1×1、5×5、9×9和13×13的最大池化方式,进行多尺度特征融合,如上图中的模块6所 示。
2.3.2 输入端细节详解
Mosaic数据增强: YOLOv5中在训练模型阶段仍然使用了Mosaic数据增强方法,该算法是在
CutMix数据增强方法的基础上改进而来的。 CutMix仅仅利用了两张图片进行拼接,而Mosaic数据 增强方法则采用了4张图片,并且按照随机缩放、随机裁剪和随机排布的方式进行拼接而成,具体 的效果如下图所示。这种增强方法可以将几张图片组合成一张,这样不仅可以丰富数据集的同时极 大的提升网络的训练速度,而且可以降低模型的内存需求。
自适应锚框计算: 在YOLO系列算法中,针对不同的数据集,都需要设定特定长宽的锚点框。在网络训练阶段,模型在初始锚点框的基础上输出对应的预测框,计算其与GT框之间的差距,并执行 反向更新操作,从而更新整个网络的参数,因此设定初始锚点框也是比较关键的一环。在YOLOv3 和YOLOv4检测算法中,训练不同的数据集时,都是通过单独的程序运行来获得初始锚点框。 YOLOv5中将此功能嵌入到代码中,每次训练时,根据数据集的名称自适应的计算出最佳的锚点 框,用户可以根据自己的需求将功能关闭或者打开,具体的指令为
一.什么是boost库 boost 库是一个优秀的,可移植的,开源的 C++ 库,它是由 C++ 标准委员会发起的,其中一些内容已经成为了下一代 C++ 标准库的内容,在 C++ 社区中影响甚大,是一个不折不扣的准标准库,它的功能十分强大,弥补了 C++ 很多功能函数处理上的不足。
二.特点 可移植性:Windows,Linux,Unix 等
开源免费:使用 Boost License 来授权使用,商业和非商业都是可以使用的
高效:具有工业强度,设计结构良好,广泛使用
三.分类 boost 库功能强大,按照功能模块分类,大致可以分为如下:
字符串和文本处理库,容器库,迭代器库,算法库,函数对象和高阶编程库,泛型编程,模板元编程,预处理元编程,并发编程,数字和数学,排错和测试,数据结构,图像处理,输入输出,内存管理,跨语言混合编程,解析,编程接口等。
四.如何使用boost库 要使用 C++ boost 库,先要下载 boost 库,下载地址是:https://www.boost.org/
选择 Downloads 下的 Current Release 就可以下载了。
下载完成后查看目录,大致如上结构所示。
boost 文件夹下是 boost 的头文件,都是 .hpp 文件,doc 是相关文档,libs 是库文件,里面有一些例子说明,tools 是 boost 提供的工具等。
如果要使用 boost 库,注意将 boost 库的路径添加到附加包含目录,如果不知道如何添加,可以查看:Visual Studio的高效使用_椛茶的博客-CSDN博客
大多数的 boost 库仅需要包含头文件 hpp 即可,不需要再链接其他的 lib 文件,但是有些 boost 下的库是需要包含 lib 文件的。
五.使用案例
目录 作用常用属性常用布局管理器基本布局管理器水平布局管理器垂直布局管理器 栅格布局管理器窗体布局管理器 部件大小QSizePolicy布局管理器属性layoutFieldGrowthPolicylayoutRowWrapPolicylayoutLabelAlignmentlayoutSizeConstraint 拆分器伙伴关系Tab键顺序 作用 定位子部件感知窗口大小(默认和最小)窗口大小变化时自动处理子部件 常用属性 属性设置函数说明layoutSpacingsetSpacing()子部件距离layoutStretchsetStretch()伸缩因子layoutLeftMarginsetContentsMargins()距左边界距离layoutTopMarginsetContentsMargins()距上边界距离layoutRightMarginsetContentsMargins()距右边界距离layoutButtomMarginsetContentsMargins()距下边界距离 setContentsMargins(左, 上, 右, 下)
常用布局管理器 基本布局管理器 基本布局管理器分为水平布局和垂直布局
水平布局管理器 头文件:<QHBoxLayout>
效果:让子部件从左到右排列
使用方法:
在设计界面点击上方的Lay Out Horizontally或摁快捷键Ctrl + H
使用代码
QHBoxLayout *layout = new QHBoxLayout(); layout->addWidget(ui->fontCombox) //添加组件 layout->setSpacing(50) //部件间隔 layout->setContentsMargins(0, 0, 50, 100) // 离左、上、右、下的距离 setLayout(layout) //设置布局 注:设置布局代码放在setupUi()后
垂直布局管理器 头文件:<QVBoxLayout>
效果:让子部件从上到下排列
使用方法:与水平布局类似
栅格布局管理器 头文件:<QGridLayout>
效果:计算布局空间,将布局合理分为一块块类似经纬切分的小格,因此又称网格布局
使用方法:
在设计界面点击上方的Lay Out Horizontally或摁快捷键Ctrl + G使用代码 QGridLayout *layout = new QGridLayout; layout->addWidget(ui->fontComboBox, 0, 1, 2, 3); // 参数分别为子部件,第1行2列开始,占据2行3列 // 只有一个部件默认居中 setLayout(layout); 窗体布局管理器 头文件:<QFormLayout>
也可使用:org.apache.commons.lang3.math.NumberUtils.java工具类
/** * @version: v1.0 * @date:2022/11/10 */ import java.math.BigDecimal; import java.math.BigInteger; import java.nio.ByteBuffer; import java.nio.charset.Charset; import java.text.NumberFormat; import java.util.Set; import org.apache.commons.lang3.ArrayUtils; import org.apache.commons.lang3.StringUtils; /** * 类型转换器 * * @author wangwenyong */ public class ConvertUtils { /** * 转换为字符串<br> * 如果给定的值为null,或者转换失败,返回默认值<br> * 转换失败不会报错 * * @param value 被转换的值 * @param defaultValue 转换错误时的默认值 * @return 结果 */ public static String toStr(Object value, String defaultValue) { try { if (null == value) { return defaultValue; } if (value instanceof String) { return (String) value; } return value.
【零基础 快速学Java】韩顺平 零基础30天学会Java_哔哩哔哩_bilibili
一、因由追溯
我今年大二了,因为高考分数不够高,被调剂到冷门专业——海洋科学专业,我是这个专业的第十届学生。我最想学的专业是医学专业,但它的学习周期太长,这意味着我很久都得不到人身自由。然后我志愿就填了计算机,因为我想要掌握最核心的东西。
但是大人们都反对,因为他们觉得这个干计算机这行,30岁就意味着失业了。家里人没有干这个的,所以他们对这行了解也不深。父母想要让我去亲戚那里,找一些可靠的朋友帮忙出一下主意,该怎么填志愿。他们七嘴八舌地出主意,但没有人在意我到底喜欢什么。
我是一个很顽固的人,我不愿意往后半生都与我不喜欢的专业一起渡过。所以,我按自己内心的想法来选择了计算机。但我拿到这个学校的录取通知书时,家里人除了嘲讽,没有半点祝福,“这个专业我都没听说过”,“浪费了这么好的分数了”……我仍然记得当时拿着这录取通知书尴尬得脸红耳热,一身冷汗,说不出话。
我孤身一人跨越半个中国,从广东来到南京上学,我从未独自一人出过省。整整3个月,我和家里都没有半点联系。这还不是最大的问题,当我勉强说服自己接受这个专业,并且尝试去说服我家人接受这个专业时,我突然发现,我骗得了其他人,但我骗不了自己。一旦听到别人说我这个专业不好,我就会陷入绝望。我发现我走了这么远,背井离乡,学着不喜欢的专业,处着矛盾重重的舍友和同学,对着绝望的未来,这有什么意义。
后来我上网匿名问网友,有个网友私聊我,大体意思是,让我找到自己喜欢的专业,自学,然后尽早去实习,我给他们当“免费劳动力”,但我在他们那学习、积累经验。
然后,我就义无反顾地再次选择了计算机,这个专业自学的人多,而且也不那么看重学校、专业出身。这个时候已经接近大一的尾声了。
二、学习总结
2022年9月25号考完C语言的计算机二级后,我才正式地开始学习java,并且打算当成以后在这一行工作。我原本是一边刷计算机二级的java题,哪里不会再去学。但是我发现这样学习陌生的知识点太多,题目根本做不下去,以题目为出发点去整理出来的知识点也太零散。
然后我转变了策略,翻看到韩老师的课时,900多集的视频让我有些犹豫,这战线有点太长了。但后来经过比较,我发现韩老师的课程更合我的口味,所以就跟着韩顺平老师从第191集学到了第910集,几个项目的部分有些残缺,我想后面巩固了一下这阶段的知识后,再完善一下项目的学习。
在这个阶段的学习,最大的问题在于,老师讲得太细致,我有时会习惯性地懒得思考,所以我还是得通过习题来再巩固、吸收一下这阶段的学习内容。
二、下阶段的计划
刚开始学习时,我连网上的学习路线都看不懂,什么是前端,什么是后端,什么是框架……现在我依旧是不怎么看得懂路线,但起码下一步的学习还是多多少少在弹幕里看到过、听韩老师讲过。
下一阶段是学数据结构,依旧是韩老师B站上免费的课,期间也得上力扣刷题,还有一些计算机的操作系统什么的,也得拿书来完整地过一遍。
自学这条路最容易发生的事莫过于怀疑自己,怀疑自己是否走错了路,怀疑自己是否学得太慢了,怀疑自己是否真的能做到,怀疑自己付出这么多是否真的值得,怀疑自己是否真的蠢……
但好不容易走到这了,再回头就不礼貌了。
在微信小程序中,可以使用组件 "checkbox" 来实现照片右上角的勾选框。可以在 wxml 文件中使用 <checkbox> 标签来渲染勾选框,并在相应的 wxss 文件中对勾选框的样式进行调整。在 JavaScript 中,可以使用 data 和 methods 来控制勾选框的状态和点击事件。详细的实现方法还需要根据具体的需求和页面布局来进行调整
以下内容默认读者知道什么是神经网络,反向传播
在神经网络训练模型中,一些简单的模型往往隐藏层(hidden layer)不会太多,并且可以训练出一些效果很好的模型。但是如果你在模型中加入了很多隐藏层,就可能会造成梯度消失和梯度爆炸的问题
梯度消失 原因:激活函数的选择
激活函数有很多种,比如 ReLu,sigmoid 等。如果在一个很复杂,层数很多的神经网络种,使用了 sigmoid 激活函数,是造成梯度消失的主要原因。
下图是 sigmoid 函数
首先,可以看出,当输入值越忘正负无穷靠近时,sigmoid 值会越接近0,此时梯度也会接近0。其次,sigmoid 函数的梯度最大时 0.25,当神经网络层数很多的时候,使用反向传播计算梯度的时候,由于需要计算权重的偏导数,会连续乘上很多个 0.25,导致梯度值越来越小,最终接近 0,从而产生梯度消失的问题,而这些梯度接近 0 的权值,则基本不会在更新。 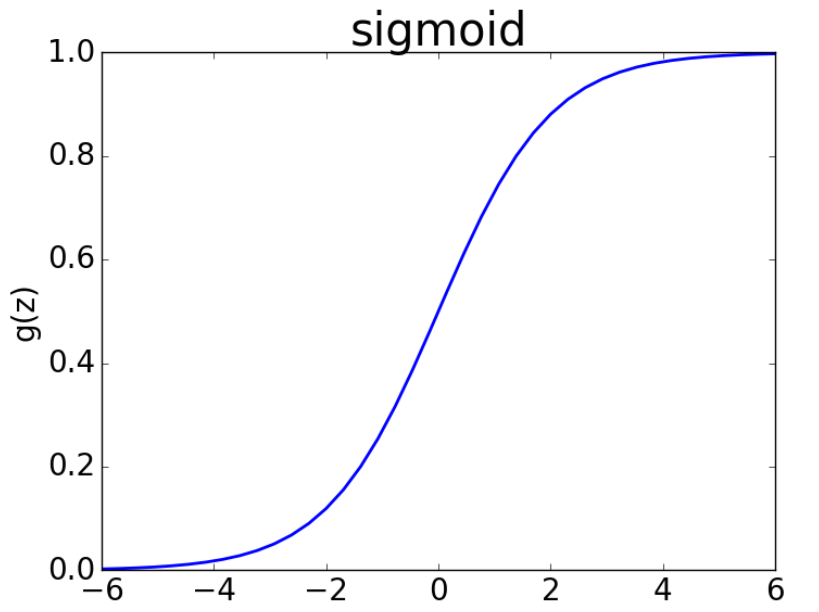
解决方法:使用其他激活函数,如 ReLu
梯度爆炸 原因:权值初始值太大
同样,在网络层比较多的模型下,如果权值初始化值太大,会导致前面的网络层比后面的网络层梯度变化更快,出现梯度爆炸的问题。所以一般情况下,权值的初始化都使用高斯分布随机产生
解决方案 激活函数残差结构高斯分布产生初始权值LSTM
通过 __attribute( (section(x)) ) 来对函数进行快速测试 先从简单代码开始,以下代码通过宏 EXPORT 来帮助我们快速定义一个 myfun_t 变量, 所以在EXPORT(hello);就定义了一个 _hello 变量, 于是我们可以在 main 中进行访问
#include <stdio.h> typedef struct { void (*fun)(void); const char *desc; } myfun_t; #define EXPORT(x) \ static myfun_t _##x = { \ .fun = x \ } void hello(void) { printf("Hello\n"); } EXPORT(hello); int main(int argc, char const *argv[]) { _hello.fun(); return 0; } __attribute 宏用来设置编译属性, __attribute( (section(x)) ) 可以指定编译器将变量存放到指定的内存区域, 之后我们就可以使用
extern type_t __start_<section_name> extern type_t __stop_<section_name> 来进行访问, __start_<section_name> 代表段的起始, 是一个内置标签, 就像 int a = 12; 中的 a 一样, 它的数据类型取决于我们如何看待它, 和很多变量标签一样, 通过 & 可以访问变量所在的地址, 所以访问段的的起始地址为 &__start_mysection
需要源码和资源文件请点赞关注收藏后评论区留言私信~~~
下面我们将在Unity3D中实现愤怒的小鸟的简单版,游戏中最复杂的部分是物理系统,但是借助于Unity3D编辑器,我们就不用担心太多了
一、效果展示 先展示程序运行效果如下 运行程序可以将小鸟弹射出去 并且可以显示运动轨迹 读者可以自行优化
二、程序目录结构 Hierarchy视图结构如下 Assets文件夹目录结构如下图所示
Scripts里面存放的C#脚本文件 结构如下图
Prefabs文件夹中存放的预制体 结构如下图
三、实现步骤 因为愤怒的小鸟是一个2D游戏,所以需要在新建项目时选择2D模板 然后将资源包导入项目中,里面包含图片等资源 如下图所示
摄像机设置 在Project视图中找到Scenes文件夹 然后找到level01.unity文件夹 双击打开 设置里面的背景颜色
地面设置 在Project视图中 找到Sprites文件夹内的ground.png文件 在Inspector视图中 导入设置 将Pixels Per Unit设置为16 然后单击apply按钮
tips:之后所以的图标都设置为16 这意味着16*16的像素时游戏世界中的一个单位,之所以选择16,是因为鸟的大小是16*16
现在地面只是图像 不是物理世界的一部分,事物不会与其相撞,也不会站在它的上面,所以我们需要添加一个碰撞器,让其具有物理特性 这样物体就可以站在地面上。在Inspector视图中 选择Add Component->Physics 2D->Box Collider 2D组件添加即可
边界设置 创建空对象 命名为borders 同样为他添加碰撞器 操作步骤如下面所述 并且勾选Is Trigger属性 并且为右边和上面添加边界 也要添加两个碰撞器
现在需要销毁任何进入边界的对象的功能 单击borders对象 在Inspector视图中 选择Add Component New Script命令,将脚本命名为Borders
云彩设置 把cloud.png拖入Scenes视图中 重复上一步 把云彩摆到你喜欢的位置即可
击打物设置 下面我们添加一些小鸟的击打物 比如木头 石头 冰之类的 拖到Scenes视图中 都要将Pixels Per Unit设置为16 同样要添加刚体属性 选择Add Component->Physics 2D-> Rigidbody 2D命令即可
目录
一、分支语句
1. 判断一个数是否为奇数
2. 输出1-100之间的奇数
法1:遍历1-100所有的数字,判断是否为奇数,再输出
法2:奇数从1开始,等差为2,所以循环+2
二、循环语句
1. 计算 n的阶乘。
2. 计算 1!+2!+3!+……+10!
法1:算出每个数阶乘,然后相加
法2:优化,n!=(n-1)!*n
编辑
3. 在一个有序数组中查找具体的某个数字n。(讲解二分查找)
4. 编写代码,演示多个字符从两端移动,向中间汇聚。
5. 编写代码实现,模拟用户登录情景,并且只能登录三次。(只允许输入三次密码,如果密码正确则 提示登录成,如果三次均输入错误,则退出程序。
三、综合题(猜数字游戏)
一、分支语句 1. 判断一个数是否为奇数 if (n % 2 == 1)
{
printf("奇数\n");
} 2. 输出1-100之间的奇数 法1:遍历1-100所有的数字,判断是否为奇数,再输出 int main() { int i = 0; while (i <= 100) { if (i % 2 == 1) { printf("%d ", i); } i++; } return 0; } 法2:奇数从1开始,等差为2,所以循环+2 这个循环只需要循环50次,而上面的就要100次
目录
前言
1、HTTP 介绍
2、URL介绍
1)了解 URL 和 URI
2)URL 格式 3)URL encode
3、HTTP 协议格式
1)请求报文格式
2)响应报文格式
3)协议格式总结
4、HTTP 请求(Request)
1)请求方法
2)请求的网址(Request URL)
3)请求头(Request Headers)
4)请求体(Request Body)
5、HTTP响应(Response)
1)响应状态码(Resqonse Status Code)
2)响应头(Response Headers)
3)响应体(Response Body)
前言 什么是协议?就是一种规定,描述了通信双方要按照什么样的格式传输信息。而本文讲解的HTTP 也是协议中的一种。
1、HTTP 介绍 HTTP,全称为“超文本传输协议”,是一种应用非常广泛的 应用层协议!
应用层,很多时候需要程序员自定义应用层协议,也有一些现成的协议,供我们使用,其中 HTTP 就是其中的佼佼者。
我们日常的一些操作其实都涉及到 HTTP协议 运用,比如我们在浏览器打开一个网页,背后浏览器和服务器的交互,大概率使用的就是 HTTP 协议。此外,手机APP和服务器之间的交互、服务器之间的相互调用,也会使用 HTTP 协议,所以 HTTP协议 与我们的生活息息相关。
HTTP 协议是个最典型的 “一问一答”模型的协议!
比如:当我们在浏览器中输入一个 “网址”之后看到一个网页这个过程其实分为三步:
客户端向服务器发送 HTTP 请求 服务器收到后,根据请求,找到客户端想要的资源(一般是html),并把这个资源通过 HTTP响应返回给 浏览器 客户端收到 HTML 之后,对页面进行渲染 以上就是 HTTP 传输信息大致方式,典型的一问一答型。接下来,将重点介绍 HTTP 报文格式,也是我们学习的重点 !!